







 本文聚焦深度学习算法在手写数字识别中的应用。分析线性感知器、卷积神经网络等算法优缺点,引入TensorFlow系统对比不同框架下算法的识别速度与准确率。实验表明,多层卷积神经网络和长短时记忆网络在提高识别率上优势明显,TensorFlow框架效率更高。
本文聚焦深度学习算法在手写数字识别中的应用。分析线性感知器、卷积神经网络等算法优缺点,引入TensorFlow系统对比不同框架下算法的识别速度与准确率。实验表明,多层卷积神经网络和长短时记忆网络在提高识别率上优势明显,TensorFlow框架效率更高。
目 录
摘 要 1
Abstract 2
前 言 3
第一章 绪 论 4
1.1 研究背景及意义 4
1.2 深度学习概述 4
1.3 本文的主要工作 5
1.4 本文的组织结构 5
第二章 数字图像识别技术 7
2.1 图像识别技术 7
2.2 研究现状分析 7
2.2.1 基于神经网络 8
2.2.2 基于小波矩 9
2.2.3 基于分形特征 9
2.3 本章小结 9
第三章 基于深度学习的数字识别方法 10
3.1 深层神经网络训练方法 10
3.1.1 线性感知器算法 10
3.1.2 卷积神经网络算法 10
3.1.3 循环神经网络算法 13
3.1.4 长短时记忆网络算法 14
3.2 Google第二代人工智能系统TensorFlow 15
3.3 手写数字数据库MNIST数据集 16
3.4 本章小结 17
第四章 数字图像识别的实现与分析 18
4.1 实验环境介绍 18
4.2 基于Python对数字图像识别的实现 18
4.2.1 线性感知器算法实现 18
4.2.2 CNN算法实现 19
4.2.3 RNN算法实现 20
4.2.4 LSTM算法实现 20
4.3 TensorFlow对数字图像识别的实现 21
4.3.1 线性感知器算法实现 21
4.3.2 CNN算法实现 22
4.3.3 RNN算法实现 23
4.3.4 LSTM算法实现 23
4.4 两种实现方法的对比分析 24
4.5 本章小结 25
第五章 总结与展望 26
5.1 本文总结 26
5.2 后续工作及展望 26
参考文献 28
致 谢 30
摘 要
近年来,手写体数字识别是计算机视觉和模式识别中的一个广受关注的问题,引起了越来越多学者的兴趣。这个问题的主要挑战是设计一种有效的方法,可以识别用户通过数字设备提交的手写数字。虽然已有很多相关的研究成果,但是在数字识别这一领域始终不能达到完全使人满意的结果。目前,深度学习算法在计算机视觉中非常流行,被用于解决诸如图像分类、自然语言处理和语音识别等重要问题。
本文以深度学习的几种常见算法,包括线性感知器、卷积神经网络、循环神经网络、长短时记忆网络为研究对象,分析了其在手写数字识别上的优缺点,并引入了Google第二代人工智能系统TensorFlow,进而对比了相同的算法在不同的框架下识别的速度以及准确率。结果表明,这几类深度学习算法都能够高效的识别数字图像,尤其是多层卷积神经网络算法和长短时记忆网络算法,在提高识别率方面有明显优势,且在训练数据集时不会损耗过多的计算资源。
关键词:深度学习;手写数字识别;TensorFlow
Abstract
In recent years, handwritten digit recognition is a widely-reviewed issue in computer vision and pattern recognition, which has attracted lots of scholars’ interest. The main challenge of this problem is to design an effective method that can identify handwritten digits submitted by users through digital devices. Although there have been many related research results, it has not been possible to achieve completely satisfactory results in the field of digital identification. Currently, deep learning algorithms are very popular in computer vision and are used to solve important issues such as image classification, natural language processing and speech recognition.
This article takes several common deep learning algorithms, including linear perceptron, convolutional neural network, recurrent neural network and short-term memory network, as the research object, analyzes the advantages and disadvantages of handwriting recognition, and introduces Google’s second On behalf of artificial intelligence system TensorFlow, and then compared the same algorithm in different frameworks to identify the speed and accuracy. The results show that these types of deep learning algorithms can effectively identify digital images, especially multi-layer convolutional neural network algorithms and long-term memory network algorithms, have obvious advantages in improving the recognition rate. And it will not be in the training data set Excessive computational resources.
