







持续更新中~~
第1章 HDFS架构设计
1.1.HDFS架构概述
HDFS解决的是海量数据的存储问题,在HDFS出现以前,数据存储采用的是集中式存储,即存储在单台计算机服务器之上,扩大存储资源则是加磁盘。HDFS则另辟蹊径,采用分布式存储,将文件切分,然后分开存储在多台廉价的服务器之上,扩大存在资源则是增加廉价机器即可,理论上让存储资源变得无上限。
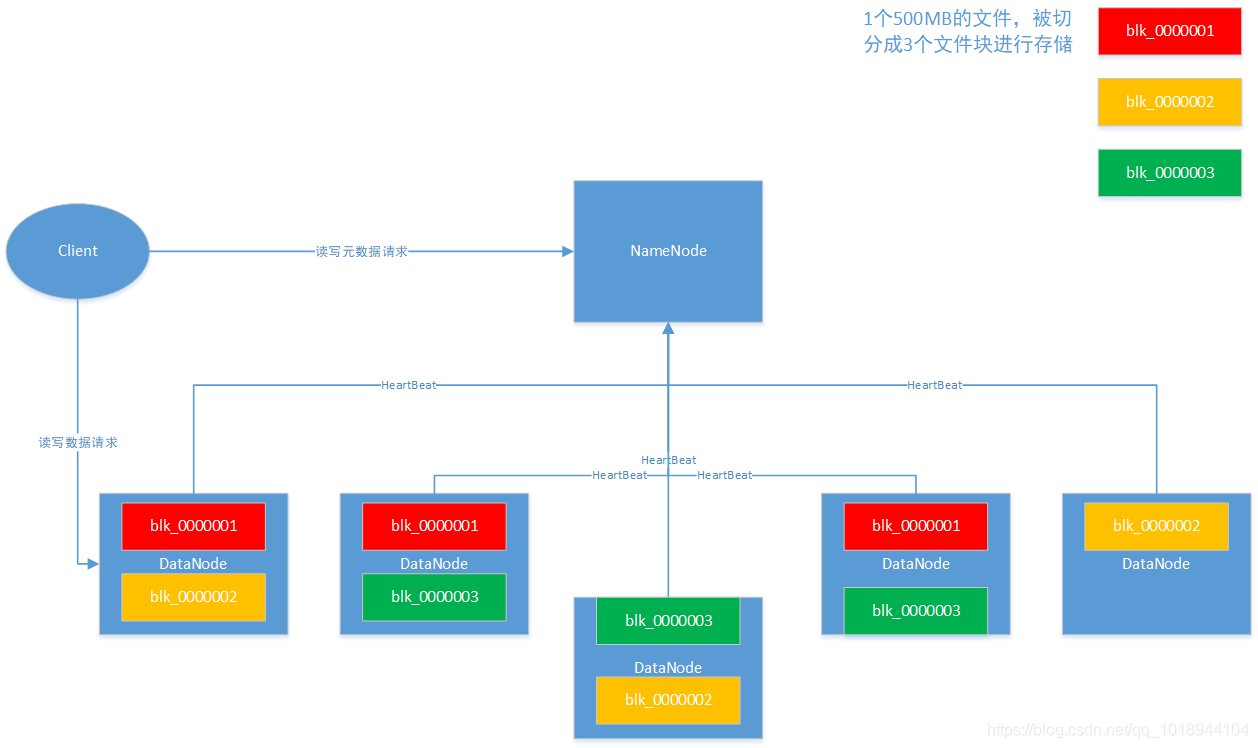
HDFS是主从架构,主节点称为namenode,负责元数据目录树的管理,响应客户端元数据读写请求,接受从节点datanode的注册和心跳;从节点datanode,负责存储、读写数据,向namenode报告自身状况。
主从式架构实现简单,能够解决海量数据的存储问题,很多大数据技术采用的都是主从式架构,比如HBase、Yarn、MapReduce、Spark、Flink等,其本质思想索引,用小资源管理大体量。
HDFS架构图如下:
1.2.HDFS架构存在的问题
