









在Elasticsearch中进行深度分页操作是一种常见的需求,但是如果使用传统的分页方式会比较耗时,可能会导致性能问题。为了解决这个问题,Elasticsearch提供了一些深度分页方案,主要包括以下几种:
使用from和size参数
Elasticsearch的from和size参数可以用于实现分页查询,其中from参数表示起始偏移量,size参数表示每页显示的记录数。例如,要查询第11-20条记录,可以使用如下查询语句:
GET /my_index/_search
{
"from": 10,
"size": 10,
"query": {
"match": {
"field": "value"
}
}
}
这种方式的缺点是,当数据量很大时,每次查询都需要扫描所有的文档,效率比较低。
scroll API
Elasticsearch的scroll API可以用于实现深度分页操作,该API会在服务器端创建一个数据快照,并返回一个唯一的ID。客户端可以使用该ID多次检索数据,直到检索完成。例如,要查询第11-20条记录,可以使用如下查询语句:
POST /my_index/_search?scroll=1m
{
"size": 10,
"query": {
"match": {
"field": "value"
}
}
}
其中,scroll参数表示检索数据的时间间隔,1m表示1分钟。该API会返回一个scroll_id,客户端可以使用该ID多次调用scroll API进行检索,直到所有数据都检索完成。例如,要继续查询下一页数据,可以使用如下查询语句:
POST /_search/scroll
{
"scroll": "1m",
"scroll_id": "scroll_id"
}
这种方式的缺点是,需要在服务器端维护一个数据快照,如果数据量很大,可能会导致内存占用过高。
使用scroll和slice结合方式
该方式是结合scroll API和slice操作,先使用slice操作将数据分片,然后再使用scroll API进行深度分页操作。例如,要查询第11-20条记录,可以使用如下查询语句:
POST /my_index/_search?scroll=1m
{
"slice": {
"id": 0,
"max": 3
},
"size": 10,
"query": {
"match": {
"field": "value"
}
}
}
其中,slice参数表示将数据分为3个片段,本次检索操作只检索第一个片段。客户端可以使用该方式多次调用scroll API进行检索,直到所有数据都检索完成。例如,要继续查询下一页数据,可以使用如下查询语句:
POST /_search/scroll
{
"scroll": "1m",
"scroll_id": "scroll_id"
}
这种方式的缺点是,需要先将数据分片,然后再使用scroll API进行检索,比较复杂。但是,相对于单纯的scroll API操作,可以有效地降低内存占用。