Keywords: Handwritten Digit Recognition; Deep Learning; TensorFlow
前 言
深度学习,即从大数据中学习将现实生活中的东西转化为计算机语言,类似于人的学习功能。是否从大数据中学习得到成果是区分深度学习与传统模式的最显著的特征。在先前的研究之中。手工代码识别是最为广泛的被采用的方式,但是实际上已经不太符合现在机器学习发展的需求,从易用性、准确率都和现有的深度学习有一定的差距。
传统的手工代码对于一件事物行为特征的学习周期往往都是数以年记,这样的时间对于实际工程的需要往往是致命的。其算法训练出来的精确率也通常很低,短期内完全不能使用。按照技术发展历程,基于神经网络的深度学习必然将取代传统手工的数字识别,其高准确率,损耗时间周期短等优点随着算法的日益完善而更加突出。
本文就以深度学习的几种常见算法为研究对象,分析了其在数字图像识别上的各种优缺点,并介入了Google第二代人工智能系统TensorFlow进而对比了同样的算法,在基于不同的框架时候的识别的速度以及准确率,并进行实验认证。本文的主要工作如下:
(1)归纳整合了目前用于深度学习的常见高效的几种算法,并且同时实现手工设计以及基于人工智能系统TensorFlow下的实验对比,证实基于神经网络的深度学习已经大幅度超越手工代码。
(2)分析了深层神经网络的4种训练方法的原理。
(3)进行实验后通过充分的实验数据分析,对系统的功能和性能进行评估和优化,并总结相应的优缺点,对未来提出展望。
第一章 绪 论
本章首先介绍了数字图像识别技术的研究背景和意义,其次简单介绍了深度学习目前的研究成果以及发展状况,并概述了本文所做的主要工作和贡献,在本章的最后介绍了论文的组织结构。
1.1 研究背景及意义
图像识别[1] 是模式识别技术的一种,特指对图象类模式的辨认。图像识别过程包括训练和测试两个阶段,而其又主要由图像预处理、特征提取以及分类三个环节组成。在图像识别中,首先要对获取的图像进行预处理,目的是去掉图像中的噪声,把它变成一幅清晰的点阵图,以便于提取正确的图像特征[2]。其次在图像中进行需要的目标图像特征提取。之后,对于目标的图像特征进行分类。
图像识别实现目前主要方法就是机器学习,当下时代的要求已经远超过了简单的机器学习所能提供的条件,并且在实际应用是也会遇到诸多困难。在信息化,智能化的时代背景下,我们需要高准确率、时间周期短的高效算法来满足当前的需要。
1.2 深度学习概述
深度学习起源于大脑神经科学,使用了分层次抽象的思想,隶属于机器学习。它能够将数据分层处理,并从数据的每层结构中学到有用的特征。它的优点是人工监督可以被大大地缩减,从而省下大量人工及时间成本。
1950年,图灵提出了“隔墙对话”的概念。使用电脑模拟人类大脑和人类进行对话,让人们无法分辨他们是否在与人或计算机交谈。可惜的是,几十年后人工智能还没有达到这个阶段,人工智能和深度学习也备受质疑。在20世纪80年代, BP算法[3](Back Propagation)开始运用于人工神经网络。与过去人为建立的规则的优势相比,这种方法体现在人造神经网络模型可以从大量训练样本中推导统计规则的事实[4]。之后的90年代中,最大熵和支持向量机SVM等浅层机器学习模型在理论分析和应用中取得的成功使得这些模型成为当前最常见的机器学习算法,但人工神经网络的研究进入低谷。
2006年,深度学习这一概念被提出来。世界上许多顶级大学在深度学习研究中发挥着重要作用。一些组织和公司由此在自身的公司架构里专门组建了深度学习研究部门用以研究该方向的实际应用。2011年,微软和谷歌研究小组深入了解语音识别,原有语音识别技术的框架就此彻底被改变。同时语音识别错误率下降了20%至30%,这在当时业内造成了一定的轰动。2012年深度学习在图像识别领域取得显着成果,ImageNet数据库[5]识别错误率下降11%。不仅仅在大学里,许多大数据公司也参与了深度学习研究。谷歌研究人员设计了一个具有10亿以上参数的机器学习模型来构建和学习详细的网络。2013年,百度创立了深度学习学院,并于当年5月推出了一系列对百度搜索广告系统有用的详细学习系统。百度于2015年12月公开展示使用深度学习技术开发无人驾驶汽车。2016年3月,AlphaGo以深度学习技术为基础,以4:1的结果打破了顶级职业棋手李世石的角色[6]。这一开创性成果也成为深度学习和人工智能领域的里程碑性质的事件。
1.3 本文的主要工作
本文就以深度学习的几种常见算法为研究对象,分析了其在数字图像识别上的各种优缺点,并介入了Google第二代人工智能系统TensorFlow[7]进而对比了同样的算法,在两种实现方法下的识别速度以及准确率,并进行实验认证。本文的主要工作如下:
(1)归纳整合了目前用于深度学习的常见高效的几种算法,并且同时实现手工设计以及基于人工智能系统TensorFlow下的实验对比。
(2)分析了深层神经网络的4种训练方法的原理。
(3)进行实验后通过充分的实验数据分析,对系统的功能和性能进行评估和优化,并总结相应的优缺点,对未来进行展望。
1.4 本文的组织结构
本文共分为五章,各章内容安排如下:
第一章:绪论。本章介绍了课题的研究背景及意义、深度学习概述、本文的主要工作,最后介绍了本文的组织结构。
第二章:数字图像识别技术。本章对现有数字图像识别技术的原理进行了细化,分析和对比了各种现有技术和特点,阐述了各种适用环境以及实际数字图像识别过程中会遇到的的问题和未来发展。
