







SpringBoot整合ES的简单应用
ES基本概念(大体一看就行)

节点
一个节点是一个ES的实例,在服务器上启动ES之后,就拥有了一个节点,如果在另一个服务器上启动ES,这就是另一个节点。甚至可以在一台服务器上启动多个ES进程,在一台服务器上拥有多个节点。多个节点可以加入同一个集群。
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如下图所示:
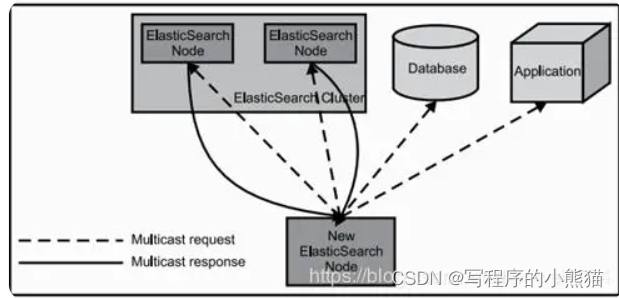
节点主要有3种类型,第一种类型是client_node,主要是起到请求分发的作用,类似路由。第二种类型是master_node,是主的节点,所有的新增,删除,数据分片都是由主节点操作(elasticsearch底层是没有更新数据操作的,上层对外提供的更新实际上是删除了再新增),当然也能承担搜索操作。第三种类型是date_node,该类型的节点只能做搜索操作,具体会分配到哪个date_node,就是由client_node决定,而data_node的数据都是从master_node同步过来的
分片
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,ES提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面的原因:
1、允许你水平分割/扩展你的内容容量
允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由ES管理的,对于作为用户的你来说,这些都是透明的。
2、在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了。这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,ES允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,主要有两方面的原因:
(1)在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
(2)扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制数量,但是不能改变分片的数量。
默认情况下,ES中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。一个索引的多个分片可以存放在集群中的一台主机上,也可以存放在多台主机上,这取决于你的集群机器数量。主分片和复制分片的具体位置是由ES内在的策略所决定的。
插件HEAD
elasticsearch-head是一个界面化的集群操作和管理工具
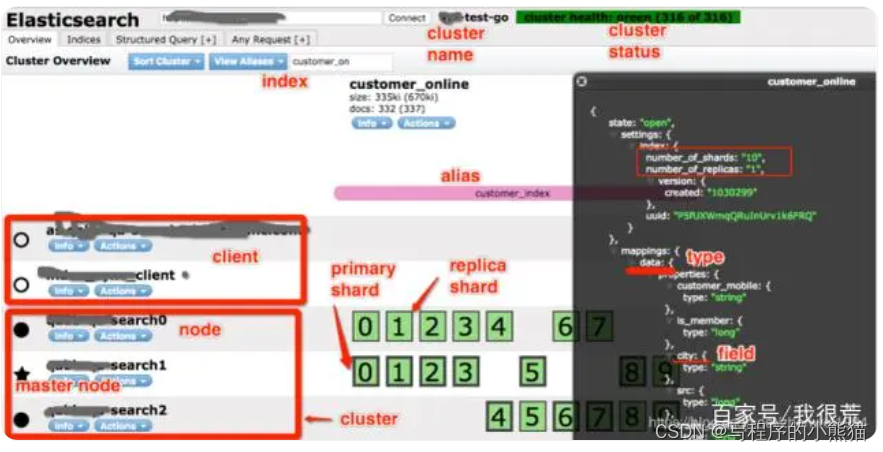
● node:即一个 Elasticsearch 的运行实例,使用多播或单播方式发现 cluster 并加入。
● cluster:包含一个或多个拥有相同集群名称的 node,其中包含一个master node。
● index:类比关系型数据库里的DB,是一个逻辑命名空间。
● alias:可以给 index 添加零个或多个alias,通过 alias 使用index 和根据index name 访问index一样,但是,alias给我们提供了一种切换index的能力,比如重建了index,取名● customer_online_v2,这时,有了alias,我要访问新 index,只需要把 alias 添加到新 index 即可,并把alias从旧的 index 删除。不用修改代码。
● type:类比关系数据库里的Table。其中,一个index可以定义多个type,但一般使用习惯仅配一个type。
● mapping:类比关系型数据库中的 schema 概念,mapping 定义了 index 中的 type。mapping 可以显示的定义,也可以在 document 被索引时自动生成,如果有新的 field,Elasticsearch 会自动推测出 field 的type并加到mapping中。
● document:类比关系数据库里的一行记录(record),document 是 Elasticsearch 里的一个 JSON 对象,包括零个或多个field。
● field:类比关系数据库里的field,每个field 都有自己的字段类型。
● shard:是一个Lucene 实例。Elasticsearch 基于 Lucene,shard 是一个 Lucene 实例,被 Elasticsearch 自动管理。之前提到,index 是一个逻辑命名空间,shard 是具体的物理概念,建索引、查询等都是具体的shard在工作。shard 包括primary shard 和 replica shard,写数据时,先写到primary shard,然后,同步到replica shard,查询时,primary 和 replica 充当相同的作用。replica shard 可以有多份,也可以没有,replica shard的存在有两个作用,一是容灾,如果primary shard 挂了,数据也不会丢失,集群仍然能正常工作;二是提高性能,因为replica 和 primary shard 都能处理查询。另外,如上图右侧红框所示,shard数和replica数都可以设置,但是,shard 数只能在建立index 时设置,后期不能更改,但是,replica 数可以随时更改。但是,由于 Elasticsearch 很友好的封装了这部分,在使用Elasticsearch 的过程中,我们一般仅需要关注 index 即可,不需关注shard。
shard、node、cluster 在物理上构成了 Elasticsearch 集群,field、type、index 在逻辑上构成一个index的基本概念,在使用 Elasticsearch 过程中,我们一般关注到逻辑概念就好,就像我们在使用MySQL 时,我们一般就关注DB Name、Table和schema即可,而不会关注DBA维护了几个MySQL实例、master 和 slave 等怎么部署的一样。
索引原理
字段类型
es字段类型
keyword类型不进行分词
text类型进行分词
添加依赖
springboot版本2.4.6
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
进行配置
import lombok.Data;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.client.ClientConfiguration;
import org.springframework.data.elasticsearch.client.RestClients;
