







背景
今天TOP100全球软件案例研究峰会结束,同事共享了会上的一些ppt,同时,top100的公众号也共享了ppt出来。那么这个时候问题来了,我不太想在线去看这些ppt,我想将这些图片都下载下来查看,可以吗?答案当然是可以的啦。我们还是采用比较简单的python来实现吧
分析
首先我们看看top100页面的情况:
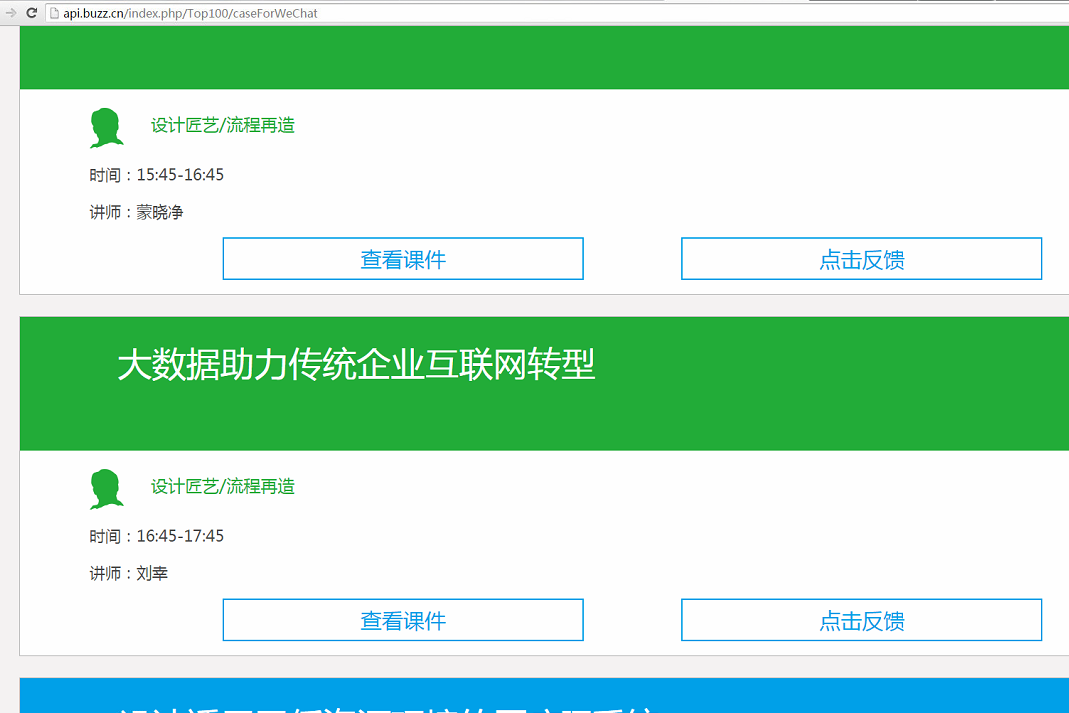
点击查看课件按钮以后就可以进入到ppt详情页面了。我们看看查看课件这个按钮的源代码