第三章:主要介绍并分析了基于深度学习的各种深层神经网络的训练方法,同时也介绍了Google第二代人工智能系统TensorFlow,以及计算机数据集MNIST数据集,并以此来实现对数字的识别功能。
第四章:数字图像识别的实现与分析。本章节具体来对这些算法通过纯手写Python代码以及基于Python的TensorFlow框架一一进行数字图像识别的实现,并且附上相应算法的测试准确率的结果图,并完成了与第三章所述方法的对比实验。
第五章:总结全文,提出未来工作的设想与展望。
第二章 数字图像识别技术
在本章中,我们对现有数字图像识别技术的原理进行了细化,分析和对比了各种现有技术和特点,阐述了各种适用环境以及实际数字图像识别过程中会遇到的的问题和未来发展。
2.1 图像识别技术
图像识别过程包括训练和测试两个阶段,而其又主要由图像预处理、特征提取以及分类三个环节组成。
现代许多领域都需要图像识别技术,这一技术具有重要的使用价值。许多小型企业和微型企业的应用需要准确识别图像中的数字信息。因此,通过提高识别准确率以及缩短时间周期的方式来大大提高中小企业的效率。在传统的数字识别方法中,需要手工提取特征,存在效率低,速度低,识别算法的鲁棒性低的缺点。与传统方法相比,深度学习技术的特征提取过程只需要前期的编码以及环境配置正确就可以大大提高在线运算的效率,这是这项技术的魅力所在 [8]。
2.2 研究现状分析
1929年,OCR[9](Optical Character Recognition)首先由德国科学家Tausheck提出。OCR就是指的使用图像处理和模式识别技术来识别数字图像。在Tausheck之后的30至40年间,各国才进行了与OCR有关的研究,并且研究的初始阶段主要是研究一种相对简单的0至9位数的方法。 20世纪60年代初期,OCR技术发展迅速,取得了良好的效果。在20世纪80年代中期,OCR技术在汉字识别上取得了一定的进展,对汉字的识别找到了方向。清华大学Dokoi教授与中国科学院联合开展研究与开发,并不断推出一系列高识别率的OCR产品。由于市场的需求的日益增多,具备识别精度高的同时具有良好的人机交互和用户体验才能让这项技术走得更远。
数字图像识别技术的应用领域中包含了快递号码,电话号码,银行账单号码等的识别。在数字图像识别技术中,许多人进入的时间已经释放。到目前为止,识别类型分为两种。其中一个是全局方法,另一个是结构化方法[10]。两种方法都有局限性,但提取特征的创新方法可以弥补一些缺陷。图像识别中最难以实现的部分特征提取。一种特征提取主要从颜色,形状,纹理等方面提取的人工提取函数。另一种为机器学习方法,它是通过使用多层神经网络模拟开发并实现图像的抽象表示,逐渐开发出深度学习从人脑方法学习功能提取抽象信息是一种更为普遍的深度学习方式。经过几十年的发展,数字识别具有非常丰富的算法理论,但对数字识别的研究不会停止。随着许多研究主题,数字识别不再仅仅是模式识别。一个典型的OCR系统[11]包括预处理,特征提取,分类和识别等多个环节。但目前由于多方面的影响,还是会产生各种各样的问题。幸而我们可以采取相应的措施进行解决。例如,提前准备。这个过程并不理想,因此导致图像中的干扰噪声问题,并且因此该算法不能实现期望的识别效果。目前来说,OCR的研究道阻且长。
传统方法进行的识别,每次都需要进行特征提取,特征提取速度慢,精度提高空间大,识别算法固定、不能灵活准确地工作,适应性差。而利用深度学习的方法训练模型,可以迭代更新,学习新的功能,因此具有很强的适应性。
2.2.1 基于神经网络
人工神经网络方法实现了即使在不清晰的背景知识,不确定的推理规则下,也依旧能够处理庞大复杂的环境信息。这样的方法能够允许存在样本有较大的缺陷和失真的现象。神经网络方法的缺点是它的模型尚且还不成熟。有很多类型的的模式还尚不可识别。与此同时,神经网络方法同样允许存在样本有较大的缺陷和失真的现象,但其执行速度快,适应性强,样本的分辨率高。
神经网络图像识别系统[12]是一种神经网络模式识别系统,原理相同。一般的神经网络图像识别系统由预处理,特征提取和神经网络分类器组成。预处理可以消除,平滑,二值化和标准化原始数据中不必要的信息。由于神经网络图像识别系统的特征提取部分不一定存在,因此它被分成有特征提取和无特征提取两类。当使用BP网络进行分类时,首先需要选择不同类型的样本进行训练。每种类型的样本数量应该大致相同,因为一方面阻止了训练后的网络对样本的类别响应过于敏感;另一方面,也可以极大地增快训练的速度 [13]。
本文我们主要探究的就是基于神经网络的方法的两种实现方式的差异。
2.2.2 基于小波矩
基于小波矩的图像识别方法的特点如下:
(1)小波矩特征能够对只经过平面变换(如平移、旋转缩放等)的样本,具有良好的分辨率。小波矩特征可以正确区分没有噪声的情况下的测试样本,其最高正确识别率达到98%。
(2)小波矩的识别率会随着噪声的增加而进行相应的下滑,但是小波矩的识别率下降较为缓慢。
(3)小波矩的特性相对稳定,但随着特征数量的增加,分辨率会产生一定的变化,但变化范围不大,小波矩的精度还是可以稳步提高[14]。
2.2.3 基于分形特征
通常认为自然纹理图像满足分形特征,绘制分形特征并进一步执行理想的纹理分离和目标识别。但人为制作的图像诸如画作之类并不能进行分形特征的提取,因为其并不具有自然的纹理图像。
基于分形特征的红外图像识别主要是由红外探测器获取图像进行预处理,随后进行分形特征的提取,最后开始基于神经网络的红外图像识别,这样子一个简单识别流程就完成了。这种识别方式多见于生物方面,例如骨纹理识别、地质纹理识别等。
