







K-means聚类算法
定义:K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
算法过程:
1、随机选取k个中心点
2 、遍历所有数据,将每个数据划分到最近的中心点中
3 、计算每个聚类的平均值,并作为新的中心点
4 、重复2-3,直到这k个中线点不再变化(收敛了),或执行了足够多的迭代
算法图示(选K=2):
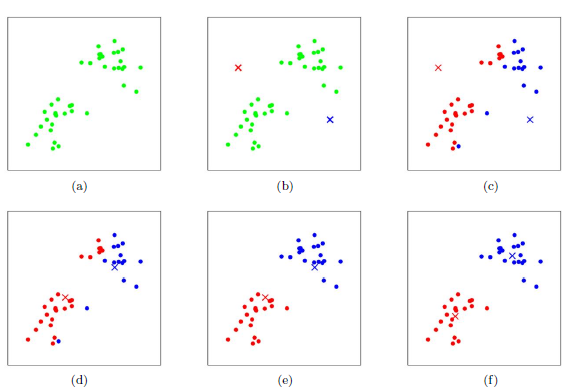
K-Means聚类算法优点:
1、算法快速、简单;
2、对大数据集有较高的效率并且是可伸缩性的;
3、时间复杂度近于线性,而且适合挖掘大规模数据集
Kmeans算法的缺陷:
1、聚类中心的个数K 需要事先给定,但在实际中这个 K 值的选定是非常难以估计的,很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适
2、Kmeans需要人为地确定初始聚类中心,不同的初始聚类中心可能导致完全不同的聚类结果。(可以使用Kmeans++算法来解决)
3、不能用于发现大小或形状不同的簇
4、对噪声和异常数据敏感
DBSCAN算法
(Density-Based Spatial Clustering of Applications with Noise)
定义:
DBSCAN是一个基于密度的聚类算法,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
一些概念:
Ε邻域:给定对象半径为Ε内的区域称为该对象的Ε邻域;
核心对象:如果给定对象Ε领域内的样本点数大于等于MinPts,则称该对象为核心对象;
直接密度可达:对于样本集合D,如果样本点q在p的Ε领域内,并且p为核心对象,那么对象q从对象p直接密度可达。
密度可达:对于样本集合D,给定一串样本点p1,p2….pn,p= p1,q= pn,假如对象pi从pi-1直接密度可达,那么对象q从对象p密度可达。
密度相连:存在样本集合D中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相联。
可以发现,密度可达是直接密度可达的传递闭包,并且这种关系是非对称的。密度相连是对称关系。
算法描述:
(1)检测数据库中尚未检查过的对象p,如果p未被处理(归为某个簇或者标记为噪声),则检查其邻域,若包含的对象数不小于minPts,建立新簇C,将其中的所有点加入候选集N;
(2)对候选集N 中所有尚未被处理的对象q,检查其邻域,若至少包含minPts个对象,则将这些对象加入N;如果q 未归入任何一个簇,则将q 加入C;
(3)重复步骤2),继续检查N 中未处理的对象,当前候选集N为空;
(4)重复步骤1)~3),直到所有对象都归入了某个簇或标记为噪声。
优点:
1. 与K-means方法相比,DBSCAN不需要事先知道要形成的簇类的数量。
2. 与K-means方法相比,DBSCAN可以发现任意形状的簇类。
3. DBSCAN能够识别出噪声点。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









