







前段时间,去试用了下processon 上的脑图功能,发现人家这块确实已经做的好强大了。而且他的节点竟然还可以支持单独某个文本的颜色字体的设置,这个可是连xmind,本身都没有实现的功能的。所以想着学习下人家的实现看看是否能够借鉴到我们的平台上来。
现实很残酷
看了下process on的实现, 发现它跟百度的kityminder差别还是很大的,因为他的每个节点其实都是div的方式实现的,但是百度脑图的节点其实一个个都是svg。 我们可以看下。
ProcessOn
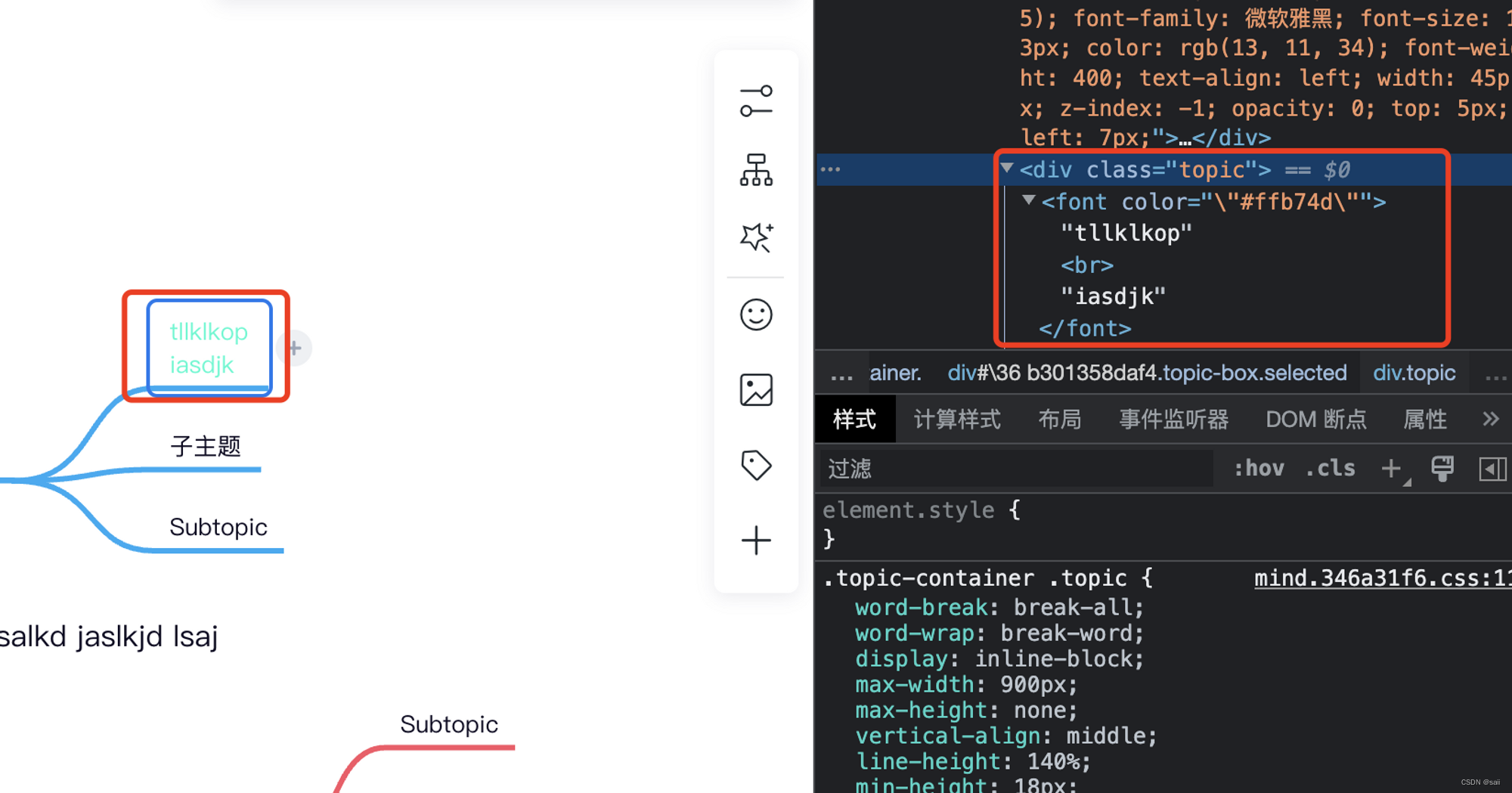
百度脑图

所以这块的参考意义就真的不大了,目前是没有能力去改动到脑图的底层内容的,所以还是只能顺着现有的框架改是最方便快捷的了。
具体变更点
要让原本的antd组件的 TextArea 支持富文本内容是不太可能的,所以我们这里更多还是需要引入一个富文本的组件才可以,这里我们直接就考虑用 braft-editor , 主要是这个组件在我们其他项目中用过,所以用的其实会比较多一些了。
现在我们要考虑一个问题,新的富文本组件需要满足哪些我们特殊的需求,然后我们需要考虑如何进行改造。
这里关键的因素其实就是我们需要做如下的内容 富文本转换后的html的内容,如何让 kityminder-core 识别到并且针对这个文本做相应的颜色标识出来。我们发现富文本转换后的html样式如果带有颜色的情况下基本上这样子的内容: <span style="color:#cccccc">太阳</span>
但是我们需要将这样子的文本内容转换成类似于 <text fill="#cccccc">太阳</text> 这样子的内容。那直接用一些正则替换的方式不就可以了吗?
问题其实那么简单,最关键的一个问题先出来了,我们举个栗子来说明下。
svg的一个文本标签,是默认就进行换行的我们可以看下:
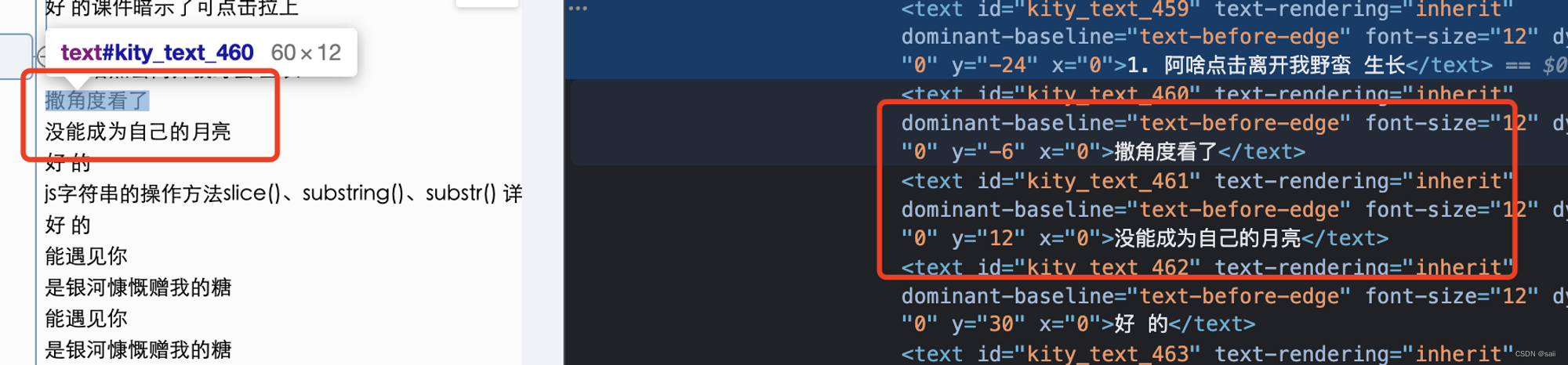
但是如果我们通过富文本进行颜色以后如 下图所示

这样子的一个富文本内容其实应该要放到同一行, 但是对于svg来说由于需要将这两个文本变成两个svg, 同时还要在同一行,这个就是我们需要去解决的问题了。
另外: 替换为富文本的情况还需要满足一下的内容:
- 仅支持文本颜色修改,暂时不支持其他的富文本内容:字体大小,图片,音频等内容。
- 需要响应一些特殊按键操作
- 回车不是换行,而是完成文本输出
- 通过shift+enter进行换行
- 选中文本的时候才显示出工具栏的颜色修改按钮
解决
最重点是要解决富文本内容转换到svg节点的逻辑,这里我们需要改动到的是 text 这块的代码
var textArrTemp = nodeText ? nodeText.split(/\r\n|\n/) : [" "];
// 这里存储包含有富文本的内容
var textArr = [];
for (var index in textArrTemp) {
if (textArrTemp[index].indexOf("<span style") !== -1 || textArrTemp[index].indexOf("</span>") !== -1) {
var newArray = textArrTemp[index].split(/<span\s|<\/span>/)
if (newArray.length > 1) {
newArray = newArray.filter(function (item) {
return item != "";
});
