









收藏关注不迷路!!
🌟文末获取源码+数据库🌟
感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
程序资料获取
🌟文末获取资料🌟
一、项目技术
开发语言:Python
python框架:Django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
前端框架:vue.js
二、项目内容和项目介绍
🎈1.项目内容
基于 Python 爬虫的网络小说数据分析系统是一个综合性的平台,旨在通过高效的网络爬虫技术采集网络小说相关数据,并运用数据分析与挖掘手段深入剖析这些数据,为网络小说作者、读者、出版商以及相关研究人员提供有价值的信息和决策依据。该系统能够广泛收集各类网络小说平台的小说信息,包括小说名称、作者、类型、简介、章节内容、读者评论、评分等多维度数据,然后对这些数据进行清洗、整理、存储和深度分析,从而揭示网络小说的流行趋势、读者喜好、创作规律等隐藏在数据背后的信息,助力网络文学产业的健康发展与创新。
🎈2.项目介绍
(一)Python 爬虫技术
1.爬虫框架选择与应用:系统主要采用 Scrapy 爬虫框架进行网络小说数据的采集。Scrapy 是一个功能强大、高效且灵活的 Python 爬虫框架,它提供了完善的爬虫架构和丰富的组件,包括调度器、下载器、解析器、管道等。在使用 Scrapy 时,首先创建一个新的 Scrapy 项目,定义项目的名称、设置和起始 URL。然后编写 Spider 类,在其中定义如何从起始 URL 开始爬取网页,并通过 XPath 或 CSS 选择器解析网页内容,提取所需的小说数据。