发现有一个paikeid以及一个courseid,其实在看看下面的js代码就可以知道这两个值就是用来进入ppt详情页的值了。
$(".coursebutton").click(function(){
var courseid = $(this).attr('courseid');
var paikeid = $(this).attr('paikeid');
window.location = '/index.php/Mpd/course?courseid='+courseid+"&paikeid="+paikeid;
});以上的代码就不难看出了,下来我们看看ppt详情页的情况吧。
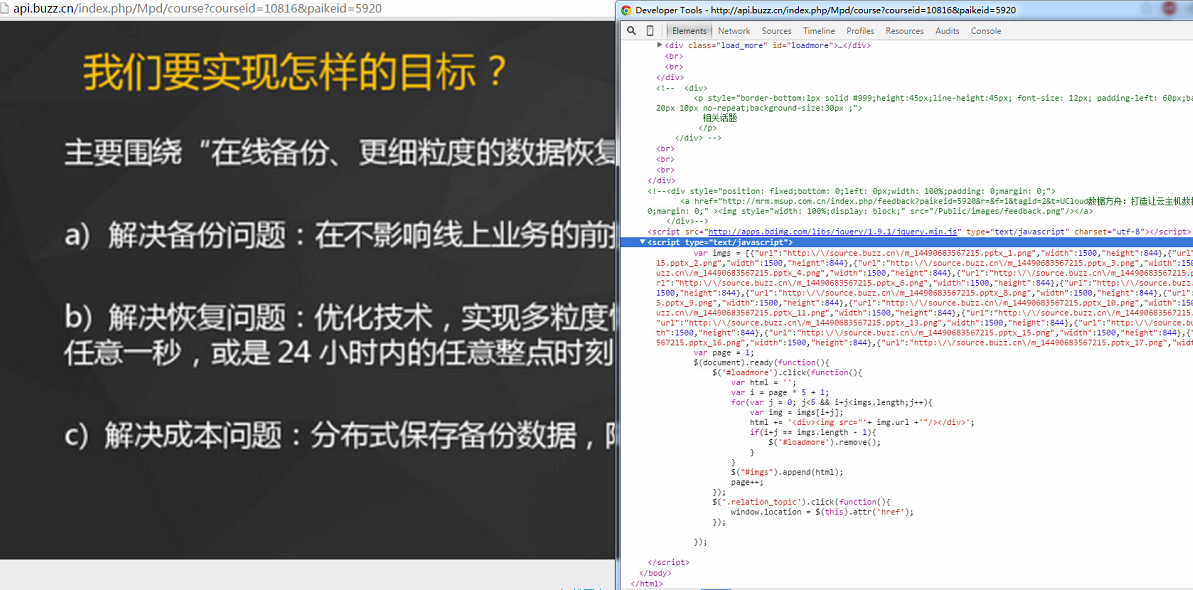
这个还有一个比较难的地方以为,图片并不是一次行加载出来,而是需要点击加载更多以后才会显示。那有什么好的方法吗?有的。我们发现上图中图片在javascript代码中也存在,那么我们完成可以通过正则表达式过滤出第一张,并且图片的名称都是有规律的。这对我们请求对图片更是有帮助了。虽然我们还是不能解决图片有多少张,但是我们可以尝试去请求。只要http请求异常我们就当做是ppt的最后一张图片了。分析这么多,那就开始实现吧。
实现
这里我们就直接贴源代码吧
# -*- coding: utf-8 -*-
from myhttp import MyHttpRequest
from bs4 import BeautifulSoup
import re,os
base_url = "http://api.buzz.cn/index.php/Top100/caseForWeChat"
course_detail_url = "http://api.buzz.cn/index.php/Mpd/course?courseid=COURSE&paikeid=PAIKEID"
image_url = "http://source.buzz.cn/m_KEY_NUM.png"
#MyHttpRequest是自己封装的一个http请求
http_request = MyHttpRequest()
page_content = http_request.get_response(base_url).read().decode('utf-8')
soup = BeautifulSoup(page_content)
#这里是获取到课程标题的列表,但是这里返回的不是一个list注意下就可以
course_titles = soup.find_all('h2')
#遍历所有的课程按钮
for i,course in enumerate(soup.find_all(class_="coursebutton")):
course_soup = BeautifulSoup(str(course))
course_detail_item_url = course_detail_url.replace('COURSE',course_soup.a['courseid'])
course_detail_item_url = course_detail_item_url.replace('PAIKEID',course_soup.a['paikeid'])
#print course_detail_item_url
page_content = http_request.get_response(course_detail_item_url).read().decode('utf-8')
#使用正则过滤出图片的名称
p = re.compile(r'm_(.*?)_(.*?)\.png')
course_id = p.findall(page_content)[0][0]
image_key_url = image_url.replace('KEY',course_id)
dir_name = course_titles[i].string
for i in range(1,100):
#以课题的名称作为生成的目录,并在目录下下载图片,其实这个目录的判断应该放在for循环外面。
if not os.path.exists(dir_name):
os.mkdir(dir_name)
image_item_url = image_key_url.replace('NUM',str(i))
try:
image_content = http_request.get_response(image_item_url).read()
except:
break
image_file = open('./'+dir_name+'/'+course_id+'_'+str(i)+'.png','wb')
image_file.write(image_content)
结束语
以上就是基本的实现了,其实还是挺简单的。谨记!多学习多动手。















 5188
5188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