}
for (var i in newArray) {
textArr.push(newArray[i]);
}
} else {
textArr.push(textArrTemp[index]);
}
}
var originTextArr = nodeText ? nodeText.split(/\r\n|\n/) : [" "];
for (var index in originTextArr) {
// 这个是富文本的标签切割了,需要提取出真正的内容出来
if (originTextArr[index].indexOf("<span style") !== -1 || originTextArr[index].indexOf("</span>") !== -1) {
originTextArr[index] = originTextArr[index].replace(/<span style(.*?)>/g, "").replace(/<\/span>/g, "");
}
}
// 这里将带有<span>格式的做过滤将颜色跟实际的文本做一个map存储起来。
for (var i = 0; i < textArr.length; i++) {
if (textArr[i].indexOf("style=") !== -1) {
var m = textArr[i].match(/style="color:(.*?)">/);
var n = textArr[i].match(/>(.*)/);
colorMap[i] = {
color: m[1],
text: n[1]
};
}
}
以上这块就是针对文本的预处理的情况。下来还要到渲染处
return function () {
var isContainOriginText = function (originTextArr, text) {
for (var i in originTextArr) {
if (originTextArr[i].indexOf(text) === 0) {
return true;
}
}
return false
}
var line = 0;
var keys = Object.keys(colorMap);
textGroup.eachItem(function (i, textShape) {
// 这里要判断自己在不在里面 同时要判断我的上一个节点在不在里面
var y;
// 如果这个节点是在colorMap中,说明他是一个颜色标签的, 另外 还需要把颜色标签后面的文本也放到同一行去。
if (i in colorMap && i === 0 || i !== 0 && i - 1 in colorMap && !isContainOriginText(originTextArr, textShape.getContent()) || i !== 0 && i in colorMap && !isContainOriginText(originTextArr, textShape.getContent())) {
y = yStart + i * fontSize * lineHeight;
var lastTextShape = textGroup.getItem(i == 0 ? 0 : i - 1);
var lastBbox = textGroup.getItem(i == 0 ? 0 : i - 1).getBoundaryBox();