例如,在爬取起点中文网的小说列表页面时,利用 XPath 表达式定位到小说名称、作者、类型等信息所在的 HTML 标签,将其提取并存储到相应的 Item 对象中。Scrapy 的调度器负责管理请求队列,确保爬虫按照一定的顺序和频率发送请求;下载器负责下载网页内容;解析器对下载的内容进行解析;管道则用于对提取的数据进行进一步处理,如数据清洗、存储到数据库等操作。通过这些组件的协同工作,Scrapy 能够高效地采集大量网络小说数据。
2.反爬虫应对策略:为了应对网络小说平台的反爬虫机制,系统采用了多种技术手段。在请求头设置方面,模拟真实浏览器的请求头信息,包括 User - Agent、Referer、Cookie 等字段,使爬虫的请求看起来更像正常用户的访问。例如,设置合理的 User - Agent,使其与常见的浏览器 User - Agent 相似,避免被网站识别为爬虫。同时,采用 IP 代理技术,定期切换爬虫的 IP 地址,防止因单个 IP 地址请求过多而被封禁。可以从免费或付费的 IP 代理池中获取可用的 IP 地址,并在每次请求时随机选择一个进行使用。此外,合理控制爬虫的请求频率,根据网站的访问规则和服务器负载情况,设置适当的请求时间间隔,避免对网站造成过大的访问压力。例如,在爬取小说章节内容时,设置每章节之间的请求间隔为几秒,以模拟读者正常的阅读速度。
(二)数据处理与分析技术
1.数据处理库 Pandas 与 NumPy:Pandas 是 Python 中用于数据处理和分析的核心库,它提供了高效的数据结构(如 Series 和 DataFrame)和丰富的数据操作方法。在网络小说数据分析系统中,Pandas 用于数据的读取、清洗、转换、合并、分组等操作。