import org.springframework.data.elasticsearch.config.AbstractElasticsearchConfiguration;
@Data
@Configuration
public class ElasticConfig extends AbstractElasticsearchConfiguration {
@Value("${das.elastic.username}")
private String username;
@Value("${das.elastic.password}")
private String password;
@Bean
@Override
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("xxxxx.com:9200")
.withBasicAuth(username, password)
.withSocketTimeout(600000)
.build();
return RestClients.create(clientConfiguration).rest();
}
}
SearchRequest
es查询实例
//在BoolQueryBuilder 对象设置查询条件,以下的逻辑是name=张三 and (title like '%重要%' or content = '程序员')
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
boolQueryBuilder.must(QueryBuilders.termQuery("name", "张三"));
BoolQueryBuilder shouldQuery = new BoolQueryBuilder();
shouldQuery.should(QueryBuilders.wildcardQuery("title", "*重要*"));
shouldQuery.should(QueryBuilders.matchPhraseQuery("content", "程序员"));
boolQueryBuilder.must(shouldQuery);
//在SearchSourceBuilder 对象设置分页/排序/高亮,下面的逻辑是根据创建时间倒序,current为当前页,size为每页条数
SearchSourceBuilder query = new SearchSourceBuilder().query(boolQueryBuilder);
query.sort("createTime", SortOrder.DESC);
query.from((current > 0 ? (current - 1) : 0) *size);
query.size(size);
SearchRequest searchRequest = new SearchRequest(INDEX).source(query);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
QueryBuilders
首先存入一条数据 i like eating and kuing 默认分词器应该将内容分为 “i” “like” “eating” “and” “kuing”
QueryBuilders.matchQuery(“supplierName”,param)
match查询,会将搜索词分词,再与目标查询字段进行匹配,若分词中的任意一个词与目标字段匹配上,则可查询到。有一个分词匹配即匹配
param = “i” 可查出i
param = “i li” 可查出
param = “i like” 可查出
param = “i like eat” 可查出
param = “and” 可查出
param = “kuing” 可查出
param = “ku” 查不出
param = “li” 查不出
param = “eat” 查不出
param = “i like eating and kuing” 查出
分词后精确查询,分词之间or关系,有一个分词匹配即匹配
如果使用 “match”: {“message.keyword”: “xxx”},即不分词只有 i like eating and kuing可以查出
QueryBuilders.matchPhrasePrefixQuery(“supplierName”,param)(了解)
match_phrase_prefix 和 match_phrase 用法是一样的,区别就在于它允许对最后一个词条前缀匹配。
与match_phrase唯一区别 param = “i like eating and kui” 查出
最后一个词条之前的词匹配规则与match_phrase相同++最后一个此条为前缀进行模糊匹配
match_phrase_prefix不能使用supplierName.keyword模式
QueryBuilders.termQuery(“supplierName”,param)
而term query,输入的查询内容是什么,就会按照什么去查询,并不会解析查询内容,对它分词。
param = “i” 可查出i
param = “i li” 查不出
param = “i like” 查不出
param = “i like eat” 查不出
param = “and” 可查出
param = “kuing” 可查出
param = “ku” 查不出
param = “li” 查不出
param = “eat” 查不出
查询条件不分词精确匹配分词数据,命中一个分词即匹配
param = “i like eating and kuing” 查不出
如果使用 “term”: {“message.keyword”: “xxx”},即不分词只有 i like eating and kuing可以查出
QueryBuilders.wildcardQuery(“supplierName”,“*”+param+“*”)
条件wildcard不分词查询,加*(相当于sql中的%)表示模糊查询,加keyword表示查不分词数据
{“wildcard”:{“message.keyword”:“*atin*”} 等同sql于like查询
不能使用supplierName.keyword模式
工具类
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.ElasticsearchException;
import org.elasticsearch.action.DocWriteResponse;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.admin.indices.settings.get.GetSettingsRequest;