2.3 本章小结
本章主要介绍了一些有关数字图像识别的现状分析,以及相应的一些数字图像识别技术。数字图像处理技术在快速发展的同时,也有存有潜在的一些问题,表现在以下五个方面:
(1)目前的处理速度完全无法匹配现有的待处理数据量,我们需要在提高识别精确率的同时缩短整个训练周期以及识别周期;
(2)理论研究进一步深化,形成自身的科学理论体系,并需要开发更多的图像处理技术;
(3)建立统一的图像数据图书馆库,并且设置好索引方便大家进行查阅,只有实现了资源共享才能够更好地促进科学技术的进一步发展。
第三章 基于深度学习的数字识别方法
随着深度学习技术的深入发展,人们探索出许多可以应用于数字识别的不同算法。因此,本章详细介绍并分析了基于深度学习的各种深层神经网络的训练方法,同时也介绍了Google第二代人工智能系统TensorFlow,以及计算机通用的数据集MNIST数据集[16],并以此来实现对数字的识别功能。
3.1 深层神经网络训练方法
3.1.1 线性感知器算法
一个感知器[17]由输入权值、激活函数和输出组成,其存在的问题是,当感知数据集不能线性分离时,感知器规则不会收敛,就无法训练完成这个感知器。为了解决这个问题,我们使用微分线性函数而不是感知器的阶梯函数。 这个感知器被称为线性单位。线性元素收敛到最佳逼近值上,在遇到无法线性分离的数据集的时候。
将权重项和偏置项初始化为0,然后利用下面的感知器规则迭代的修改和,直到训练完成。
其中,,。是与输入对应的权重项,b是偏置项。事实上,可以把看作是值永远为1的输入所对应的权重。t是训练样本的实际值,一般称之为label。根据公式计算得出感知器的输出值y。η是一个称为学习速率的常数,用于控制每一步调整权的幅度。
每次从训练数据中检索样本输入向量时,传感器用于计算其输出y,并根据上述规则调整权重,为每个处理过的样品调整一次权重。 经过多次迭代后,可以训练感知器权重以实现目标函数。
3.1.2 卷积神经网络算法
卷积神经网络(Convolutional Neural Network, CNN)是最重要的一种神经网络,它在最近几年大放异彩,几乎所有图像、语音识别领域的重要突破都是卷积神经网络取得的,比如谷歌的GoogleNet、微软的ResNet等,打败李世石的AlphaGo也用到了这种网络[18]。下图3.1为卷积神经网络示意图。
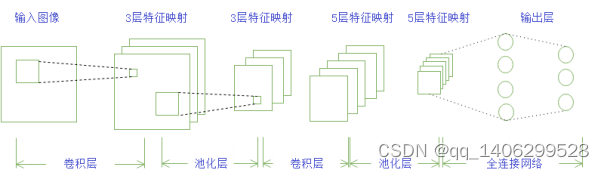
图3.1 卷积神经网络示意图
与以前的神经网络不同,卷积神经网络引入感受野(receptive field)、权值共享(shared weights)、下采样(sub-sampling)。三个新概念。这三种功能不仅协同发挥作用,它们不仅在对象分类或识别中发挥了很好的作用,而且它们的效果更重要的是深度学习处理高分辨率图像容易做到。在像自编码这样的先前的深层模型框架中,输入层和隐藏层完全连接。如果输入采样数据的大小很小(如8 * 8或28 * 28),则从计算的角度来看,它将起作用。但是,尽管有更大的图像数据(例如96 * 96,256 * 256或更多的自然图像),通过完全连接的网络计算特征将非常耗时。例如,如果您有10个第四(= 10000)个输入单位,假设您正在学习100个功能,则有10个第六个功率参数。与28 * 28补丁图像相比,96 * 96图像是完全连接的网络训练,并且计算过程是倍增功率(= 100)的10倍。为了减少连接参数的数量,卷积神经网络引入了卷积或松散耦合的概念来解决这样的问题。简而言之,卷积神经网络的核心是通过三个部分结构感受野、权值共享、下采样的组合来获得一定程度的位移,尺度和变换不变性。
●卷积
卷积即对图像做滤波,而滤波器的大小则为感受野的大小,下图3.2为卷积原理图。图像的统计特征在所有区域有相似性,我们都能使用同样的学习特征即同样的滤波器或卷积核。假定给定了的大尺寸图像,将其定义为。首先通过从大尺寸图像抽取的的小尺寸图像样本训练自编码,计算(为激活函数)可得到个特征,其中和是可视单元和隐含单元之间的权重和偏置。对于每一个大小的小图像,计算对应的,对这个值做卷积,就可得到个卷积后的特征矩阵[19]。
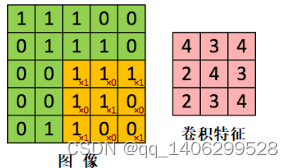
图3.2 卷积原理图
●权值共享
在卷积神经网络中,一般在卷积层后一定会有一个采样层,它们是成对出现的。在卷积层中有单独的滤波器,此滤波器对上一层的输入的不同感受野即同一图像的不同区域进行卷积,一个滤波器对一副完整的输入图滤波完以后输出一张特征图。假设一张Image为5 * 5大小,而滤波器的尺寸为3 * 3,则每个感受野区域的大小也为3*3,滤波器步长为1,则特征图的大小为(5 - 3 + 1) / 1 = 3,即3 * 3。若无权重共享,则Image中一共有9个感受野,每个感受野区域的大小为个3 * 3 = 9连接参数,加上偏置项,一共10个训练参数,则全图共需要的参数个数为9 * 10 = 90。但若有权值共享,即不同感受野共享同样的连接权值,即全图只需要10个连接参数。卷积神经网络训练参数的数量由于权值共享的提出,被大幅度降低,省下了训练数据集的大量时间。
●下采样(池化)
理论上,我们可以使用所有的特征来训练分类器,但是这可以用小图像来实现,但是对于大图像我们会面临计算复杂性和操作效率问题。