例如,使用 Pandas 的 read_csv 函数读取存储在 CSV 文件中的读者评论数据,然后利用 dropna 函数删除含有缺失值的数据行,使用 groupby 函数对数据进行分组统计,如按小说 ID 分组计算每部小说的平均评分等。NumPy 则是 Python 科学计算的基础库,主要用于处理数值型数据,提供了大量的数学函数和数组操作方法。在数据处理过程中,如计算小说的词汇量、章节长度等数值指标时,利用 NumPy 的数组运算功能可以提高计算效率。例如,通过 NumPy 的 len 函数计算小说文本数组的长度,得到章节长度的数值。
2.自然语言处理库 NLTK 与 TextBlob:对于小说内容的文本分析,系统采用了 NLTK(自然语言工具包)和 TextBlob 等自然语言处理库。NLTK 提供了丰富的文本处理工具,如分词、词性标注、命名实体识别等功能。在分析小说文本时,首先使用 NLTK 的分词工具将小说文本分割成单词列表,然后进行词性标注,识别出名词、动词、形容词等词性,为后续的主题挖掘和情感分析奠定基础。TextBlob 则是一个简单易用的文本处理库,它在 NLTK 的基础上进行了封装,提供了更便捷的情感分析和文本翻译等功能。例如,利用 TextBlob 的 sentiment 方法对读者评论进行情感分析,判断评论的情感极性(积极、消极或中性)和情感强度,从而了解读者对小说的整体评价态度。同时,结合 NLTK 和 TextBlob 进行主题挖掘,通过提取文本中的关键词、词频统计等操作,利用主题模型算法(如 LDA)确定小说的主题分布。
3.数据挖掘与机器学习算法:为了更深入地挖掘网络小说数据中的潜在规律和关系,系统运用了一些数据挖掘和机器学习算法。例如,采用聚类分析算法(如 K-Means 聚类)对网络小说进行分类,根据小说的多个特征(如类型、词汇量、读者评分等)将相似的小说聚成一类,以便发现不同类型小说的内在特征和创作模式。