









收藏关注不迷路!!
🌟文末获取源码+数据库🌟
感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
前言
基于Python的网易新闻舆论情感分析可视化是一个复杂但功能强大的项目,它结合了数据抓取、自然语言处理(NLP)、情感分析和数据可视化等多个领域的技术。以下是对该项目的详细介绍:
一、项目背景与目的
随着互联网的快速发展,新闻网站成为公众获取信息的重要渠道。网易新闻作为国内知名的新闻网站,其上的新闻内容对公众舆论具有重要影响。通过对网易新闻进行情感分析,可以了解公众对某些事件或话题的态度和情感倾向,从而为相关决策提供参考。
详细视频演示
文章底部名片,联系我看更详细的演示视频
一、项目介绍
开发语言:Python
python框架:Django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
前端框架:vue.js
二、功能介绍
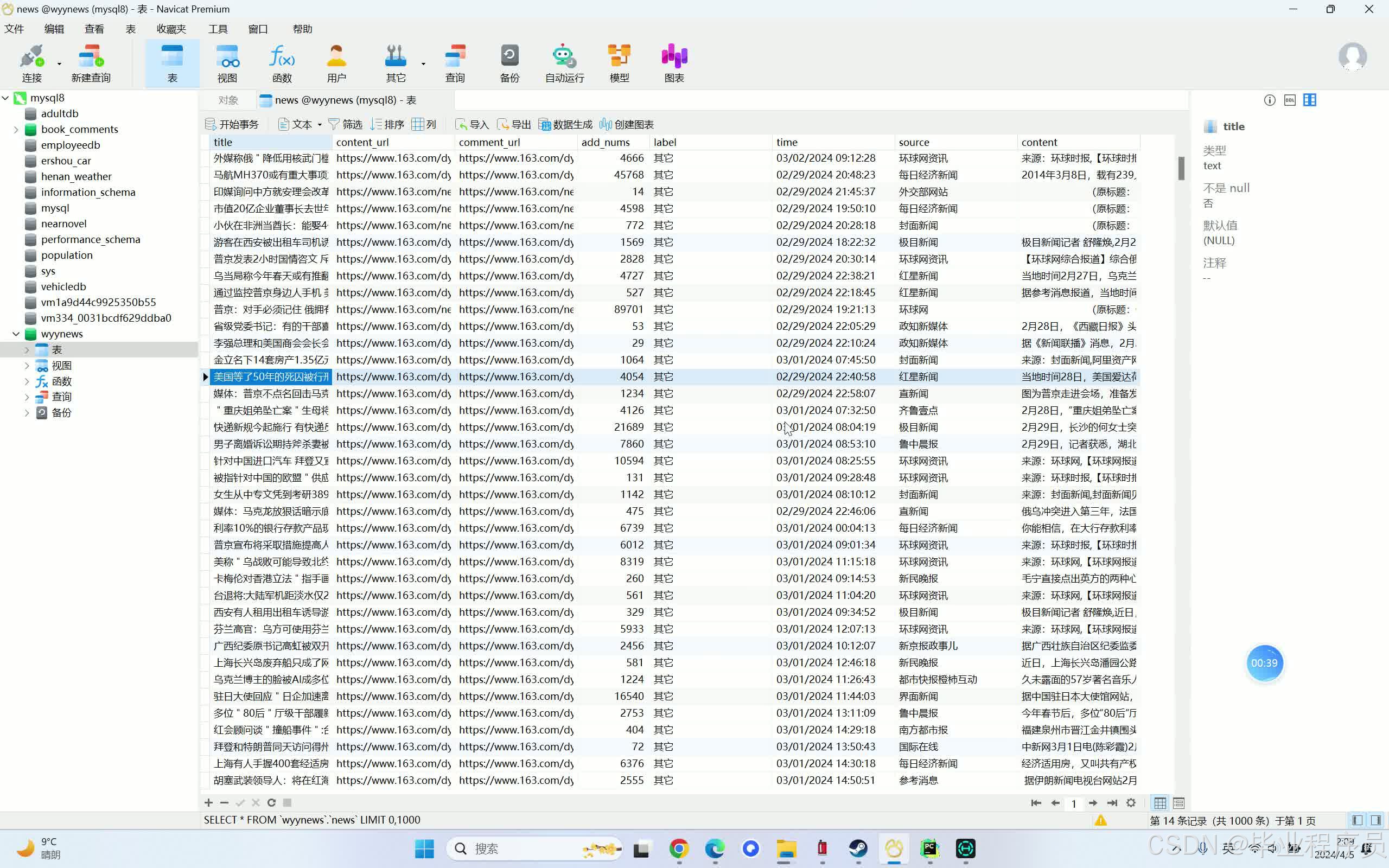
数据抓取:使用Python的Scrapy框架或requests库,从网易新闻网站抓取新闻内容。这些内容包括新闻标题、正文、发布时间等。
数据预处理:对抓取到的新闻内容进行清洗,去除空格、换行符等干扰信息,并保存到本地文件或数据库中。
中文分词与词频统计:利用jieba分词库对新闻内容进行分词,并统计每个词出现的频率。这有助于了解新闻的主题关键词。
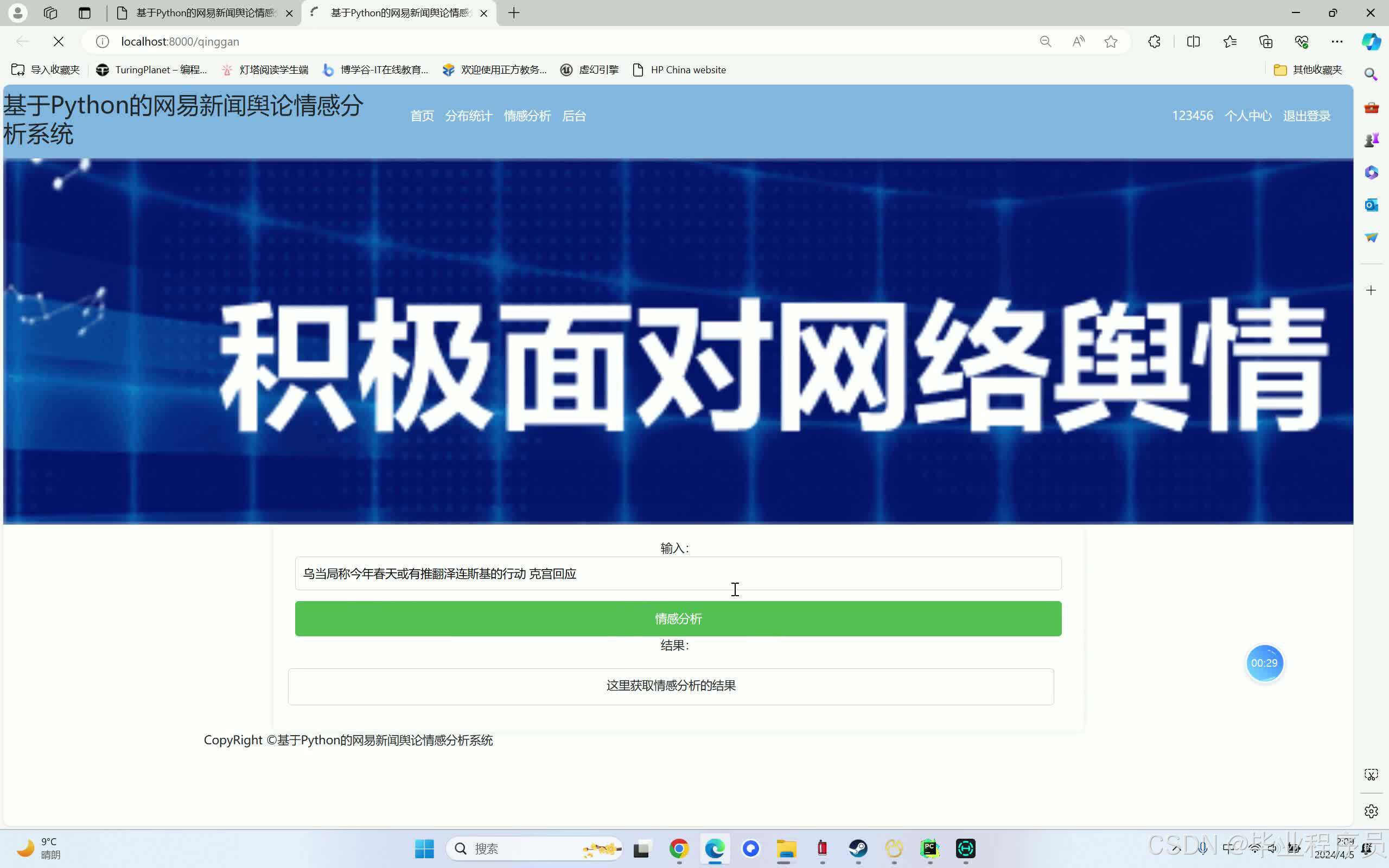
情感分析:使用SnowNLP库或长短期记忆网络(LSTM)等深度学习模型对新闻内容进行情感分析。情感分析的结果可以是一个分数或标签,表示新闻内容的整体情感倾向(积极、中性或消极)。
数据可视化:使用Python的WordCloud库生成词云图,以视觉效果突出的方式展示新闻内容中出现频率高的词汇。同时,可以使用echarts等图表库将情感分析的结果进行可视化展示,如柱状图、折线图等。
数据抓取:编写Python脚本,使用Scrapy框架或requests库从网易新闻网站抓取新闻内容。可以根据需要设置抓取条件,如新闻类别、发布时间等。
数据预处理:对抓取到的新闻内容进行清洗和格式化处理,确保数据的准确性和一致性。
中文分词与词频统计:利用jieba分词库对新闻内容进行分词,并使用Python的collections库统计每个词出现的频率。
情感分析:选择SnowNLP库或LSTM等深度学习模型对新闻内容进行情感分析。根据情感分析的结果,可以为新闻内容打上情感标签或计算情感得分。