值得一提,为了保证NameNode高并发,在NameNode的内存里面是存储了一份完整的元数据镜像,在HDFS集群正常运行过程中,对于元数据的读写操作都基于内存进行的。
一方面,管理元数据的NameNode存在单点故障问题;另一方面,随着HDFS存储数据量的增加,NameNode元数据量也随之增加,NameNode存储元数据所需的内存是受限的。
接下来,我们便是讨论解决这两个问题的架构解决方案。
1.3.单点故障的架构解决方案
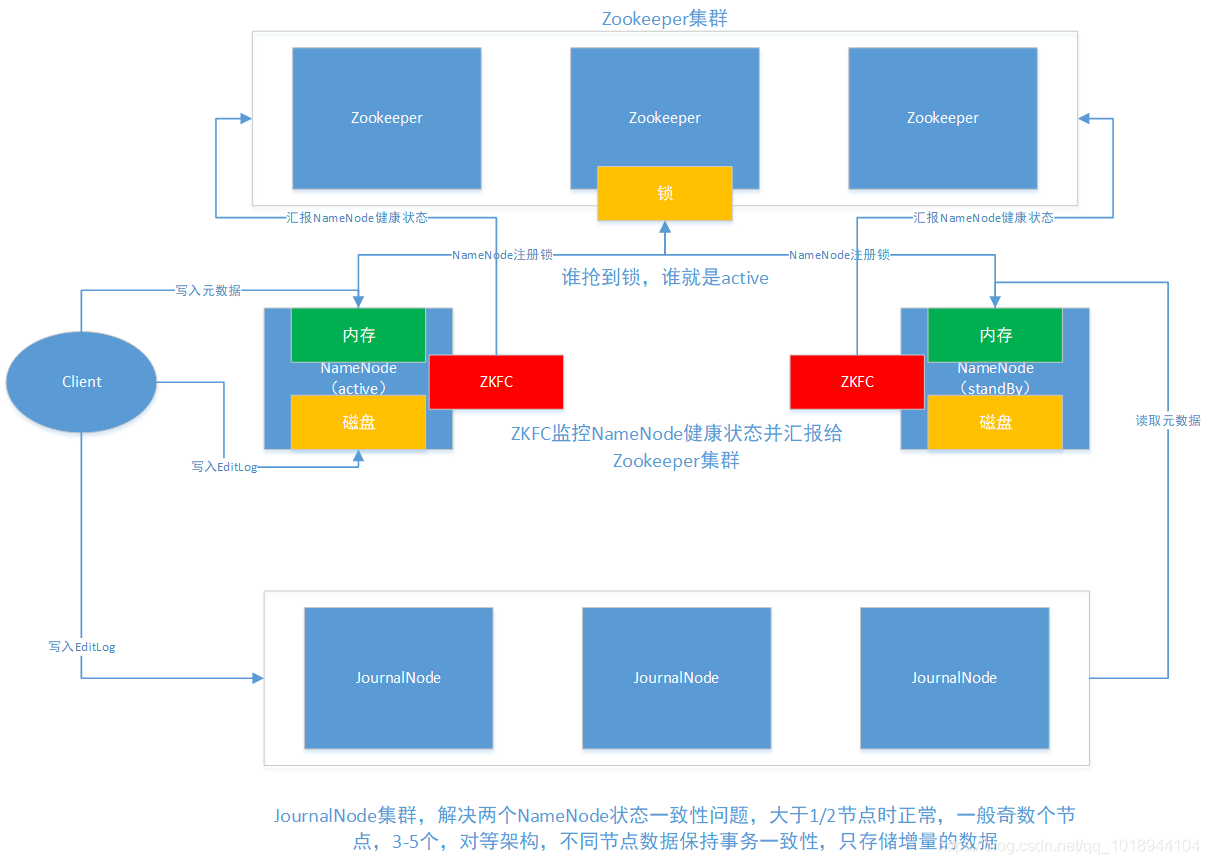
解决单点故障最直接的方法就是变单点为两点,甚至多点。HDFS采取的方案是变单点为两点,将NameNode分为Active和StandBy两种类型,其中只有Active NameNode对外提供服务。
要实现这种方案,需要解决两个棘手的问题,其一,两个NameNode需状态保持一致;其二,当Active NameNode出现异常时,切换到StandBy NameNode并把状态改为Active NameNode。
