








贝叶斯定理:
条件概率:
表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。
基本求解公式: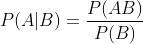
贝叶斯定理: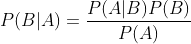
朴素贝叶斯分类:
基于假定:给定目标值时属性之间相互条件独立。
思想基础:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
naiveBayes.py
# 使用朴素贝叶斯分类
def classify(dataSet):
numEntries = len(dataSet)
# 计算出每种类别的数量
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
labelCounts[currentLabel] = labelCounts.get(currentLabel, 0) + 1
# 计算出每个类的先验概率
prob = {}
for key in labelCounts:
prob[key] = float(labelCounts[key]) / numEntries
return prob
# 使用朴素贝叶斯预测
def predict(prob, dataSet, features, newObject):
numFeatures = len(dataSet[0]) - 1
# 计算条件概率
for i in range(numFeatures):
labelValues = [example[-1] for example in dataSet if example[i] == newObject[features[i]]]
labelCounts = {}
for currentLabel in labelValues:
labelCounts[currentLabel] = labelCounts.get(currentLabel, 0) + 1
for val in prob:
prob[val] *= float(labelCounts.get(val, 0)) / len(labelValues)
# 找出最大返回
maxProb = -1.0
for val in prob:
if prob[val] > maxProb:
maxProb = prob[val]
label = val
return label
def main():
# 创建数据集
def createDataSet():
dataSet = [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
features = ['no surfacing', 'flippers']
return dataSet, features
dataset, features = createDataSet()
prob = classify(dataset)
print(predict(prob, dataset, features, {'no surfacing': 1, 'flippers': 1}))
print(predict(prob, dataset, features, {'no surfacing': 1, 'flippers': 0}))
print(predict(prob, dataset, features, {'no surfacing': 0, 'flippers': 1}))
print(predict(prob, dataset, features, {'no surfacing': 0, 'flippers': 0}))
if __name__ == '__main__':
exit(main())
输出结果:
yes
no
no
no















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