下采样便是用以解决这一问题的关键方法。下采样卷积核仅取对应位置的最大值,平均值等,并且不接收反向传播的变化。卷积过程可以提取本地原始图像的关键信息,然后通过训练过程将该信息传递到下一层,以实现图像特征级别的提取和处理。使用卷积函数的原因是图像具有“静态”属性,即图像,并且验收字段具有不同的功能。因此,统计汇总不同位置的特征变成了自然而然的想法,事实上也的确如此去操作。更理所应当的便是对不同位置的特征进行聚合统计比如可以计算一个区域的特征平均值或最大值,这样计算出来的特征不仅可以代表原来的高维度特征,而且还可以使结果不容易过拟合。池化[20]不仅具有上述功能,还具有图像的变换不变性。因此,卷积后的特征集合可以使后期分类更好。下图3.3为池化的原理图。
图3.3 池化原理图
3.1.3 循环神经网络算法
循环神经网络(Recurrent Neural Network, RNN)种类繁多,鉴于篇幅以及本人时间和水平所限,本文只看最基本的循环神经网络,这个基础攻克下来,理解拓展形式也相应的会较为简易。
下图3.4是一个全连接网络
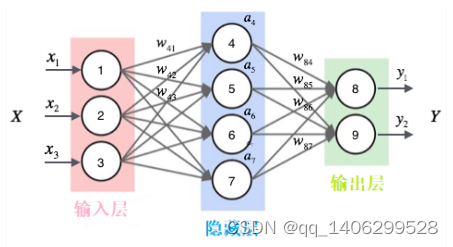
图3.4 全连接网络示意图
隐藏层的值只取决于输入的x,而RNN的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s,见下图3.5。其中,t是时刻,x是输入层,s是隐藏层,o是输出层,矩阵W就是隐藏层上一次的值作为这一次的输入的权重。
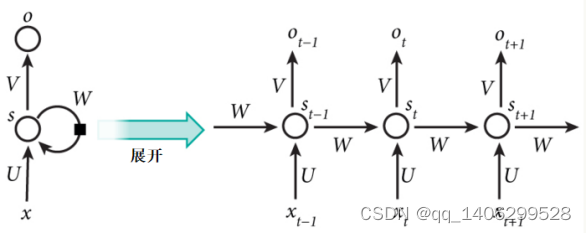
图3.5 基本循环神经网络示意图
RNN [22]的输出层o和隐藏层s的计算方法为,;反复代入这两个公式后会得到:
由此可得,在循环神经网络中可以往前看输入任意多个值[21],从而通过循环的网络,让信息具有记忆持久性。
3.1.4 长短时记忆网络算法
长期短期网络记忆算法(Long Short Term Memory Network, LSTM )通常被称为LSTM,是特殊类型的RNN。这是一种时间递归神经网络,多用处理复杂的需要长期学习的使用与实际生活的事件,见下图3.6。
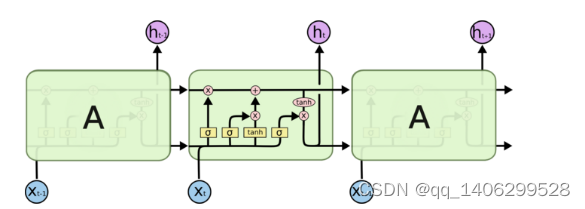
图3.6 长短时记忆网络示意图
RNN和LSTM之间的主要区别在于添加了“处理器”以确定信息是否有用。这个处理器作用的结构被称为cell。这个结构的组成部分为输入门,遗忘门以及输出门。一条消息进入LSTM网络,可根据规则确定它是否有用。符合规则的信息会被留存,之后再需要的时候被输出,否则则会从遗忘门中删除信息。以上图3.6中的输入为和的模块为例,它具有比RNN更为复杂的4层重复结构,共经过3次步骤的处理:
(1)首先我们通过遗忘门来控制经过的信息是否为我们需要的信息,如果是我们需要的信息,则可以进行全部或者需要部分的通过;如果不是我们需要的,则通过遗忘门进入网络中的下一模块继续训练。
(2)第二步,我们用以剔除一部分不需要的旧信息,再输入一部分新信息取而代之。我们将无用的信息经过筛选进入单元状态中,更新其状态后,无用信息被遗忘,新信息被补充进来。
(3)最后,过滤完成,我们根据具体的需求输出信息部分,输出的信息是由我们进行公式选择后的结果,被我们所控制。
它不过是其中一个的工作原理,但它可以解决长期存在的复发神经网络问题。这使得LSTM能够处理不断变化的垂直问题。
3.2 Google第二代人工智能系统TensorFlow
TensorFlow是基于DistBelief开发和升级的谷歌第二代人工智能学习系统。它的名字源自它自己的操作原理为基于数据流图的计算。TensorFlow在机器学习领域用途广泛,如语音识别,图像识别和深度学习领域。这个开源的机器学习软件资源库不仅是一个算法使用的接口,同时也是去实现算法的一个框架,因而它具有非常强盛的功效,极具潜力。它的使用环境十分广阔,上至数据中心服务器的各种设备,下至我们每个人随身携带的智能手机等电子设备。本文基于深度学习的数字识别方法研究就使用了其与手工Python代码进行实现,详见第四章节。
3.3 手写数字数据库MNIST数据集
MNIST(Mixed National Institute of Standards and Technology database),这是一个被研究深度学习的学者们用到泛滥的手写数字数据集了[23]。这其中包含了70000张已经预处理完的手写数字的灰度图片,每一张图片都由个像素点组成,示例见下图3.7。
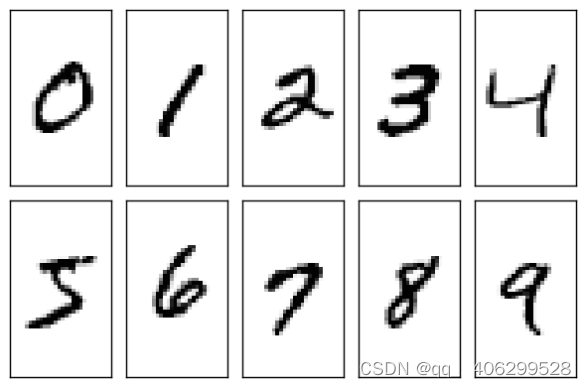
图3.7 数据集内0~9单个数字的样本图片
MNIST 数据集包含了四个部分:
Training set images: train-images-idx3-ubyte.gz(包含60000个样本)
Training set labels: train-labels-idx1-ubyte.gz(包含60000个标签)
Test set images: t10k-images-idx3-ubyte.gz(包含10000个样本)
Test set labels: t10k-labels-idx1-ubyte.gz(包含10000个标签)
其训练原理即为通过放入深度学习的算法中进行相对应的匹配,一个样本对应一个标签来进行学习。当训练完毕后使用测试集内的图片进行测试,通过训练出来的识别能力对当前的测试图片识别得出一个值,并与其对应的标签进行匹配。如果得出的值和其对应的标签相符合,那么这次识别即准确;反之,错误次数叠加一次。
3.4 本章小结