架构图如下:
1.4.内存受限的架构解决方案
我们知道,为了快速响应客户端请求,NameNode将元数据存储在内存中,但是机器的内存始终有限,随着HDFS机器存储数据量的增加,NameNode内存大小将会成为瓶颈。
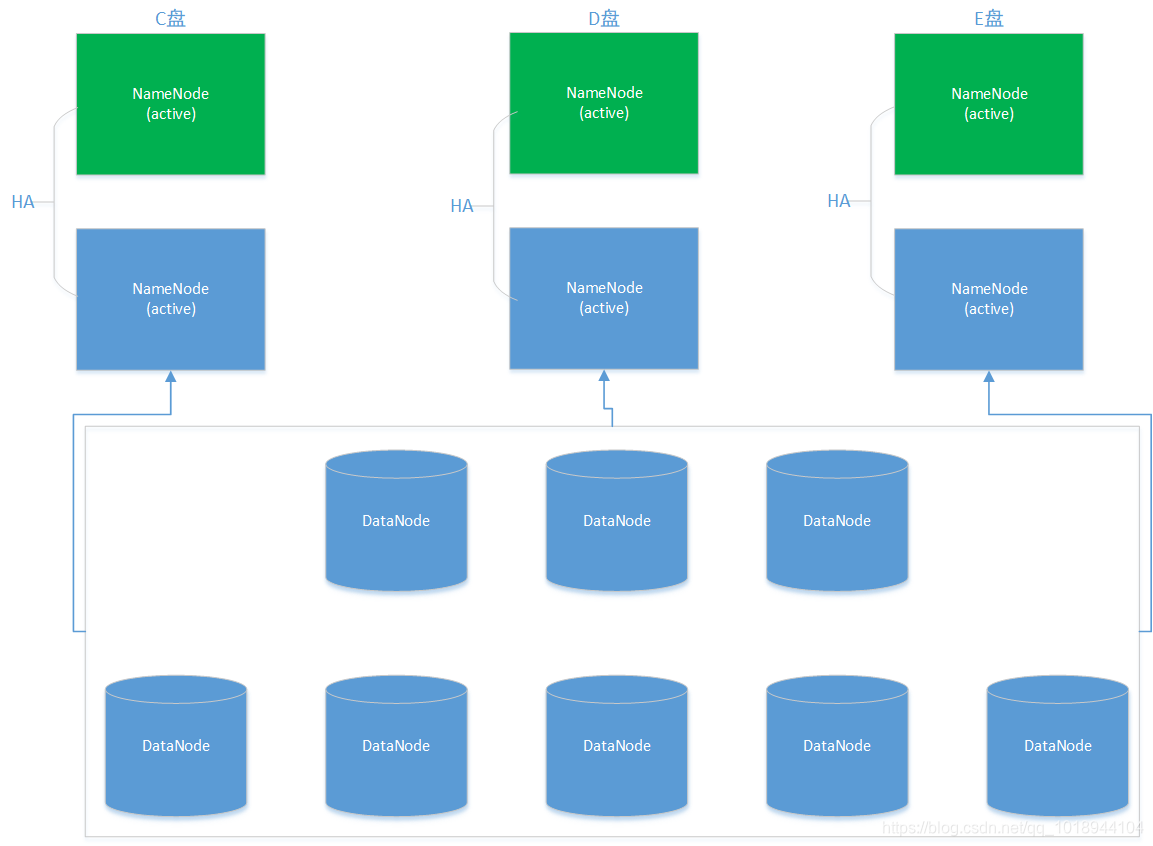
解决NameNode内存受限的思路是将元数据切分并存储到不同的NameNode节点之上,抽象一下就是对元数据也进行切片备份。切片是指将元数据切分成多分,放到不同的NameNode节点之上;备份是指NameNode的高可用方案。
HDFS解决NameNode内存受限采用的就是此方案,被称为联邦模式,架构图如下:
最佳实践,一般1000台节点,采用HA高可用方案足以。1000台以上,如果HA不满足需求,则可以考虑联邦架构方案。
1.5.HDFS支持亿级流量的秘密
为什么说HDFS支持亿级流量呢?用户所有的请求都要操作NameNode管理的元数据,大一点的平台每天的调度任务有几十万,甚至上百万个,每个任务又有多个请求。