textShape.setX(i === 0 ? 0 : lastBbox.width == 0 ? (parseFloat(lastTextShape.getAttr("x")) + 10) : lastBbox.x + lastBbox.width);
textShape.setY(i === 0 ? y : lastBbox.y == 0 ? lastTextShape.getAttr('y') : lastBbox.y);
if (i in colorMap) {
textShape.setAttr("fill", colorMap[i].color);
} else {
textShape.setAttr("fill", "");
}
if (i === 0) {
line++;
}
rBox = rBox.merge(new kity.Box(0, textShape.getY(), textShape.getX() + textShape.getBoundaryBox().width || 1, fontSize));
} else {
y = yStart + line * fontSize * lineHeight;
textShape.setY(y);
textShape.setX(0);
textShape.setAttr("fill", i in colorMap ? colorMap[i].color : "");
var bbox = textShape.getBoundaryBox();
line++;
rBox = rBox.merge(new kity.Box(0, y, bbox.height && bbox.width || 1, fontSize));
}
});
var nBox = new kity.Box(r(rBox.x), r(rBox.y), r(rBox.width), r(rBox.height));
node._currentTextGroupBox = nBox;
return nBox;
};
逻辑有点小复杂了,但是其实就是针对svg做设置颜色,同时需要处理好,如果是富文本且为换行的话,需要通过x, y的属性去设置svg的位置。这样子就可以做到svg在同一行的情况了这里主要 通过上一个box x坐标以及宽度,然后算出当前的svg的box 应该放置的位置的位置
至于富文本其他功能就比较简单了,很多都是通过监听document的事件来满足一些特殊的需求即可了。
重新修改 2023.03.02
重新看了下之前的逻辑,写的很挫,这种逻辑上线以后其实存在很多的bug,所以重新修改了。
我们只有重新理清楚文本分割的逻辑其实就可以了。我们假设我们的富文本内容是这样子的
a<span style="color:#d35400">sd</span>
<span style="color:#003ba5">sad</span>
假设以上就是对应我们编辑好的html, 那我们要确认一个点就是需要有几个svg来承载我们的内容。
答案是3个: 一个是包含了 a, 一个是同一行的sd, 然后是换行的sad。
之前的逻辑考虑是把带有富文本的存放到一个集合里面,针对普通文本,并没有完整的处理,所以这次我们只要用一个对象存储去标识每一个svg的颜色,内容以及是否换行就好了
{
"text": "存储的文本内容",
"color": "该svg的颜色,若无为空",
"newLine": true /false , // 是否换行
}
我们将所有的svg对应配置都放到数组对象中存储,这样子就完美解决了,那关键的问题其实就是如何分割带有样式的文本的内容,以及其他普通文件,这里我们直接看改后的代码吧。