本章首先介绍了深层神经网络的四种训练算法,其中对于CNN算法进行了详细的介绍,也由于篇幅、能力、精力有限,简略地阐述了RNN算法以及LSTM算法的原理。随后,介绍了一下本次研究需要用的TensorFlow算法框架以及本次作为算法学习以及测试的MNIST数据集。
第四章 数字图像识别的实现与分析
本章节详细来对上述算法通过纯手写Python代码以及基于Python的TensorFlow框架一一进行数字图像识别的实现,并且附上相应算法的测试准确率的结果图。
4.1 实验环境介绍
本次方法研究的实验机器配置:
●环境:Microsoft Windows 10 Enterprise_64bit + Python 3.6.5 + TensorFlow 1.8.0
●CPU(Central Processing Unit,中央处理器):Intel Xeon E3-1231 v3
●GPU(Graphics Processing Unit,图形处理器):GTX 970
●RAM(random access memory,随机存储器):16G
4.2 基于Python对数字图像识别的实现
此小节使用自写手工Python实现对数字图像的识别功能,分别使用线性感知器算法、CNN算法、RNN算法以及LSTM算法,并附上相应的实验结果截图。
4.2.1 线性感知器算法实现
运行线性感知器算法基于手工实现的结果如表4.1,进行样本数为1000的测试,每十个数据进行一次准确率的输出。进行5次测试集实验数据结果得出该算法的手工Python实现的精确率约为0.8922,其中某一次迭代的线性感知器算法的手工实现截图片段如下图4.1。

图4.1 线性感知器算法的手工实现截图片段
表4.1 线性感知器算法的手工实现结果
实验序号 1 2 3 4 5
精确率 0.8928 0.8906 08921 0.8884 0.8971
平均精确率 0.8922(保留四位有效数字)
4.2.2 CNN算法实现
将手工实现的CNN算法进行5次迭代,每次进行20次的精确率结果输出,其中某一次的测试实现截图片段如下图4.2。

图4.2 CNN算法的手工实现截图片段
运行CNN算法基于手工实现的结果如表4.2,平均精确度为0.8969。
表4.2 CNN算法的手工实现结果
实验序号 1 2 3 4 5
精确率 0.8963 0.8974 0.8994 0.8937 0.8977
平均精确率 0.8969(保留四位有效数字)
4.2.3 RNN算法实现
实验中我进行了样本为2000且以10为维度的训练测试,通过两层循环层的误差,得出结果。其中某次的RNN算法的手工实现截图片段如下图4.3。
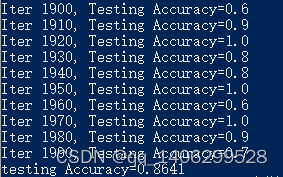
图4.3 RNN算法的手工实现截图片段
记录实验结果得出下表4.3,测试平均精确率为0.4327。但是由测试的结果我们发现从前往后一个逐渐上升的精确率,但是在第5次实验的时候,精确率反而下降了很多。这是因为在反向传播时,发生了梯度消失,RNN算法无法更新参数,这样子长时记忆的效果就没有了,所以精确率奇低无比。
表4.3 RNN算法的手工实现结果
实验序号 1 2 3 4 5
精确率 0.1101 0.2284 0.8564 0.8641 0.0991
平均精确率 0.4327(保留四位有效数字)
4.2.4 LSTM算法实现
对于LSTM的算法实现如下图4.4和图4.5,由(1)我们能看出整个算法在不断的训练,最开始的时候准确率不到0.2,到训练最后期准确率已经能到0.99。
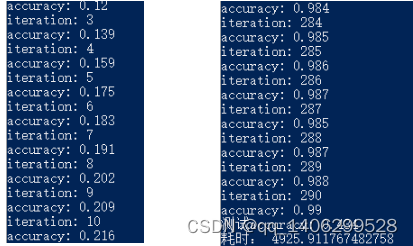
图4.4 LSTM算法的手工实现(1) 图4.5 LSTM算法的手工实现(2)
但是根据多次迭代测试得出表4.5,实际上测试的数字识别总平均精确率只有0.448,且训练时长也需要达到4382.934秒。
表4.4 LSTM算法的手工实现结果
实验序号 1 2 3 4 5
精确率 0.434 0.456 0.447 0.453 0.448
耗费时长/s 4925.912 4206.385 4093.116 4396.245 4293.013
平均精确率 0.448(保留三位有效数字)
平均耗时/s 4382.934(保留三位有效数字)
4.3 TensorFlow对数字图像识别的实现
由于在TensorFlow框架下的深度学习算法的实现得到的精确率每次相差无几,在本小节中就采取了多次实验,并取其中任一值进行记录的方法来对每个算法的精确率进行取样。
4.3.1线性感知器算法实现
初始化变量后,程序将自动使用BP算法来有效地确定变量如何影响最小化成本值。 在这个循环语句中,随机获取训练数据中的50个数据点,并开始数据集的训练。由下图4.6可知,在TensorFlow框架下,我们使用线性感知器算法实现的数字识别功能的准确率可以达到0.9326,远高于手工Python的实现。
图4.6 TensorFlow下线性感知器算法准确率
4.3.2 CNN算法实现
此处我们能够通过图4.7明显看出一个系统学习的过程,在最开始的识别准确率仅有0.1023,在重复的训练之后,识别的精度在不断上升,在1000的样本数据下(以每50个样本为一个单位),我们训练的算法在最终能达到0.9698的识别准确率。

图4.7 TensorFlow下CNN算法准确率