在读者行为分析中,使用关联规则挖掘算法(如 Apriori 算法)挖掘读者收藏、订阅和评论行为之间的关联关系,例如发现哪些类型的小说读者更倾向于同时收藏和订阅,或者哪些关键词在读者评论中经常同时出现,从而为推荐系统的设计和营销策略的制定提供依据。此外,还可以利用机器学习算法(如决策树、神经网络等)构建小说推荐模型或预测模型,例如根据读者的历史阅读行为和偏好预测读者可能感兴趣的小说,或者预测小说的未来热度趋势等。在使用这些算法时,通常需要对数据进行预处理和特征工程,将文本数据转换为数值型特征向量,然后利用 Python 的机器学习库(如 Scikit-learn)进行模型的训练、评估和优化。
(三)数据可视化技术
1.Matplotlib 与 Seaborn 库应用:系统主要使用 Matplotlib 和 Seaborn 库进行数据可视化。Matplotlib 是 Python 中最基础、最常用的数据可视化库,它提供了丰富的绘图函数和工具,能够创建各种类型的图表,如柱状图、折线图、饼图、散点图等。在绘制网络小说数据分析结果时,例如绘制小说类型数量分布柱状图,首先导入 Matplotlib 的 pyplot 模块,然后使用 bar 函数创建柱状图,传入小说类型和对应的数量数据,设置好图表的标题、坐标轴标签、颜色等属性,即可生成可视化图表。Seaborn 则是基于 Matplotlib 开发的高级数据可视化库,它在 Matplotlib 的基础上进行了封装和扩展,提供了更加简洁、美观、富有统计信息的可视化风格和函数。例如,在进行小说内容的主题分布可视化时,使用 Seaborn 的 countplot 函数可以更方便地绘制主题计数图,展示不同主题在小说中的出现频率,并且可以通过设置参数调整图表的样式和颜色,使图表更具视觉吸引力。在实际应用中,通常会结合使用 Matplotlib 和 Seaborn,根据不同的可视化需求选择合适的库和函数进行数据可视化,以达到最佳的可视化效果。