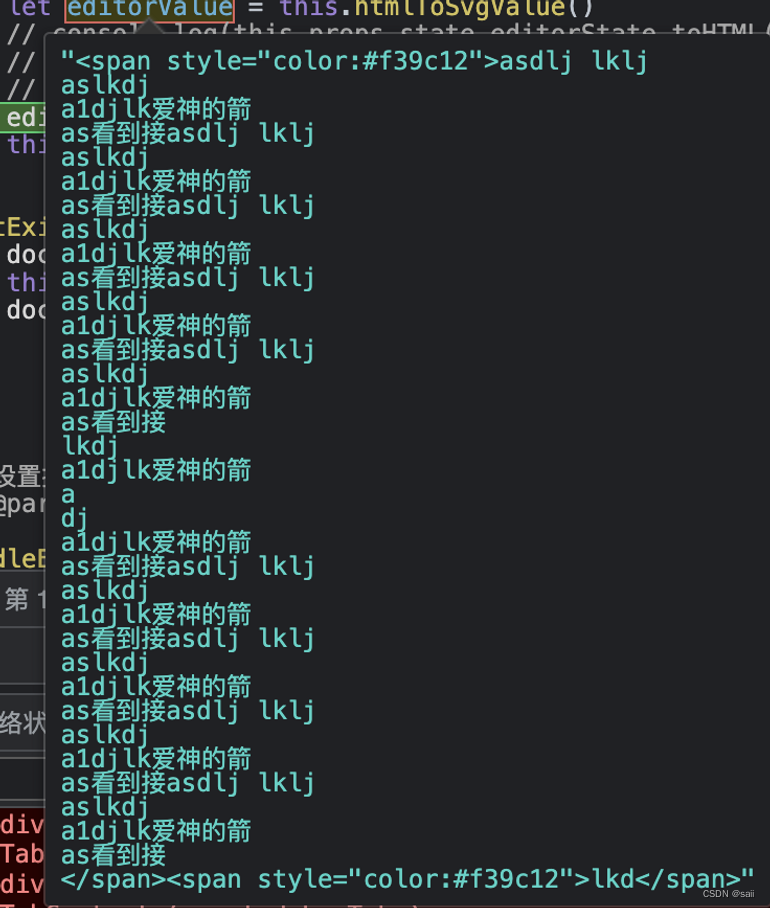
var colors = [];
// 记录span是否已经结束了,因为有可能一些span跨越了多行这个时候 中间有些普通文本他是需要带有颜色的
var lastComplete = true;
// 记录上一次的颜色
var lastColor = '';
for (var index in textArrTemp) {
var currentStr = textArrTemp[index];
// 可以考虑过滤掉这个 如上图所示的,以 </span>结束的其实没啥作用,所以可以直接去掉。
var endSIndex = currentStr.indexOf('</span>')
if (endSIndex == 0) {
currentStr = currentStr.substring(7, currentStr.length);
}
var result = this.opTextStyle(currentStr, colors, true, lastComplete, lastColor);
lastComplete = result[0];
lastColor = result[1];
}
opTextStyle: function(currentStr, colors, newLine, lastComplete, lastColor) {
var sIndex = currentStr.indexOf('<span')
if (sIndex == -1) {
// 这一行都没有样式,但是需要考虑一个问题,他的上一个标志位是否有, 还是上述的图
if (lastComplete) {
// 如果结束了,说明这一行是普通的内容
colors.push({
text: currentStr,
color: '', // 无颜色
newLine: newLine,
})
}else {
colors.push({
text: currentStr,
color: lastColor,
newLine: newLine,
})
}
}else {
// 如果不是开始的位置的情况下
if (sIndex != 0) {
// 开始的位置的内容是普通文本
// 提取开始位置的
colors.push({
text: currentStr.substring(0, sIndex),
color: '',
newLine: newLine
})
currentStr = currentStr.substring(sIndex, currentStr.length);
if (currentStr.length > 0) {
var result = this.opTextStyle(currentStr, colors, false, lastComplete);
lastComplete = result[0];
lastColor = result[1];
}
}else {
// 找到</span>结束的位置在哪
endSIndex = currentStr.indexOf('</span>')
if (endSIndex == -1) {
// 说明这个文本在这一行没有结束
// 匹配文本跟颜色
var n = currentStr.match(/>(.*)/);
var m = currentStr.match(/style="color:(.*?)">/);
colors.push({
text: n[1],
color: m[1],
newLine: newLine