在简单的结构的情况下,即具有更少层的卷积神经网络的情况下,其提取样本特征的能力是有限的。我们可以通过在不改变网络深度的情况下适当增加卷积图层中的滤镜数量来增加滤镜的数量。具体的分类准确率。在少数种类的情况下,将数据集安装在网络的能力强,即网络的分类精度也高。但对于分类数较多的识别问题(分类数大1000),通过自动网络学习获得的样品的特性不足以区分所有类别。通过本文的研究,证明了相对简单的卷积神经网络能更好地识别手写体。分类的数量相对少,卷积神经网络就能有一个良好的识别效果和性能。
4.3.3 RNN算法实现
下图4.8为TensorFlow下RNN算法的训练集的准确率,图4.9为训练完成后实际的测试准确率。在TensorFlow框架下的1000的样本数据(以每100个样本为一个单位)得到的平均识别准确率为0.5121。
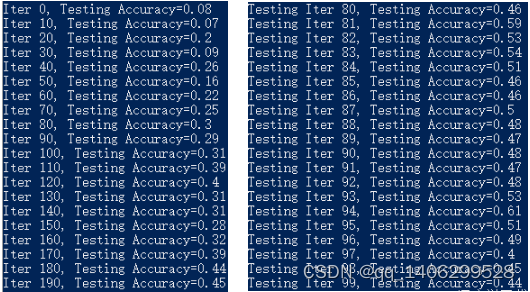
图4.8 TensorFlow下RNN算法训练准确率 图4.9 TensorFlow下RNN测试算法准确率
4.3.4 LSTM算法实现
在重复的训练下,识别的精度在不断上升,在1000的样本数据下(以每50个样本为一个单位),我们训练的LSTM算法在最终能达到0.9的识别准确率。
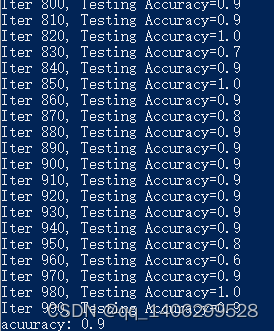
图4.10 TensorFlow下LSTM算法准确率
4.4 两种实现方法的对比分析
我们综合上述实验结果,得出图4.11两种实现方法的对比柱状图,通过横向以及纵向两种方式进行一下两种实现方法的对比分析。
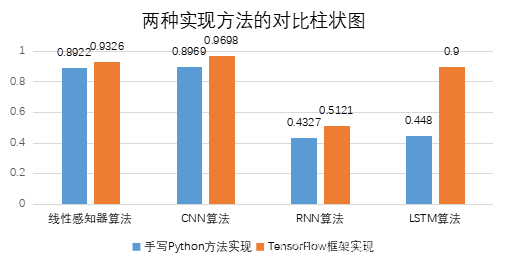
图4.11 两种实现方法的对比柱状图
从算法本身而言,基于线性感知器算法、CNN算法的收敛速度快,RNN算法以及LSTM算法的训练时间则相对要长很多。CNN算法本身的权值共享大大的简化了网络结构,在数据特征提取的时候则相对较为简易,性能方面最为出色,但是不完全适用于学习时间序列。RNN算法神经网络的深度是为时间的长度,会发生梯度消失的问题,并不能影响的十分深远,于是乎它的精确度并不能达到十分高的程度。LSTM算法是从RNN算法上优化出来,用于规避RNN的梯度消失的问题。从上结果中我们也得到随着训练时长的增加,LSTM算法所能达到的精确率几乎能达到100%,实现完全正确识别目标数字。因此LSTM是一个优秀的算法模型,尤其体现在复杂的现实任务上。
从手工代码本身和TensorFlow这个系统而言,手工代码的需要的代码量大,算法并不能太好的得到优化,也不是在所有的系统中都能得到适用,适用性不太强。手写Python的学习周期也比较长,本次实验的训练集并不是十分复杂也用了不短的时间,可想而知用于实际情况中,并不能满足需求。同等条件下,我们使用TensoFlow系统的话,代码简单,可以用在不同的接口上,并且其系统的分析能力更强,数据和模型并行化好,速度快。
4.5 本章小结
本章介绍了一下具体实验的环境以及使用的设备条件。并且根据做实验跑出来的实验数据筛选了一些具有代表性的数据截图贴了上来,以供读者参考。通过结果的分析对比,在没有更加有效的进行数字图像识别的实现方法出来之前,我想TensorFlow系统的算法实现远胜于手写Python代码的算法实现。手工Python的实现方法、工具、性能仍难以和TensorFlow框架下的同样的算法的效率相匹及。
第五章 总结与展望
本章将对本文所做的工作进行总结,同时本章也提出了本文的方法所存在的不足和缺点,并对未来的相关工作做了展望。
5.1 本文总结
近年来,深度学习和深度神经网络在科学界以及工业应用领域都取得了重大的进展。由于时代的不断发展,人们探索出许多可以应用于数字识别,基于深度学习的不同算法。同时应日益发展的需要,对于数字图像识别的高精确度以及技术智能化的要求也越来越高。
本文主要工作如下:
(1)实现目前用于深度学习的几种通用高效的算法,同时分别基于人工智能系统TensorFlow和基于手动设计进行实验比较。通过实验数据我们可得,在数据量相对较小的情况下,两种实现方法的精度和时间相差不大,但是数据量一旦扩大,需要的分类器变多之后,手工Python的实现方法、工具、性能仍难以和TensorFlow框架下的同样的算法的效率相匹及。
(2)分析深度神经网络四种训练方法的原理以及两种不同的实现方法,并通过具体的实验结果进行优缺点分析。
(3)实验结束后,通过分析充足的实验数据,对系统的功能和性能进行评估和优化。
5.2 后续工作及展望
根据测试结果可以得出,两种基于深度学习的数字识别方法的实现在Windows平台上运行良好,功能达标,准确率较高,因此能够有效的应用于实际生活中。尽管如此,该系统仍有一些不足之处,需要从以下几个方面来进行更进一步的研究改进:
(1)本次实验研究只考虑了监督学习的情况,以及样本数不足,所用计算机无法支持大批量数据训练;实验中我是用了CPU来进行算法的运算,实际上运用GPU来进行计算的性能会得到显著提高。。
(2)在进行CNN算法的实现时,虽然本次实验已经有加深卷积神经网络的层次,但是与实际上在实践中遇到的情况还是相差甚多,只是作为简单模板模拟了CNN算法在浅层神经网络以及深层神经网络的区别。
(3)受时间和个人学术水平所限,本人没有进行更多图像识别算法的研究,还需要后来的学者们不断进行研究探索,来寻求一个最佳的方法对数字图像识别方法进行改进。在未来研究者们也可以将深度学习模型的训练过程自动化,使模型自我迭代学习,从而极大的增加计算的性能和效率。
参考文献
[1] 李月景. 图像识别技术及其应用[M]. 机械工业出版社, 1985.