为了支持亿级流量,HDFS的元数据处理流程采用了双缓存方案,利用了服务器写内存的高性能以及批量顺序写磁盘的高性能。
1.6.HDFS元数据管理流程
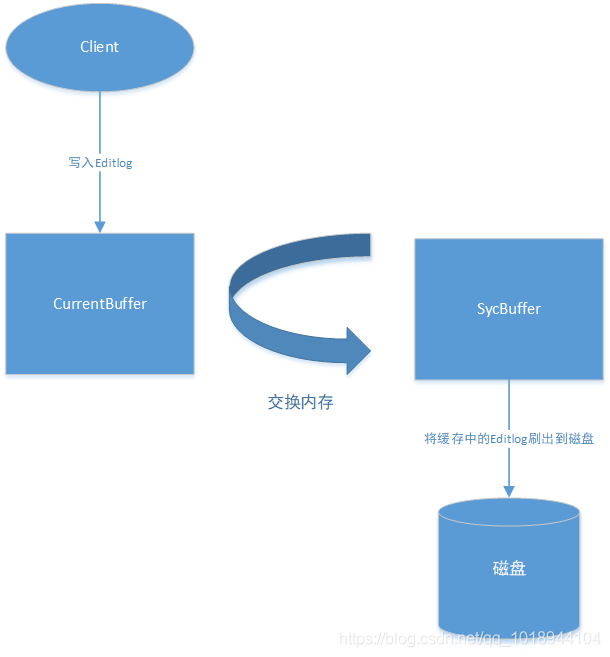
我们知道内存中的数据易丢失,因此自然会想到把元数据操作日志Editlog存储到磁盘上,此外NameNode还会将元数据操作日志Editlog写到JournalNode集群。
一旦涉及到写磁盘,那就意味着慢,在NameNode需要抗住亿级流量的背景下,直接写磁盘的方式显然是不可取的。
因此,HDFS采取了双缓冲方案来解决这个问题,将直接写磁盘的操作转化为写内存和批量刷写磁盘的操作,双缓冲架构图如下:
1.7.HDFS1和HDFS2元数据合并机制
为什么会进行元数据合并?我们知道内存中的元数据安全性得不到保障,一旦遇到服务故障或机器故障,就会导致内存中的元数据丢失。因此,NameNode在把元数据写入内存的同时,会把元数据的操作日志写入到磁盘,以便在内存元数据丢失的情况下依然能够恢复出完整的元数据。因此,这就产生了元数据的合并的场景。