数据可视化:使用WordCloud库生成词云图,展示新闻内容中的关键词。同时,使用echarts等图表库将情感分析的结果进行可视化展示,如绘制情感倾向的柱状图或折线图。
三、核心代码
部分代码:
def users_login(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
if req_dict.get('role')!=None:
del req_dict['role']
datas = users.getbyparams(users, users, req_dict)
if not datas:
msg['code'] = password_error_code
msg['msg'] = mes.password_error_code
return JsonResponse(msg)
req_dict['id'] = datas[0].get('id')
return Auth.authenticate(Auth, users, req_dict)
def users_register(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
error = users.createbyreq(users, users, req_dict)
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
def users_session(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code,"msg":mes.normal_code, "data": {}}
req_dict = {"id": request.session.get('params').get("id")}
msg['data'] = users.getbyparams(users, users, req_dict)[0]
return JsonResponse(msg)
def users_logout(request):
if request.method in ["POST", "GET"]:
msg = {
"msg": "退出成功",
"code": 0
}
return JsonResponse(msg)
def users_page(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code,
"data": {"currPage": 1, "totalPage": 1, "total": 1, "pageSize": 10, "list": []}}
req_dict = request.session.get("req_dict")
tablename = request.session.get("tablename")
try:
__hasMessage__ = users.__hasMessage__
except:
__hasMessage__ = None
if __hasMessage__ and __hasMessage__ != "否":
if tablename != "users":
req_dict["userid"] = request.session.get("params").get("id")
if tablename == "users":
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = users.page(users, users, req_dict)
else:
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = [],1,0,0,10
return JsonResponse(msg)
四、效果图
五、文章目录
目 录
摘 要 1
Abstract 2
第1章 绪 论 5
1.1研究背景 5
1.2研究的目的 5
1.3国内外研究现状 6
1.4 课题研究的主要内容 6
第2章 相关技术 7
2.1 Python语言 7
2.2 Django框架 7
2.3 MySQL数据库 7
2.4 VUE技术 8
2.5 Hadoop介绍 9
2.6 推荐算法介绍 9
2.7系统运行环境 9
2.8本章小结 10
第3章 系统分析 11
3.1系统可行性分析 11
3.1.1经济可行性分析 11
3.1.2技术可行性分析 11
3.1.3操作可行性分析 11
3.2系统现状分析 12
3.3系统用例分析 12
3.4系统流程分析 14
3.5本章小结 15
第4章 系统设计 16
4.1系统功能结构设计图 16
4.2数据库设计 16
4.3本章小结 30
第5章 系统实现 31
5.1系统功能实现 31
5.1.1前台首页页面实现 31
5.1.2个人中心页面实现 32
5.2 后台模块实现 33
5.2.1管理员模块实现 33
5.2.2服务人员模块实现 38
5.3本章小结 38
第6章 系统测试 39
6.1系统测试目的 39
6.2系统功能测试 39
6.3系统测试结论 40
6.4本章小结 40
结 论 41
参考文献 42
致 谢 43
六 、源码获取
下方名片联系我即可!!
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











