







问题本质
Q:MySQL的varchar(10)能存多少个汉字?
答案与数据库版本强相关:
- ✅ MySQL 5.0+:可存储10个汉字
- ⚠️ MySQL 4.x:仅能存储3个汉字
实践验证
测试环境
SELECT VERSION(); -- 输出:5.6.16
测试表结构
CREATE TABLE test_table (
id BIGINT(20) NOT NULL,
product_code VARCHAR(10) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
存储测试
-- 成功写入10个汉字
INSERT INTO test_table VALUES(3,'天青色等烟雨而我在等');
-- 失败:尝试写入11个汉字
INSERT INTO test_table VALUES(4,'天青色等烟雨而我在等你');
-- 错误提示:Data too long for column 'product_code'
| 情况 | 输入 | length() | char_length() | 结果 |
|---|---|---|---|---|
| 10个数字 | ‘1234567890’ | 10 | 10 | 写入成功 |
| 11个数字 | ‘12345678901’ | - | - | 写入失败,超长 |
| 10个汉字 | ‘天青色等烟雨而我在等’ | 30 | 10 | 写入成功 |
| 11个汉字 | ‘天青色等烟雨而我在等你’ | - | - | 写入失败,超长 |
验证结果
SELECT
product_code,
LENGTH(product_code) AS byte_length, -- 字节长度
CHAR_LENGTH(product_code) AS char_count -- 字符数量
FROM test_table;
| product_code | byte_length | char_count |
|---|---|---|
| 1234567890 | 10 | 10 |
| 天青色等烟雨而我在等 | 30 | 10 |
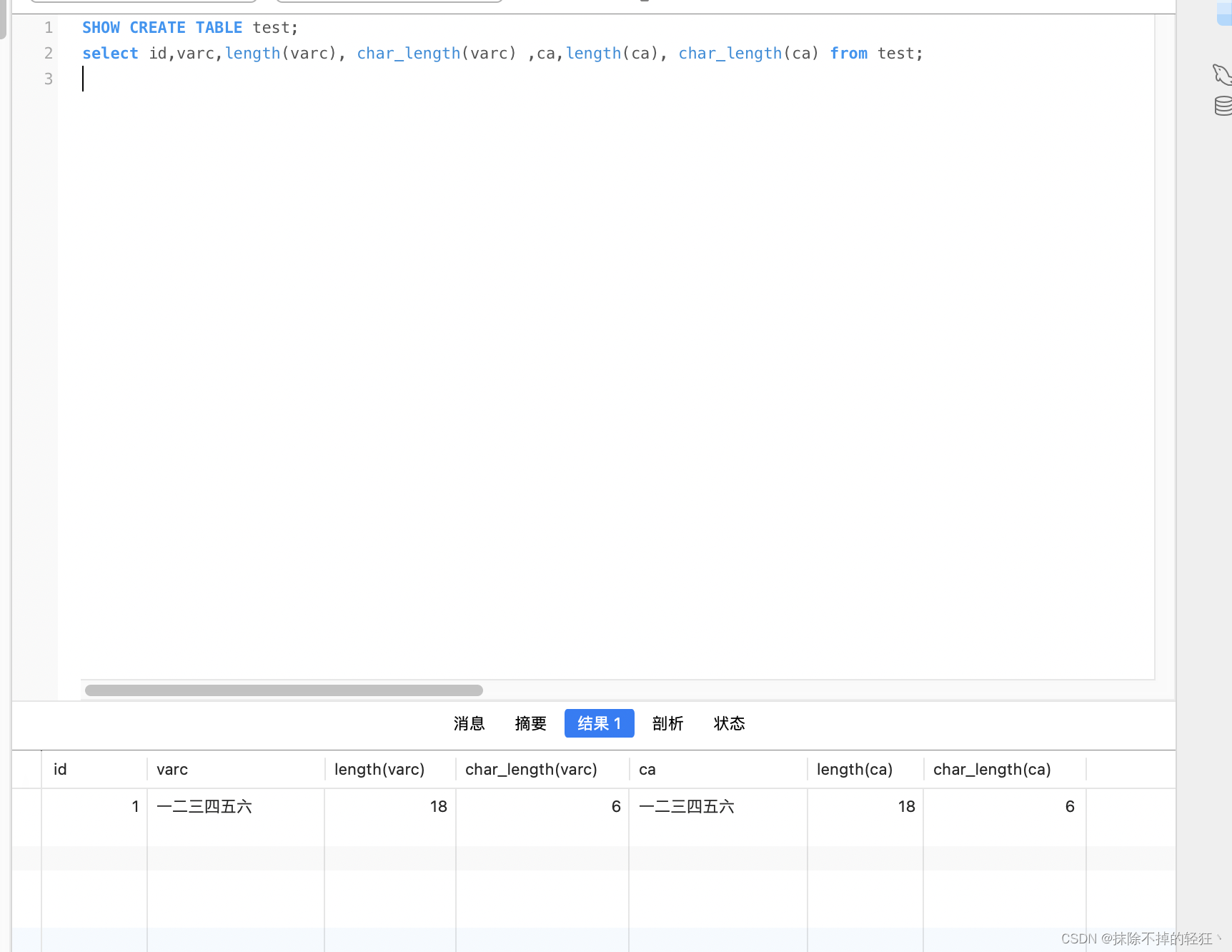
核心原理
版本差异对比
| MySQL版本 | 定义方式 | 存储规则 | 10长度字段汉字容量 |
|---|---|---|---|
| 4.x | 按字节定义 | 每个汉字占3字节(utf8) | 3个(9字节) |
| 5.0+ | 按字符定义 | 每个汉字占1字符位(utf8mb4) | 10个(30字节) |
编码影响分析
| 编码类型 | 每个汉字字节数 | VARCHAR(10)存储量 |