2.可视化交互库 Bokeh 与 Plotly:为了实现数据可视化界面的交互功能,系统引入了 Bokeh 和 Plotly 等可视化交互库。Bokeh 是一个用于创建交互式可视化的 Python 库,它支持在浏览器中进行交互操作,如鼠标点击、缩放、平移等。在构建网络小说数据可视化界面时,使用 Bokeh 可以创建动态的图表,例如绘制小说发布时间趋势图时,用户可以通过鼠标在图表上进行缩放和平移操作,查看不同时间段内的详细变化情况,并且可以添加工具提示,当鼠标悬停在数据点上时显示详细信息。Plotly 则是一个功能强大的可视化库,它不仅支持创建交互式图表,还提供了在线可视化平台和丰富的图表模板。通过 Plotly,可以轻松地将数据可视化结果发布到网络上,与其他用户共享和协作。例如,将网络小说类型分布的可视化结果发布到 Plotly 平台上,其他用户可以通过链接访问并进行交互操作,方便数据的传播和交流。
三、核心代码
部分代码:
def config_page(request):
'''
获取参数信息
:return:
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code,
"data": {"currPage": 1, "totalPage": 1, "total": 1, "pageSize": 10, "list": []}}
req_dict = request.session.get('req_dict')
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = config.page(config, config, req_dict)
return JsonResponse(msg)
def config_list(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code,
"data": {"currPage": 1, "totalPage": 1, "total": 1, "pageSize": 10, "list": []}}
req_dict = request.session.get("req_dict")
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = config.page(config, config, req_dict)
return JsonResponse(msg)
def config_info(request, id_):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data": {}}
data = config.getbyid(config, config, int(id_))
if len(data) > 0:
msg['data'] = data[0]
return JsonResponse(msg)
def config_detail(request, id_):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data": {}}
data = config.getbyid(config, config, int(id_))
if len(data) > 0:
msg['data'] = data[0]
return JsonResponse(msg)
def config_save(request):
'''
创建参数信息
:return:
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data": {}}
req_dict = request.session.get('req_dict')
param1 = config.getbyparams(config, config, req_dict)
if param1:
msg['code'] = id_exist_code
msg['msg'] = mes.id_exist_code
return JsonResponse(msg)
error = config.createbyreq(config, config, req_dict)
logging.warning("save_config.res=========>{}".format(error))
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
def config_add(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data": {}}
req_dict = request.session.get("req_dict")
error = config.createbyreq(config, config, req_dict)
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
def config_update(request):
'''
更新参数信息
:return:
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data": {}}
req_dict = request.session.get('req_dict')
config.updatebyparams(config, config, req_dict)
return JsonResponse(msg)
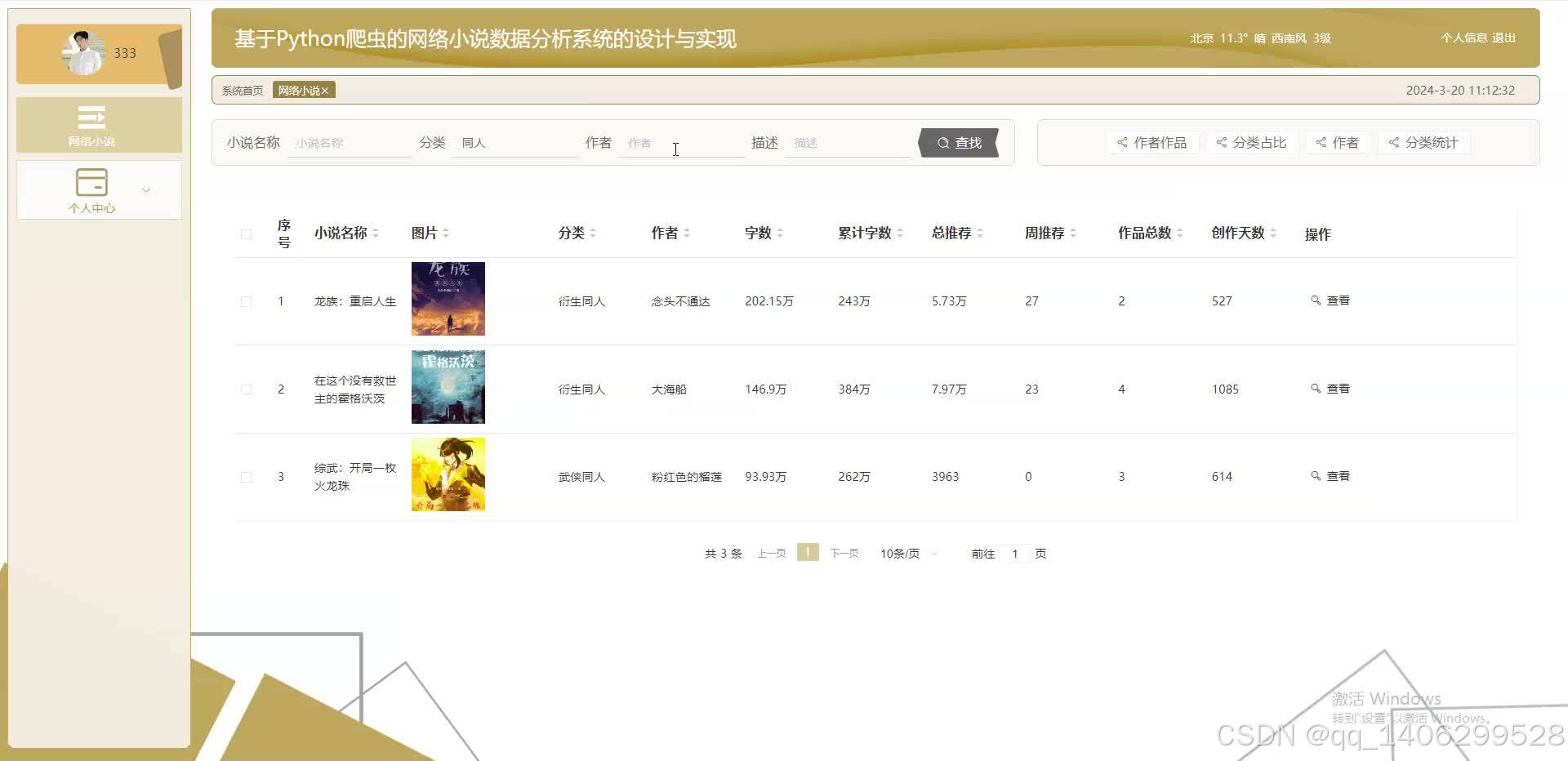
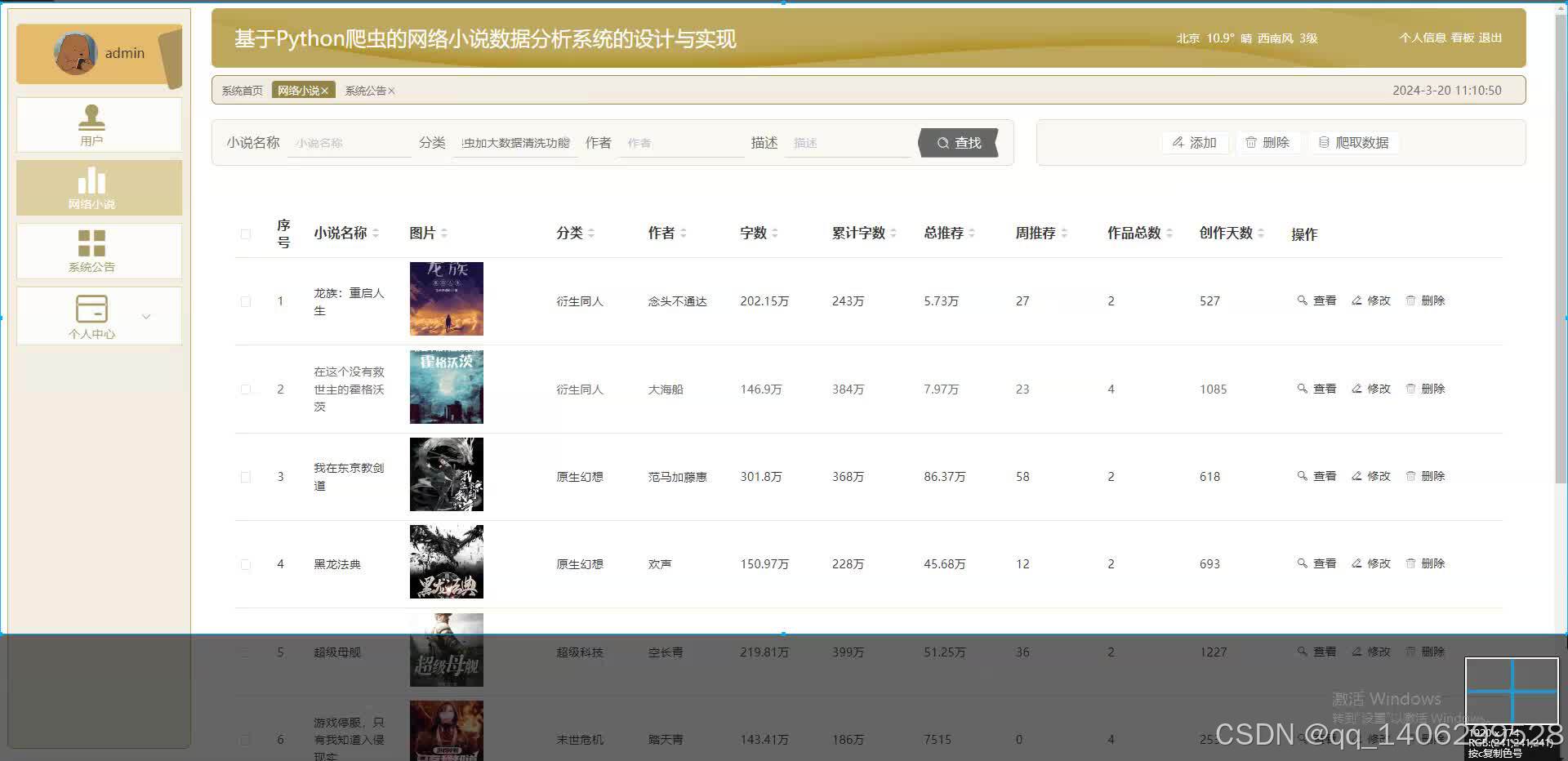
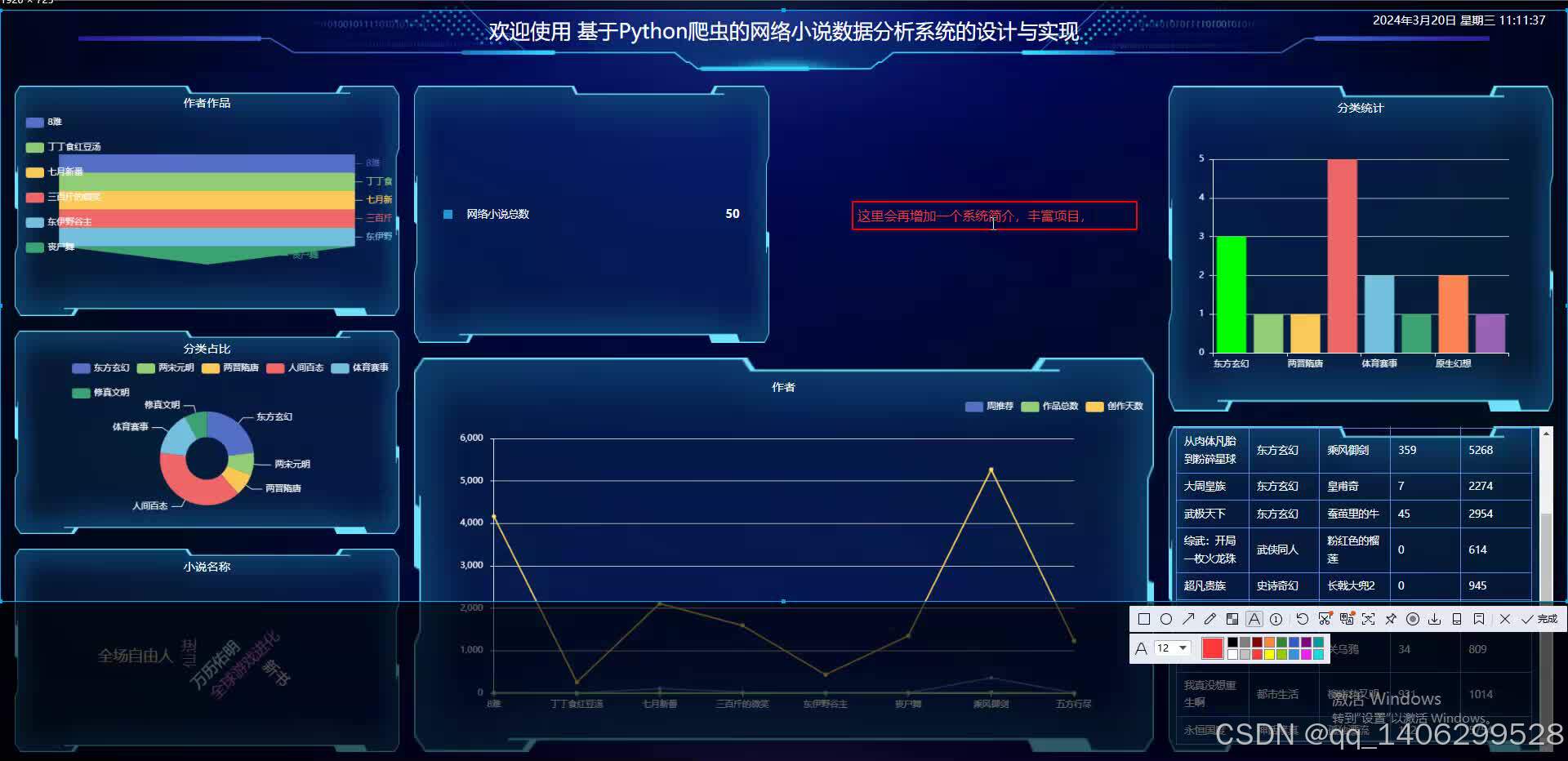
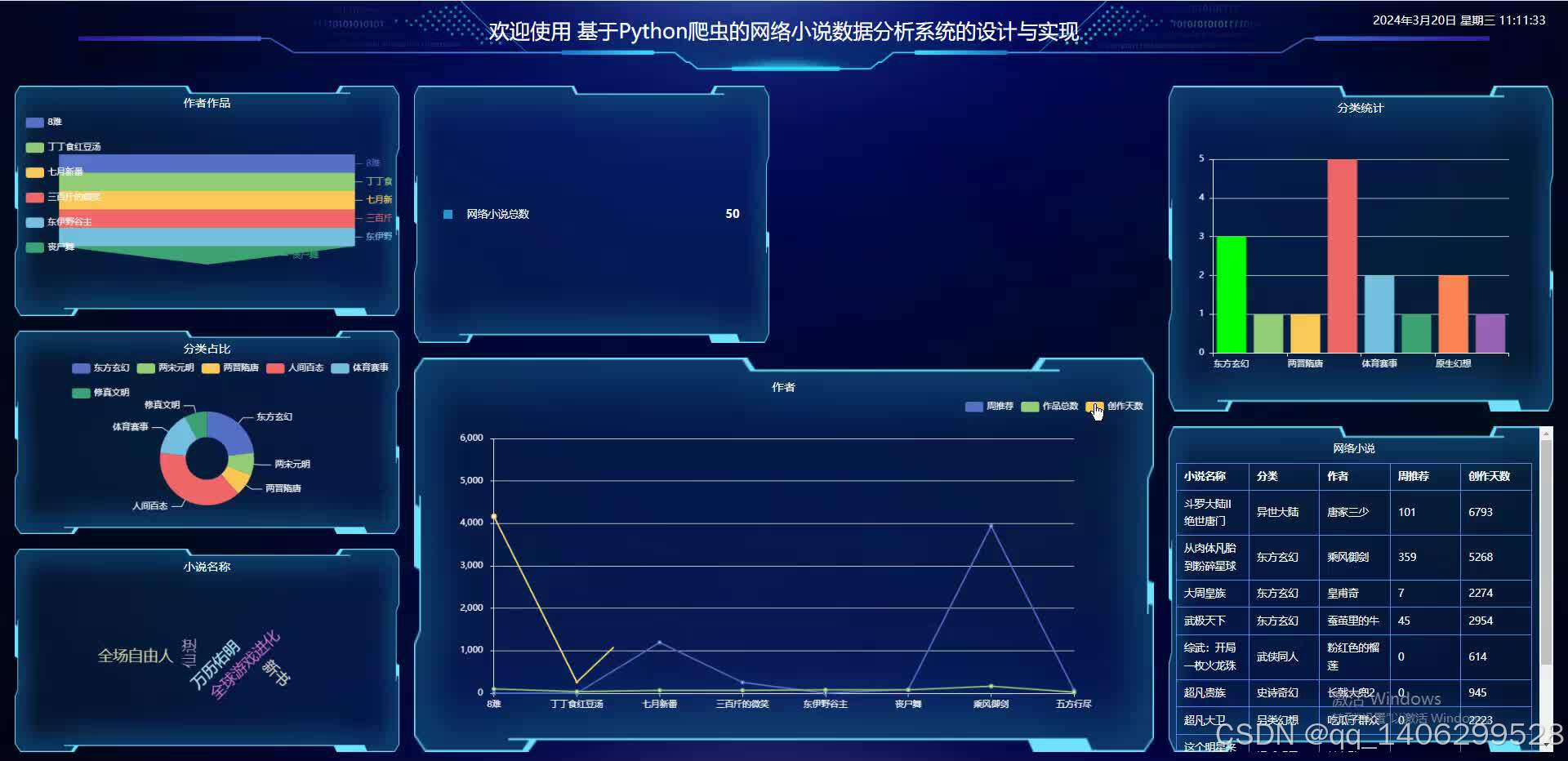
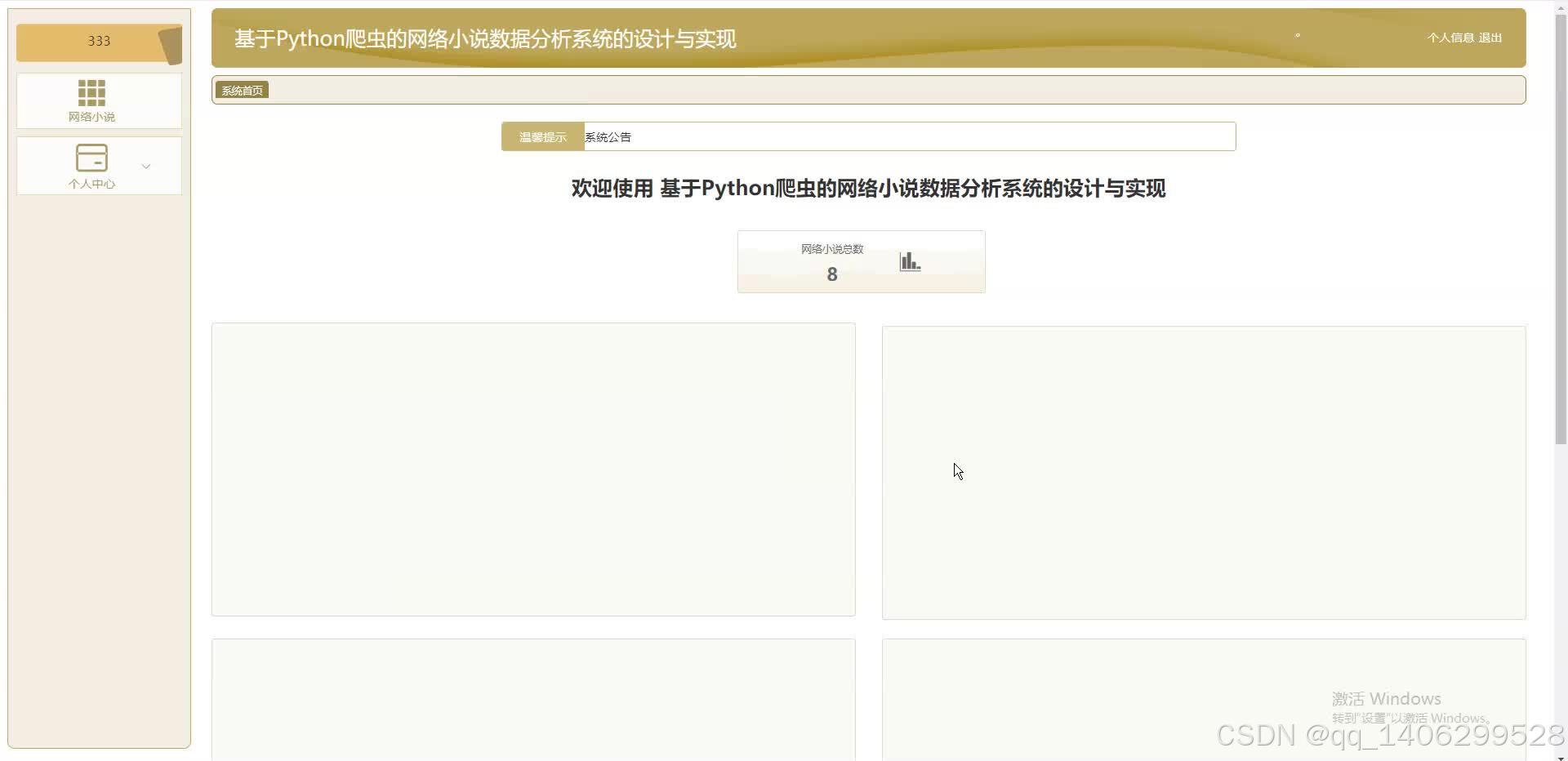
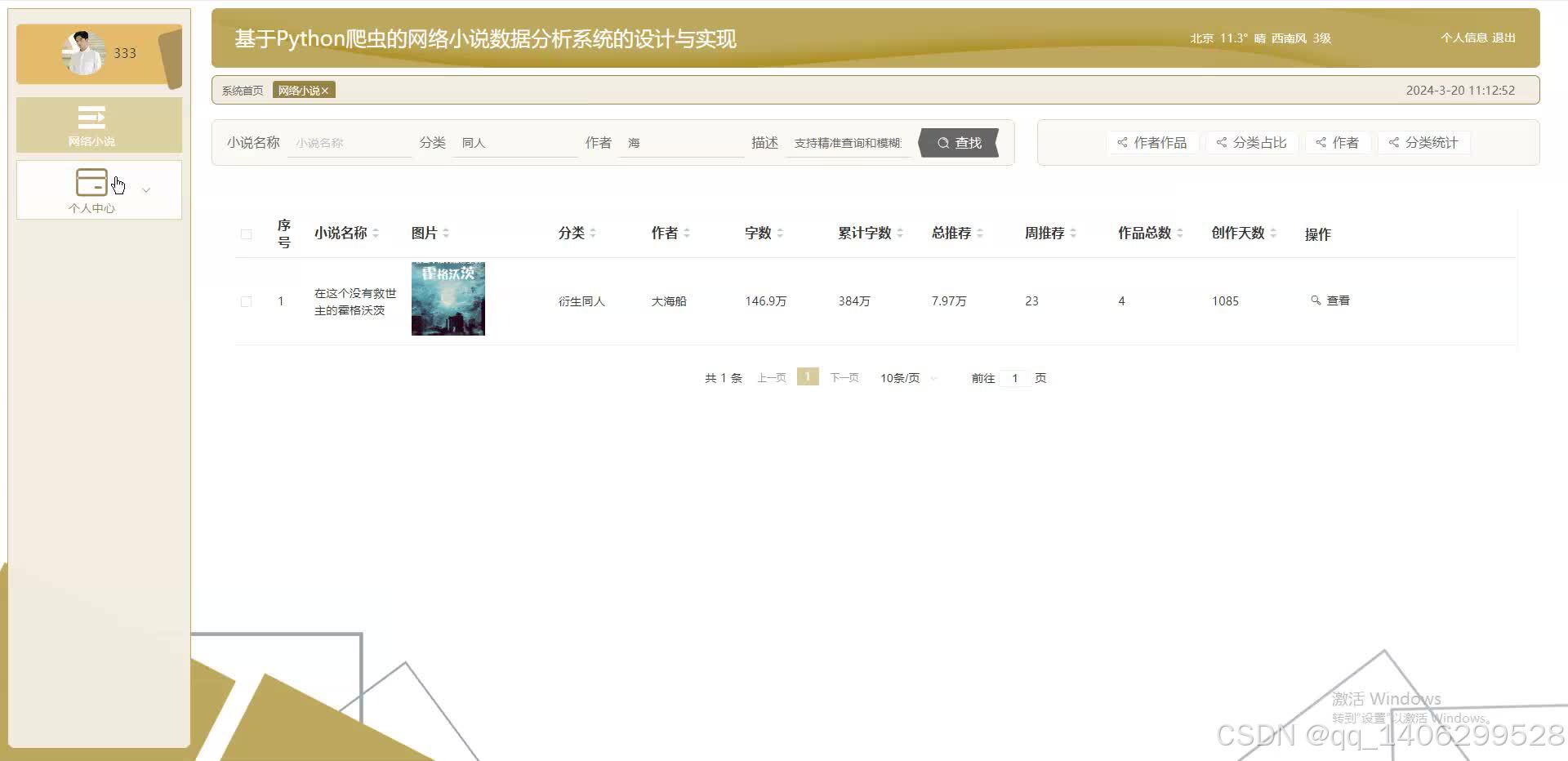
四、效果图
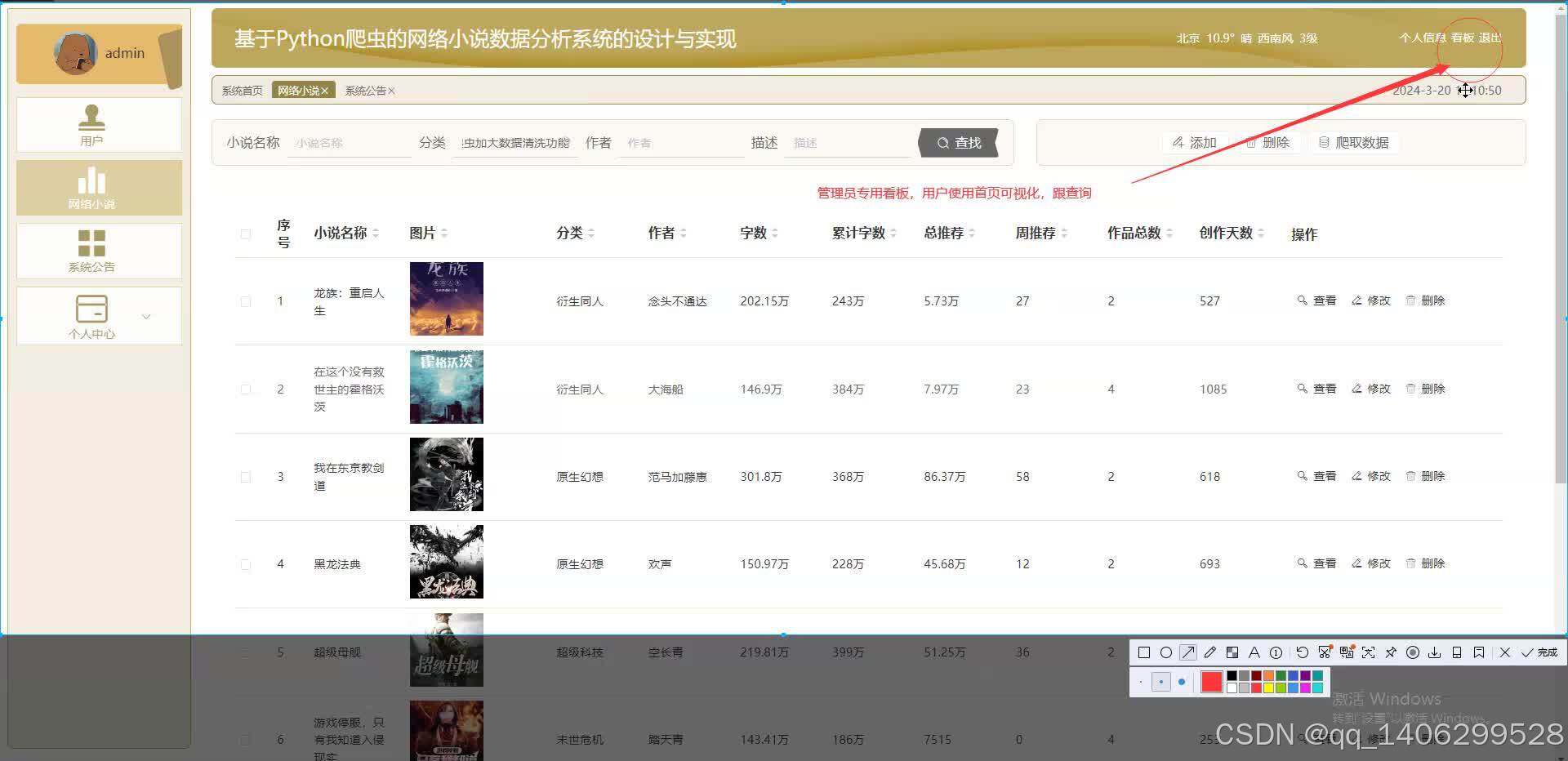
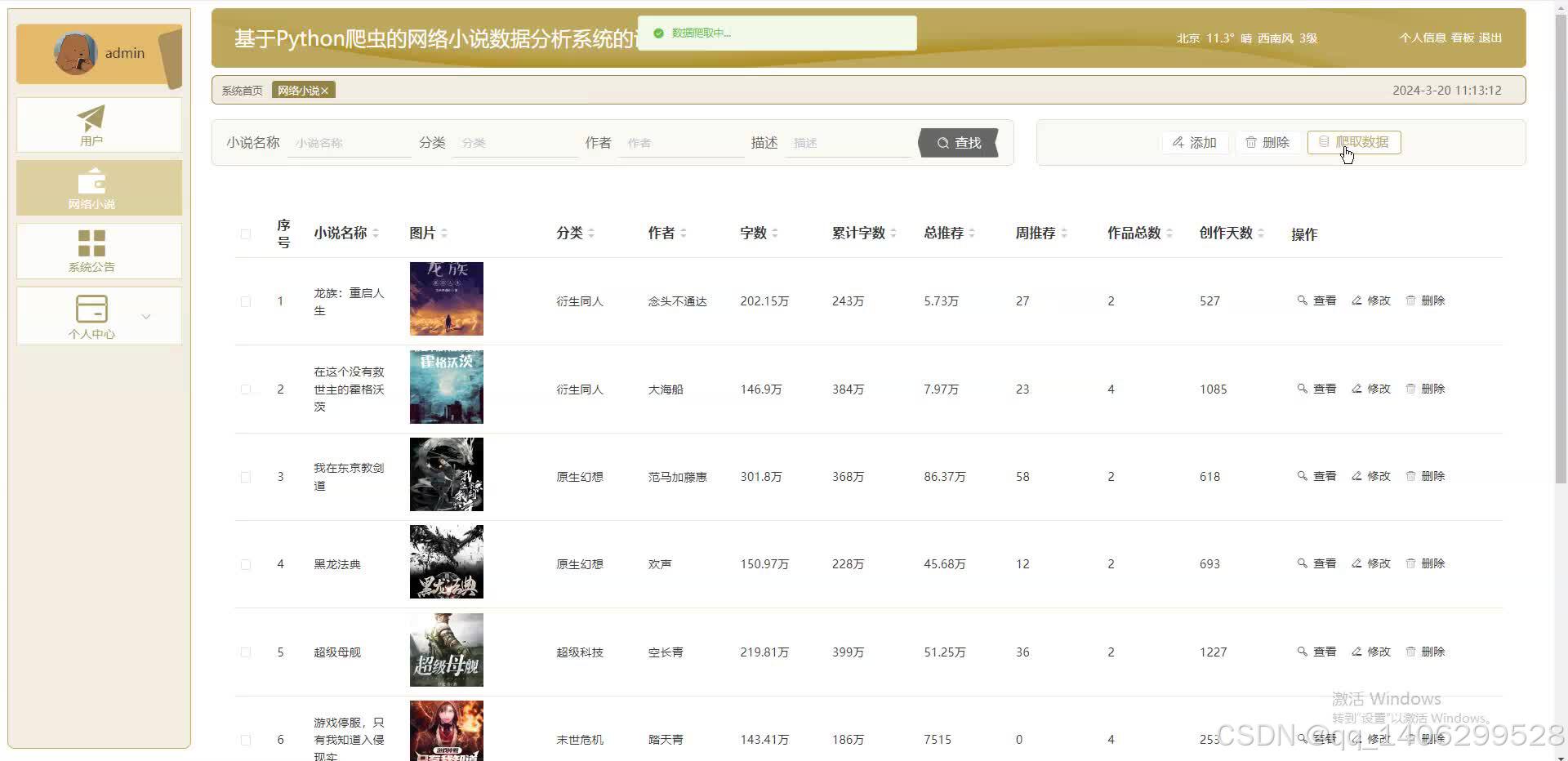
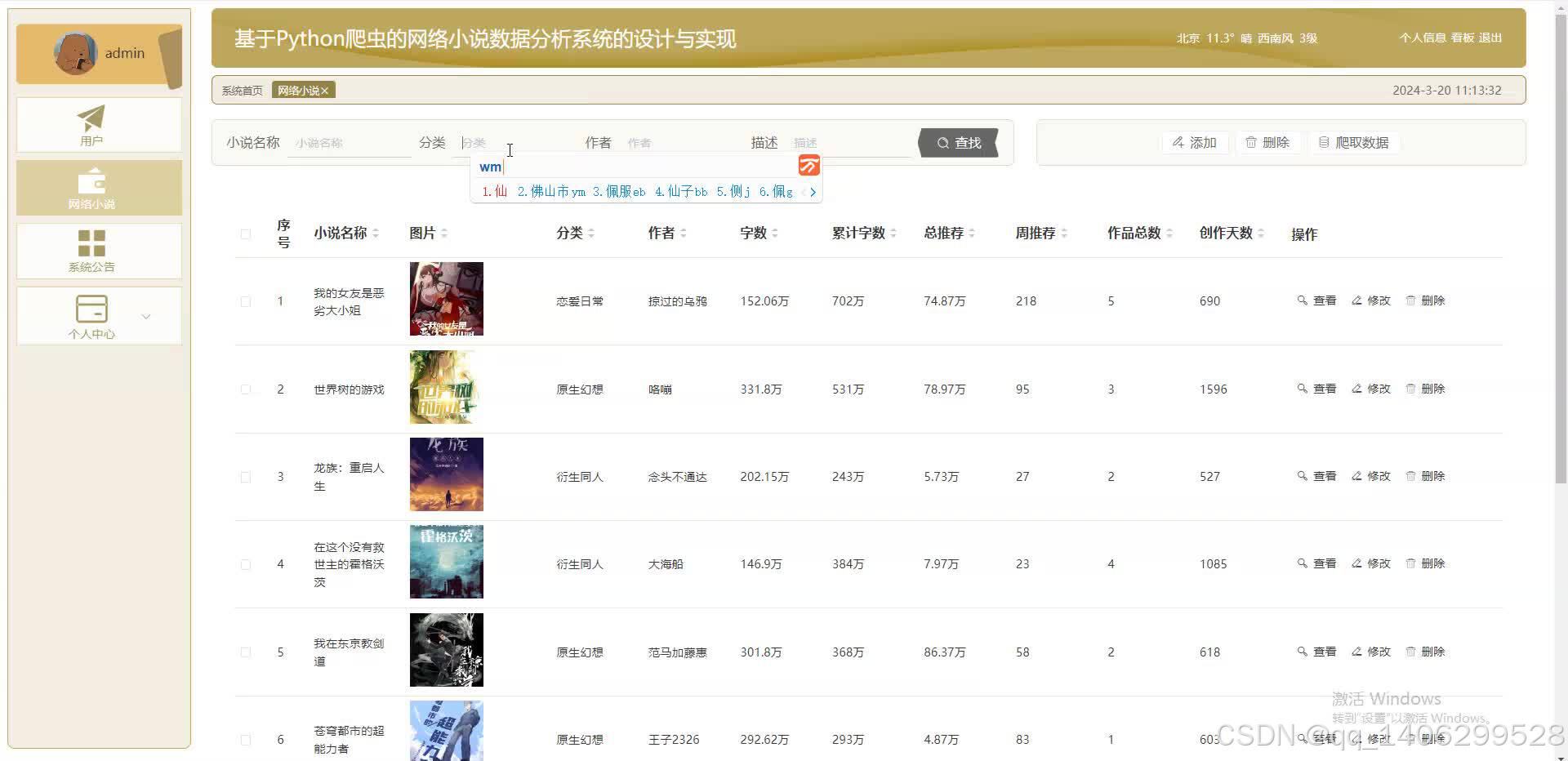
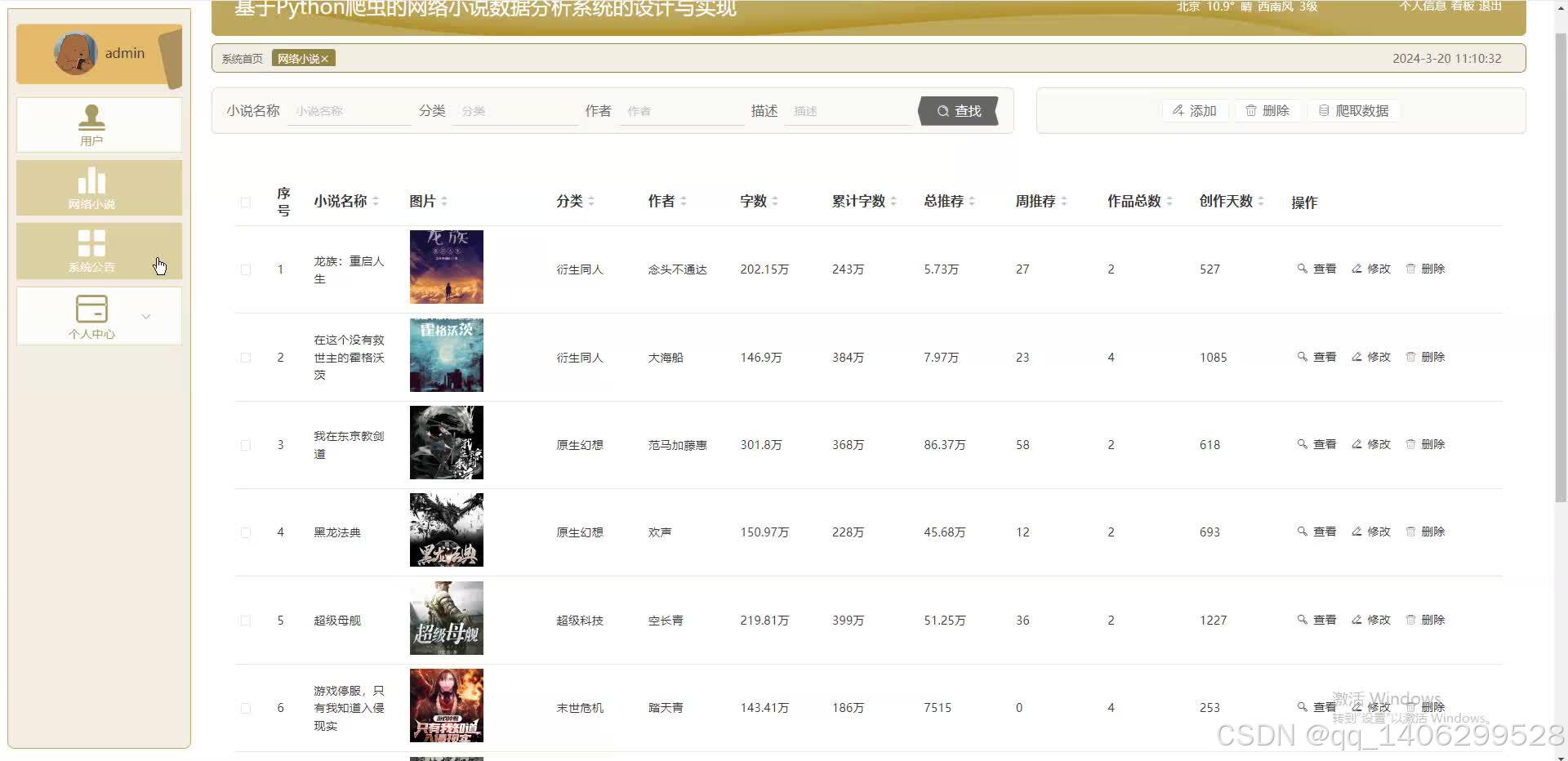
五 、资料获取
文章下方名片联系我即可~
精彩专栏推荐订阅:在下方专栏👇🏻
毕业设计精品实战案例
收藏关注不迷路!!
🌟文末获取设计🌟



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