import org.elasticsearch.action.admin.indices.settings.get.GetSettingsResponse;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.*;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.reindex.DeleteByQueryRequest;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* ElasticSearch 客户端 RestHighLevelClient Api接口封装
* <p>
* 官方Api地址:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/java-rest-high.html
*
*/
@Slf4j
@Component
public class ElasticSearchRestApiClient {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 默认主分片数
*/
private static final int DEFAULT_SHARDS = 3;
/**
* 默认副本分片数
*/
private static final int DEFAULT_REPLICAS = 2;
/**
* 判断索引是否存在
*
* @param index 索引
* @return 返回 true,表示存在
*/
public boolean existsIndex(String index) {
try {
GetIndexRequest request = new GetIndexRequest(index);
request.local(false);
request.humanReadable(true);
request.includeDefaults(false);
return restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("[ elasticsearch ] >> get index exists exception ,index:{} ", index, e);
throw new ElasticsearchException("[ elasticsearch ] >> get index exists exception {}", e);
}
}
/**
* 创建 ES 索引
*
* @param index 索引
* @param properties 文档属性集合
* @return 返回 true,表示创建成功
*/
public boolean createIndex(String index, Map<String, Object> properties) {
try {
XContentBuilder builder = XContentFactory.jsonBuilder();
// 注:ES 7.x 后的版本中,已经弃用 type
builder.startObject()
.startObject("mappings")
.field("properties", properties)
.endObject()
.startObject("settings")
//分片数
.field("number_of_shards", DEFAULT_SHARDS)
//副本数
.field("number_of_replicas", DEFAULT_REPLICAS)
.endObject()
.endObject();
CreateIndexRequest request = new CreateIndexRequest(index).source(builder);
CreateIndexResponse response = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
return response.isAcknowledged();
} catch (IOException e) {
log.error("[ elasticsearch ] >> createIndex exception ,index:{},properties:{}", index, properties, e);
throw new ElasticsearchException("[ elasticsearch ] >> createIndex exception ");
}
}
/**
* 删除索引
*
* @param index 索引
* @return 返回 true,表示删除成功
*/
public boolean deleteIndex(String index) {
try {
DeleteIndexRequest request = new DeleteIndexRequest(index);
AcknowledgedResponse response = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
return response.isAcknowledged();
} catch (ElasticsearchException e) {
//索引不存在-无需删除
if (e.status() == RestStatus.NOT_FOUND) {
log.error("[ elasticsearch ] >> deleteIndex >> index:{}, Not found ", index, e);
return false;
}
log.error("[ elasticsearch ] >> deleteIndex exception ,index:{}", index, e);
throw new ElasticsearchException("elasticsearch deleteIndex exception ");
} catch (IOException e) {
//其它未知异常
log.error("[ elasticsearch ] >> deleteIndex exception ,index:{}", index, e);
throw new ElasticsearchException("[ elasticsearch ] >> deleteIndex exception {}", e);
}
}
/**
* 获取索引配置
*
* @param index 索引
* @return 返回索引配置内容
*/
public GetSettingsResponse getIndexSetting(String index) {
try {
GetSettingsRequest request = new GetSettingsRequest().indices(index);