|---|---|---|
| latin1 | 1 | 10个 |
| gbk/gb2312 | 2 | 10个 |
| utf8mb3 | 3 | 10个 |
| utf8mb4 | 3-4 | 10个(常用汉字3字节) |
关键误区纠正
❌ 误区1:varchar长度受字节限制
✅ 事实:
5.0+版本中长度定义是字符数,但最终存储仍需满足行大小总限制。
示例:VARCHAR(10)可存储10个Emoji(需utf8mb4编码),尽管每个Emoji占4字节,但需确保整行数据不超过65535字节。
❌ 误区2:所有汉字占4字节
✅ 事实:
在utf8mb4编码中:
- 常用汉字占3字节(如:‘汉’)
- 仅特殊符号(如Emoji)占4字节(如:‘😊’)
行存储限制与优化
行容量限制
-- 单行所有字段总字节数 ≤ 65535
CREATE TABLE size_test (
content VARCHAR(16383) -- 16383×4=65532字节(接近上限)
) CHARSET=utf8mb4;
多字段计算示例
CREATE TABLE example (
col1 VARCHAR(10000),
col2 VARCHAR(10000)
) CHARSET=utf8mb4; -- 总字节:(10000+10000)*4=80,000 → 超出限制!
最佳实践
-
统一编码:强制使用
utf8mb4ALTER DATABASE db_name CHARACTER SET = utf8mb4; -
版本检查:
mysql --version -
监控工具:
SHOW TABLE STATUS LIKE 'test_table'; -- 查看Data_length字段 -
字段拆分:
当需要存储超过16383字符时,改用TEXT类型:ALTER TABLE test_table ADD COLUMN long_text TEXT;
终极结论
VARCHAR(10)在MySQL 5.0+中理论上可存储10个汉字,但实际存储能力受以下因素制约:
- 字符编码类型(latin1/utf8mb4等)
- 整行数据总字节限制(65,535字节)
- 其他字段的存储消耗
延伸思考:为何MySQL 5.0改为按字符定义?
答案:为简化多语言环境下的开发,让开发者聚焦业务需求而非字节计算。例如:
- 中文系统:无需计算
VARCHAR(10)实际需要30字节 - 日文系统:无需考虑全角/半角字符混合存储


















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