什么时候会进行元数据合并?HDFS集群启动的时候,NameNode会对Editlog中的操作日志进行回放,从而生成最新的元数据。但是,如果Editlog操作日志量太大,就会导致集群启动缓慢,因此,HDFS引入了CheckPoint机制,定期对元数据进行合并,从而减少集群启动是合并元数据所需的时间。
在HDFS1中是通过SecondaryNameNode节点实现checkpoint机制的,架构图如下:
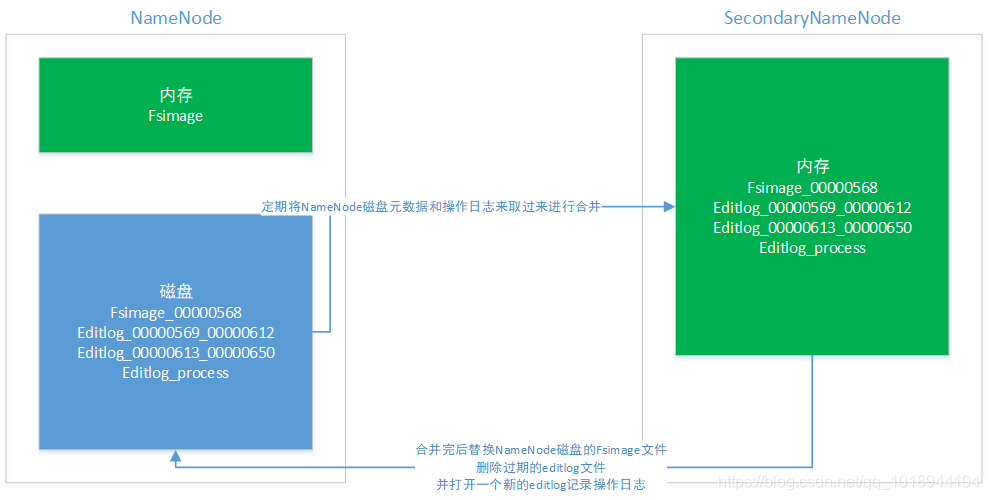
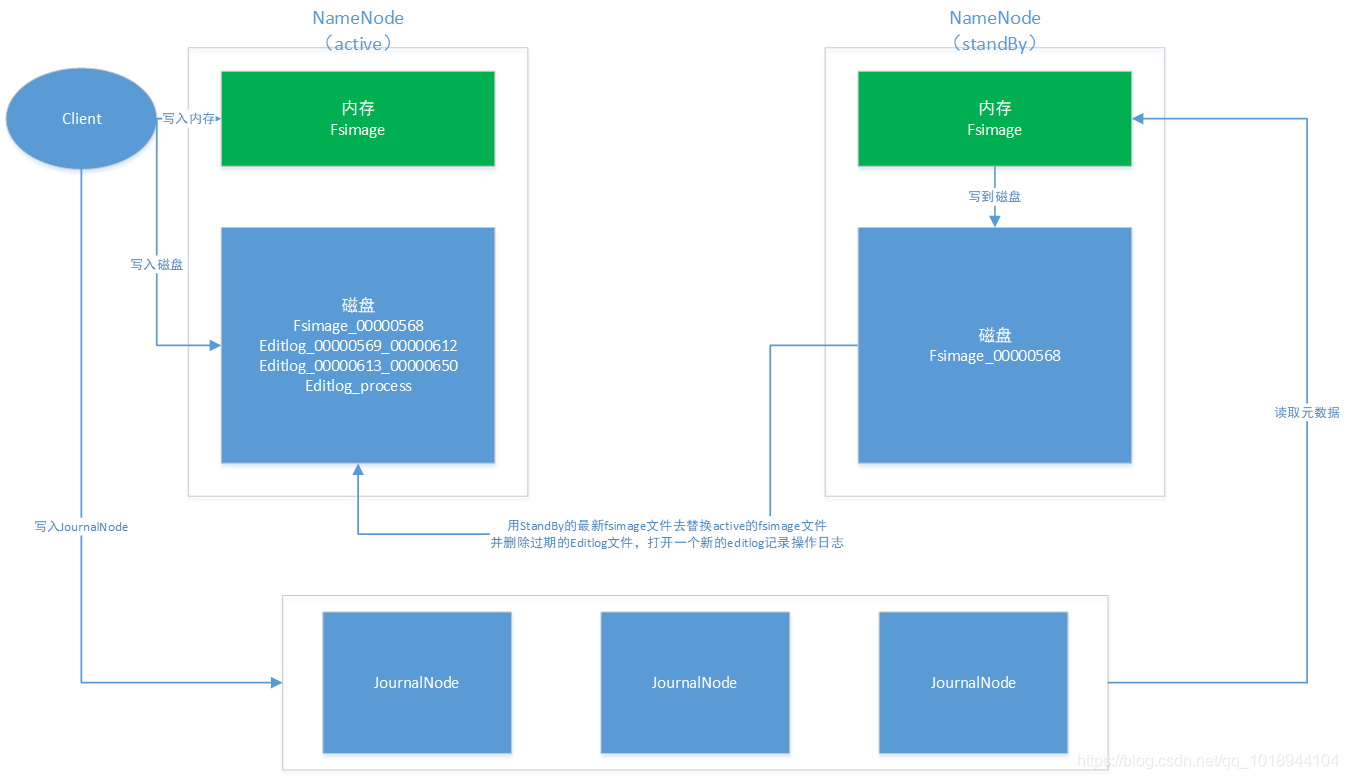
在HDFS2中由于存在standBy NameNode,因此定期合并元数据的操作并转移到此节点上,架构图如下:














 61
61











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