})
// 这一行也结束了
lastColor = m[1];
lastComplete = false;
}else {
// 匹配到的话
var n = currentStr.match(/>(.*?)<\/span>/);
var m = currentStr.match(/style="color:(.*?)">/);
colors.push({
text: n[1],
color: m[1],
newLine: newLine
})
lastComplete = true;
// 还没结束 还要继续处理
// 提取出新的文本内容
currentStr = currentStr.substring(endSIndex + 7, currentStr.length);
if (currentStr.length > 0) {
var result = this.opTextStyle(currentStr, colors, false, lastComplete);
lastComplete = result[0];
lastColor = result[1];
}
}
}
}
return [lastComplete, lastColor];
},
通过以上的逻辑就可以把富文本都放到一个数组对象里面去了。
再然后就是渲染的事情了。
textGroup.eachItem(function (i, textShape) {
// 这里要判断自己在不在里面 同时要判断我的上一个节点在不在里面
var y;
if (!colors[i].newLine) {
y = yStart + line * fontSize * lineHeight;
var lastTextShape = textGroup.getItem(i - 1);
var lastBbox = textGroup.getItem(i - 1).getBoundaryBox();
textShape.setX(lastBbox.width == 0 ? parseFloat(lastTextShape.getAttr("x")) + 10 : lastBbox.x + lastBbox.width);
textShape.setY(lastBbox.y == 0 ? lastTextShape.getAttr("y") : lastBbox.y);
textShape.setAttr("fill", colors[i].color);
rBox = rBox.merge(new kity.Box(0, textShape.getY(), textShape.getX() + textShape.getBoundaryBox().width || 1, fontSize));
} else {
line++;
y = yStart + (line -1) * fontSize * lineHeight;
textShape.setY(y);
textShape.setX(0);
textShape.setAttr("fill", colors[i].color);
var bbox = textShape.getBoundaryBox();
rBox = rBox.merge(new kity.Box(0, y, bbox.height && bbox.width || 1, fontSize));
}
});
















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