search_after参数
Elasticsearch的search_after参数可以用于实现深度分页操作,该参数会将上一页的最后一条记录作为本次检索的起始点。例如,要查询第11-20条记录,可以使用如下查询语句:
GET /my_index/_search
{
"size": 10,
"sort": [
{ "field": "asc" }
],
"query": {
"match": {
"field": "value"
}
},
"search_after": [ "last_value" ]
}
其中,sort参数表示排序方式,search_after参数表示上一页的最后一条记录的值。客户端可以使用该方式多次检索数据,直到检索完成。例如,要查询下一页数据,可以使用如下查询语句:
GET /my_index/_search
{
"size": 10,
"sort": [
{ "field": "asc" }
],
"query": {
"match": {
"field": "value"
}
},
"search_after": [ "last_value_of_current_page" ]
}
这种方式的缺点是,必须要先进行一次排序操作,然后再使用search_after参数进行分页查询。如果数据量很大,排序操作可能会比较耗时。
总结
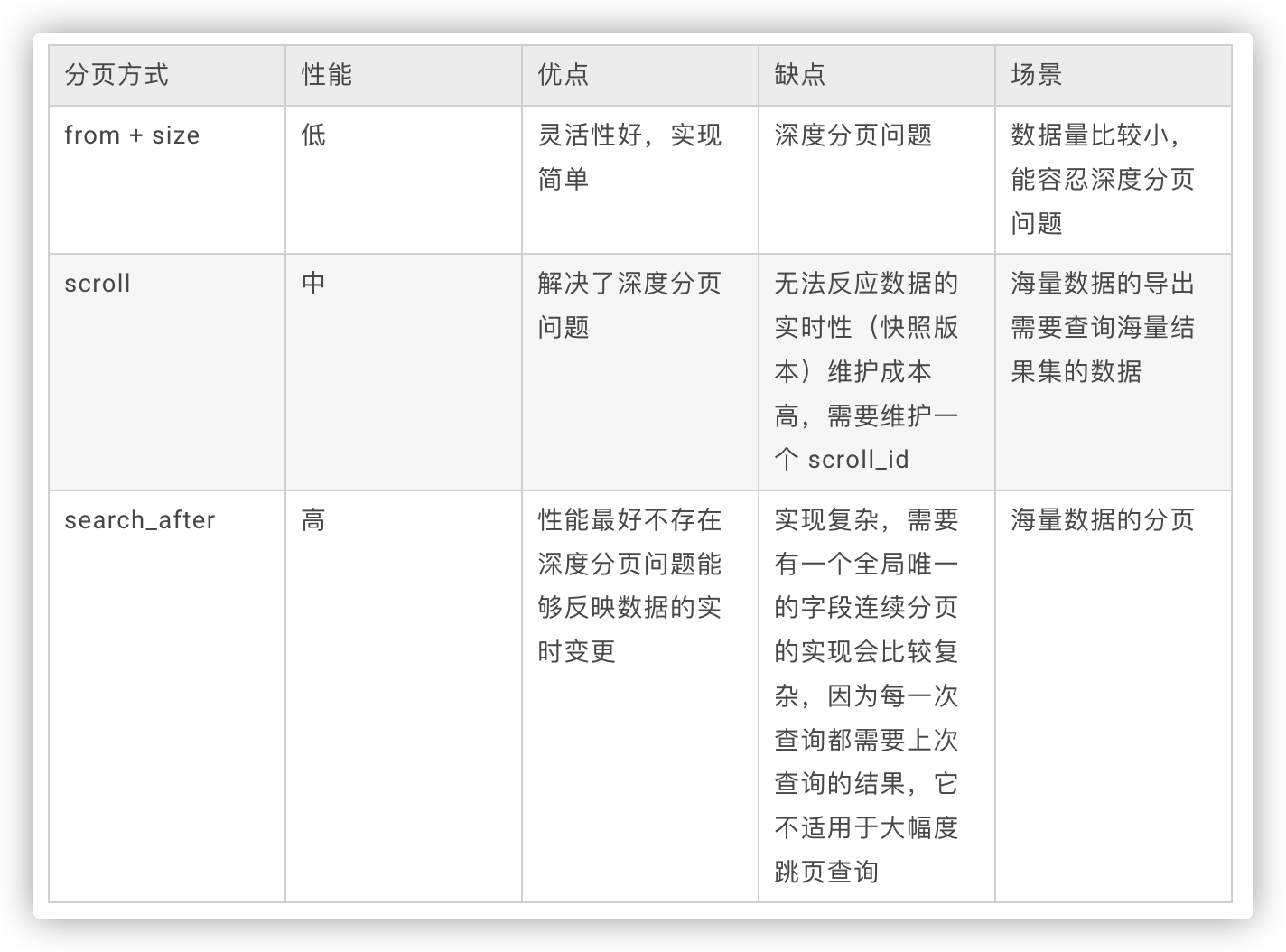
- 如果数据量小(from+size在10000条内),或者只关注结果集的TopN数据,可以使用from/size 分页,简单粗暴
- 数据量大,深度翻页,后台批处理任务(数据迁移)之类的任务,使用 scroll 方式
- 数据量大,深度翻页,用户实时、高并发查询需求,使用 search after 方式,Search_After本身就是一种业务折中方案,它不允许指定跳转到页面,而只提供下一页的功能。
ES7版本变更
参照:https://www.elastic.co/guide/en/elasticsearch/reference/master/paginate-search-results.html#scroll-search-results
在7.*版本中,ES官方不再推荐使用Scroll方法来进行深分页,而是推荐使用带PIT的search_after来进行查询;
从7.*版本开始,您可以使用SEARCH_AFTER参数通过上一页中的一组排序值检索下一页命中。
使用SEARCH_AFTER需要多个具有相同查询和排序值的搜索请求。
如果这些请求之间发生刷新,则结果的顺序可能会更改,从而导致页面之间的结果不一致。
为防止出现这种情况,您可以创建一个时间点(PIT)来在搜索过程中保留当前索引状态。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









