







最近有点无聊,想研究一下爬虫,说到爬虫,很多人第一时间想到的是python。但是这次我选择了室友@antgan推荐的java爬虫框架WebMagic。该框架容易上手,可定制可扩展,非常适合想用java做爬虫的小伙伴们。先看一下官方教程,里面写得很详细,也有不少参考案例。
暂时还想不到有什么数据值得爬取,先拿csdn博客来练练手。
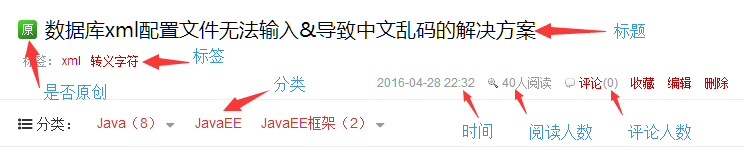
小爬虫能抓取指定用户的所有文章的关键信息,包括文章id,标题,标签,分类,阅读人数,评论人数,是否原创。并且把数据保存到数据库中。

数据库表的设计及sql

CREATE TABLE `csdnblog` (
`key` int(11) unsigned NOT NULL AUTO_INCREMENT,
`id` int(11) unsigned NOT NULL,
`title` varchar(255) NOT NULL,
`date` varchar(16) DEFAULT NULL,
`tags` varchar(255) DEFAULT NULL,
`category` varchar(255) DEFAULT NULL,
`view` int(11) unsigned DEFAULT NULL,
`comments` int(11) unsigned DEFAULT NULL,
`copyright` int(1) unsigned DEFAULT NULL,
PRIMARY KEY (`key`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
Processor是爬虫逻辑,程序的核心
package csdnblog;
import java.util.List;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* CSDN博客爬虫
*
* @describe 可以爬取指定用户的csdn博客所有文章,并保存到数据库中。
* @date 2016-4-30
*
* @author steven
* @csdn qq598535550
* @website lyf.soecode.com
*/
public class CsdnBlogPageProcessor implements PageProcessor {
private static String username = "qq598535550";// 设置csdn用户名
private static int size = 0;// 共抓取到的文章数量
// 抓取网站的相关配置,包括:编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
@Override
public Site getSite() {
return site;
}
@Override
// process是定制爬虫逻辑的核心接口,在这里编写抽取逻辑
public void process(Page page) {
// 列表页
if (!page.getUrl().regex("http://blog\\.csdn\\.net/" + username + "/article/details/\\d+").match()) {
// 添加所有文章页
page.addTargetRequests(page.getHtml().xpath("//div[@id='article_list']").links()// 限定文章列表获取区域
.regex("/" + username + "/article/details/\\d+")
.replace("/" + username + "/", "http://blog.csdn.net/" + username + "/")// 巧用替换给把相对url转换成绝对url
.all());
// 添加其他列表页
page.addTargetRequests(page.getHtml().xpath("//div[@id='papelist']").links()// 限定其他列表页获取区域
.regex("/" + username + "/article/list/\\d+")
. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 802
802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