return restHighLevelClient.indices().getSettings(request, RequestOptions.DEFAULT);
} catch (IOException e) {
//其它未知异常
log.error("[ elasticsearch ] >> getIndexSetting exception ,index:{}", index, e);
throw new ElasticsearchException("[ elasticsearch ] >> getIndexSetting exception {}", e);
}
}
/**
* 判断文档是否存在
*
* @param index 索引
* @return 返回 true,表示存在
*/
public boolean existsDocument(String index, String id) {
try {
GetRequest request = new GetRequest(index, id);
//禁用获取_source
request.fetchSourceContext(new FetchSourceContext(false));
//禁用获取存储的字段。
request.storedFields("_none_");
return restHighLevelClient.exists(request, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("[ elasticsearch ] >> get document exists exception ,index:{} ", index, e);
throw new ElasticsearchException("[ elasticsearch ] >> get document exists exception {}", e);
}
}
/**
* 保存数据-随机生成数据ID
*
* @param index 索引
* @param dataValue 数据内容
*/
public IndexResponse save(String index, Object dataValue) {
try {
IndexRequest request = new IndexRequest(index);
request.source(JSON.toJSONString(dataValue), XContentType.JSON);
return restHighLevelClient.index(request, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("[ elasticsearch ] >> save exception ,index = {},dataValue={} ,stack={}", index, dataValue, e);
throw new ElasticsearchException("[ elasticsearch ] >> save exception {}", e);
}
}
/**
* 保存文档-自定义数据ID
* <p>
* 如果文档存在,则更新文档;如果文档不存在,则保存文档。
*
* @param index 索引
* @param id 数据ID
* @param dataValue 数据内容
*/
public IndexResponse saveOrUpdate(String index, String id, Object dataValue) {
try {
IndexRequest request = new IndexRequest(index);
request.id(id);
request.source(JSON.toJSONString(dataValue), XContentType.JSON);
return restHighLevelClient.index(request, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("[ elasticsearch ] >> save exception ,index = {},dataValue={} ,stack={}", index, dataValue, e);
throw new ElasticsearchException("[ elasticsearch ] >> save exception {}", e);
}
}
/**
* 根据ID修改
*
* @param index 索引
* @param id 数据ID
* @param dataValue 数据内容
*/
public UpdateResponse updateById(String index, String id, Object dataValue) {
try {
UpdateRequest request = new UpdateRequest(index, id);
request.doc(JSON.toJSONString(dataValue), XContentType.JSON);
return restHighLevelClient.update(request, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("[ elasticsearch ] >> updateById exception ,index = {},dataValue={} ,stack={}", index, dataValue, e);
throw new ElasticsearchException("[ elasticsearch ] >> updateById exception {}", e);
}
}
/**
* 部分修改()
* 注:1).可变更已有字段值,可新增字段,删除字段无效
* 2).若当前ID数据不存在则新增
*
* @param index 索引
* @param id 数据ID
* @param dataValue 数据内容
*/
public UpdateResponse updateByIdSelective(String index, String id, Object dataValue) {
try {
JSONObject jsonObject = JSON.parseObject(JSON.toJSONString(dataValue));
UpdateRequest request = new UpdateRequest(index, id)
.doc(jsonObject)
.upsert(jsonObject);