[2] 王耀南. 计算机图像处理与识别技术[M]. 高等教育出版社, 2001.
[3] CHENG Yue, LIU Qiongsun等. Back-propagation algorithm with magnified error signals一种放大误差信号的BP算法[J]. 计算机应用研究, 2011, 28(2):529-531.
[4] 黄丽. BP神经网络算法改进及应用研究[D]. 重庆师范大学, 2008.
[5] 楚敏南. 基于卷积神经网络的图像分类技术研究[D]. 湘潭大学, 2015.
[6] Chen J X. The Evolution of Computing: AlphaGo[J]. Computing in Science & Engineering, 2016, 18(4):4-7.
[7] Abadi M, Barham P, Chen J, et al. TensorFlow: A System for Large-Scale Machine Learning[C]//OSDI. 2016, 16: 265-283.
[8] 李卓. 基于深度学习的字符识别系统的设计与实现[D]. 北京林业大学, 2016.
[9] Mori S, Suen C Y, Yamamoto K. Historical review of OCR research and development[M]// Document image analysis. IEEE Computer Society Press, 1995:1029-1058.
[10] 许可. 卷积神经网络在图像识别上的应用的研究[D]. 浙江大学, 2012.
[11] 汪益民, 梅林, 张义超. 基于OCR技术的书写文字识别系统设计[J]. 甘肃科技, 2007, 23(8):17-19.
[12] 王丽华. 基于神经网络的图像识别系统的研究[D]. 中国石油大学, 2008.
[13] 彭淑敏, 王军宁. 基于神经网络的图像识别方法[J]. 电子科技, 2005(1):39-42.
[14] 张虹, 陈文楷. 一种基于小波矩的图像识别方法[J]. 北京工业大学学报, 2004, 30(4):427-431.
[15] 李宏贵, 李国桢. 基于分形特征的红外图像识别方法[J]. 红外与激光工程, 1999, 28(1):20-24.
[16] 庞荣. 深度神经网络算法研究及应用[D]. 西南交通大学, 2016.
[17] 刘建伟, 申芳林, 罗雄麟. 感知器学习算法研究[J]. 计算机工程, 2010, 36(7):190-192.
[18] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
[19] 孙晓峰, 彭天强. 一种基于全卷积网络的目标检索方法[J]. 河南工程学院学报(自然科学版), 2017, 29(3):65-71.
[20] 刘万军, 梁雪剑, 曲海成. 不同池化模型的卷积神经网络学习性能研究[J]. 中国图象图形学报, 2016, 21(9):1178-1190.
[21] 张尧. 激活函数导向的RNN算法优化[D]. 浙江大学, 2017.
[22] Sundermeyer M, Schlüter R, Ney H. LSTM neural networks for language modeling[C]//Thirteenth Annual Conference of the International Speech Communication Association. 2012.
[23] Raschka S. Python Machine Learning[M]. Packt Publishing, 2014.
致 谢
大学四年的时光转瞬即逝,还依稀记得刚踏入大学校园的自己的模样,转眼间毕业论文都已经准备完毕,感慨万千。在这四年里,苏州大学留给我太多,有欢笑有泪水有艰辛有怠惰,想到即将离开校园,有一丝兴奋,有一丝不舍,还有一丝无措,但是无论如何,都会向前看。
在这里我由衷地感谢我的论文指导老师章晓芳老师,在论文写作期间,她对我进行了不厌其烦的指导和帮助,为我的论文修改提供了各种宝贵的意见。同时,没有毕业设计检查组老师们在中期检查时给出的建议和帮助,这篇论文也无法最终完成。在此,我向指导和帮助过我的老师们表示最衷心的感谢。
同时,我也感谢本论文引用的各学者的专著,如果没有这些前辈的研究,我无法完成本文的最终撰写。在这一点上,我还要感谢我的朋友和同学,他们不仅在写论文的过程中给了很多实验方法拓展的思路,更是在精神上给了我极大的鼓励。在最终论文的定稿过程中,他们也提供了热情的帮助。
人无完人,金无赤足。由于本人的学术水平有限,所写论文难免有不足之处,恳请各位老师和同学批评和指正!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











