







数据库
库
表
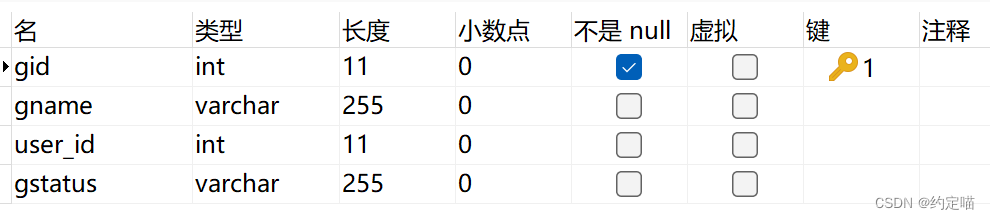
字段
依赖
主要依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>根据实际选择</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<!--使用sharding不能使用druid-spring-boot-starter-->
<!-- <dependency>-->
<!-- <groupId>com.alibaba</groupId>-->
<!-- <artifactId>druid-spring-boot-starter</artifactId>-->
<!-- <version>1.2.11</version>-->
<!-- </dependency>-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.11</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
配置数据源
spring:
shardingsphere:
# 配置数据源,给数据源起名g1,g2...此处可配置多数据源
datasource:
names: g1, g2
g1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/goods_db
username: root
password: root
g2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/goods_db2
username: root
password: root
# 打开sql输出日志
props:
sql:
show: true
分库分表
分表:在实际使用中根据策略分配到同数据库的不同的表中
分库:在实际使用中根据策略分配到不同数据库的中
spring:
shardingsphere:
### 分库分表
# 配置表的分布
sharding:
tables:
# 逻辑表名,sql中查询该表时实施策略,select * from g
g:
# 真实表名,由 数据源名.表名 组成
# g$->{1..2}表示数据源从g1到g2
# goods_$->{1..2}表示数据表从goods_1到goods_2
actual-data-nodes: g$->{1..2}.goods_$->{1..2}
key-generator:
# 指定goods表主键gid 生成策略为 SNOWFLAKE
column: gid
type: SNOWFLAKE
# 配置表策略
table-strategy:
inline:
# 指定分表策略 约定gid值是偶数添加到goods_1表,如果gid奇数添加到tgoods_2表
sharding-column: gid
algorithm-expression: goods_$->{gid % 2 + 1}
# 配置库策略
database-strategy:
inline:
# 根据user_id分库,根据user_id判断奇偶数选择数据源
sharding-column: user_id
algorithm-expression: g$->{user_id % 2 + 1}
使用
使用中除了mapper写法有点区别外,其他类、文件与正常使用一致
mapper
Mapper中主要是xml文件里sql写法不同
原 select * from goods_1 where gid = #{gid} and user_id = #{userId}
先需将表名改为g,即 select * from g where gid = #{gid} and user_id = #{userId}
sharding会自动根据gid和user_id的值进行分库分表
如上文所配时:
当user_id为2,偶数,则会选择g1数据源,即goods_db库
当gid为3,奇数,则会选择goods_2表
则最终会使用goods_db库的goods_2表
读写分离(主从)
有两种,一种是全局,另一种是可针对分表配置主从数据库
全局
使用全局主从也许不能使用分库分表,并且sql中表名不能使用分库分表中的写法
即上文中的 select * from g
spring:
shardingsphere:
masterslave:
#主从数据源
name: ds0
# 主数据源
master-data-source-name: g1
# 从数据源
slave-data-source-names: g2
load-balance-algorithm-type: round_robin
针对分表配置
针对分表策略配置
spring:
shardingsphere:
### 分库分表
sharding:
tables:
g:
# 真实表名,由于是主从策略,因此数据源使用主从数据源,在下文定义
actual-data-nodes: ds0.goods_$->{1..2}
key-generator:
column: gid
type: SNOWFLAKE
table-strategy:
inline:
sharding-column: gid
algorithm-expression: goods_$->{gid % 2 + 1}
master-slave-rules:
# 主从数据源
ds0:
# 主数据源
master-data-source-name: g1
# 从数据源
slave-data-source-names:
- g2
load-balance-algorithm-type: ROUND_ROBIN
# 默认数据源,防止未配置分表的真实表插入时走从表
default-data-source-name: ds0
使用
会自动根据查询还是插入选择不同的数据源
若使用全局,则和正常使用一致
若使用针对分表配置主从,则和分库分表使用一致,可使用分表策略
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