return restHighLevelClient.update(request, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("[ elasticsearch ] >> updateByIdSelective exception ,index = {},dataValue={} ,stack={}", index, dataValue, e);
throw new ElasticsearchException("[ elasticsearch ] >> updateByIdSelective exception {}", e);
}
}
/**
* 根据id查询
*
* @param index 索引
* @param id 数据ID
* @return T
*/
public <T> T getById(String index, String id, Class<T> clazz) {
GetResponse getResponse = this.getById(index, id);
if (null == getResponse) {
return null;
}
return JSON.parseObject(getResponse.getSourceAsString(), clazz);
}
/**
* 根据id集批量获取数据
*
* @param index 索引
* @param idList 数据ID集
* @return T
*/
public <T> List<T> getByIdList(String index, List<String> idList, Class<T> clazz) {
MultiGetItemResponse[] responses = this.getByIdList(index, idList);
if (null == responses || responses.length == 0) {
return new ArrayList<>(0);
}
List<T> resultList = new ArrayList<>(responses.length);
for (MultiGetItemResponse response : responses) {
GetResponse getResponse = response.getResponse();
if (!getResponse.isExists()) {
continue;
}
resultList.add(JSON.parseObject(getResponse.getSourceAsString(), clazz));
}
return resultList;
}
/**
* 根据多条件查询--分页
* 注:from-size -[ "浅"分页 ]
*
* @param index 索引
* @param pageNo 页码(第几页)
* @param pageSize 页容量- Elasticsearch默认配置单次最大限制10000
*/
public <T> List<T> searchPageByIndex(String index, Integer pageNo, Integer pageSize, Class<T> clazz) {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from((pageNo > 0 ? (pageNo - 1) : 0) * pageSize);
searchSourceBuilder.size(pageSize);
return this.searchByQuery(index, searchSourceBuilder, clazz);
}
/**
* 条件查询
*
* @param index 索引
* @param sourceBuilder 条件查询构建起
* @param <T> 数据类型
* @return T 类型的集合
*/
public <T> List<T> searchByQuery(String index, SearchSourceBuilder sourceBuilder, Class<T> clazz) {
try {
// 构建查询请求
SearchRequest searchRequest = new SearchRequest(index).source(sourceBuilder);
// 获取返回值
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hits = response.getHits().getHits();
if (null == hits || hits.length == 0) {
return new ArrayList<>(0);
}
List<T> resultList = new ArrayList<>(hits.length);
for (SearchHit hit : hits) {
resultList.add(JSON.parseObject(hit.getSourceAsString(), clazz));
}
return resultList;
} catch (ElasticsearchException e) {
//索引不存在
if (e.status() == RestStatus.NOT_FOUND) {
log.error("[ elasticsearch ] >> searchByQuery exception >> index:{}, Not found ", index, e);
return new ArrayList<>(0);
}
throw new ElasticsearchException("[ elasticsearch ] >> searchByQuery exception {}", e);
} catch (IOException e) {
log.error("[ elasticsearch ] >> searchByQuery exception ,index = {},sourceBuilder={} ,stack={}", index, sourceBuilder, e);
throw new ElasticsearchException("[ elasticsearch ] >> searchByQuery exception {}", e);
}
}
/**
* 根据ID删除文档
*
* @param index 索引
* @param id 文档ID
* @return 是否删除成功
*/
public boolean deleteById(String index, String id) {
try {
DeleteRequest request = new DeleteRequest(index, id);
DeleteResponse response = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
//未找到文件
if (response.getResult() == DocWriteResponse.Result.NOT_FOUND) {
log.error("[ elasticsearch ] >> deleteById document is not found , index:{},id:{}", index, id);
return false;
}
return RestStatus.OK.equals(response.status());
} catch (IOException e) {
log.error("[ elasticsearch ] >> deleteById exception ,index:{},id:{} ,stack:{}", index, id, e);
throw new ElasticsearchException("[ elasticsearch ] >> deleteById exception {}", e);
}
}
/**
* 根据查询条件删除文档
*
* @param index 索引
* @param queryBuilder 查询条件构建器
*/
public void deleteByQuery(String index, QueryBuilder queryBuilder) {
try {
DeleteByQueryRequest request = new DeleteByQueryRequest(index).setQuery(queryBuilder);
request.setConflicts("proceed");
restHighLevelClient.deleteByQuery(request, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("[ elasticsearch ] >> deleteByQuery exception ,index = {},queryBuilder={} ,stack={}", index, queryBuilder, e);
throw new ElasticsearchException("[ elasticsearch ] >> deleteByQuery exception {}", e);
}
}
/**
* 根据文档 ID 批量删除文档
*
* @param index 索引
* @param idList 文档 ID 集合
*/
public void deleteByIdList(String index, List<String> idList) {
if (CollectionUtils.isEmpty(idList)) {
return;
}
try {
BulkRequest bulkRequest = new BulkRequest();
idList.forEach(id -> bulkRequest.add(new DeleteRequest(index, id)));
restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("[ elasticsearch ] >> deleteByIdList exception ,index = {},idList={} ,stack={}", index, idList, e);
throw new ElasticsearchException("[ elasticsearch ] >> deleteByIdList exception {}", e);
}
}
/**
* 根据id查询
*
* @param index 索引
* @param id 文档ID
* @return GetResponse
*/
private GetResponse getById(String index, String id) {
try {
GetRequest request = new GetRequest(index, id);
return restHighLevelClient.get(request, RequestOptions.DEFAULT);
} catch (ElasticsearchException e) {
if (e.status() == RestStatus.NOT_FOUND) {
log.error("[ elasticsearch ] >> getById document not found ,index = {},id={} ,stack={}", index, id, e);
return null;
}
throw new ElasticsearchException("[ elasticsearch ] >> getById exception {}", e);
} catch (IOException e) {
log.error("[ elasticsearch ] >> getById exception ,index = {},id={} ,stack={}", index, id, e);
throw new ElasticsearchException("[ elasticsearch ] >> getById exception {}", e);
}
}
/**
* 根据id集-批量获取数据
*
* @param index 索引
* @param idList 数据文档ID集
* @return MultiGetItemResponse[]
*/
private MultiGetItemResponse[] getByIdList(String index, List<String> idList) {
try {
MultiGetRequest request = new MultiGetRequest();
for (String id : idList) {
request.add(new MultiGetRequest.Item(index, id));
}
//同步执行
MultiGetResponse responses = restHighLevelClient.mget(request, RequestOptions.DEFAULT);
return responses.getResponses();
} catch (IOException e) {
log.error("[ elasticsearch ] >> getByIdList exception ,index = {},idList={} ,stack={}", index, idList, e);
throw new ElasticsearchException("[ elasticsearch ] >> getByIdList exception {}", e);
}
}
}














 209
209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









