









在编写和调试程序的过程中,了解程序的执行原理对开发者至关重要。程序调用栈(Call Stack)和栈帧(Stack Frame)是程序运行时的核心概念,帮助我们理解函数调用、递归、错误处理等机制。本文将详细介绍程序调用栈及其栈帧的工作原理,帮助读者更好地掌握这些基本但重要的概念。

什么是程序调用栈?
程序调用栈是一种数据结构,用于管理函数调用过程中的活动记录。每当程序调用一个函数时,系统会将当前的执行状态保存到调用栈中,并在函数返回时从调用栈中恢复之前的状态。调用栈以“后进先出”(LIFO, Last In First Out)的方式管理这些记录,这意味着最后被调用的函数会最先完成执行。
调用栈的主要特点
- 动态性:调用栈的大小会随着函数调用的深度动态变化。
- 有序性:函数调用的顺序严格按照调用栈的顺序执行和返回。
- 局部性:调用栈中的每个栈帧都只与当前函数调用相关,不会影响其他函数的执行。
恢复之前的状态
当一个函数调用另一个函数时,系统需要保存当前的执行状态,以便在被调用的函数完成后能够正确地恢复并继续执行。这个执行状态包括函数的返回地址、局部变量和参数等。这些信息保存在栈帧中,并且栈帧被压入调用栈。
什么是栈帧?
栈帧是调用栈中的基本单元,每个函数调用都会在调用栈中创建一个新的栈帧。栈帧保存了函数执行所需的所有信息,包括局部变量、返回地址、参数等。每个栈帧包含以下几个主要部分:
- 返回地址:记录函数返回时程序应继续执行的地址。
- 参数区:存储传递给函数的参数。
- 局部变量区:存储函数内定义的局部变量。
- 保存的寄存器:保存函数调用前的寄存器状态,以便函数返回时恢复。
栈帧的结构
一个典型的栈帧结构如下所示:
+-------------------+
| 返回地址 |
+-------------------+
| 参数 |
+-------------------+
| 局部变量 |
+-------------------+
| 保存的寄存器 |
+-------------------+

调用栈与栈帧的工作流程
理解调用栈与栈帧的工作流程,可以通过以下一个简单的代码示例来说明:
package main
import "fmt"
func main() {
A()
}
func A() {
B()
}
func B() {
C()
}
func C() {
fmt.Println("Inside function C")
}
1. 函数调用过程
当程序执行到 main 函数时,会首先在调用栈中创建一个栈帧以保存 main 函数的执行状态。然后,main 函数调用 A 函数,系统会在调用栈中为 A 函数创建一个新的栈帧。
随着 A 函数调用 B 函数,调用栈中会继续创建新的栈帧。最终,B 函数调用 C 函数,调用栈中创建了 C 函数的栈帧。
2. 函数返回过程
当 C 函数执行完毕并返回时,系统会弹出 C 函数的栈帧,恢复 B 函数的执行状态。接着,B 函数返回,系统继续弹出 B 函数的栈帧,恢复 A 函数的执行状态。最终,A 函数返回,系统弹出 A 函数的栈帧,恢复 main 函数的执行状态。
调用栈示意图
为了更直观地展示上述过程,我们可以使用 UML 创建一个调用栈的示意图:
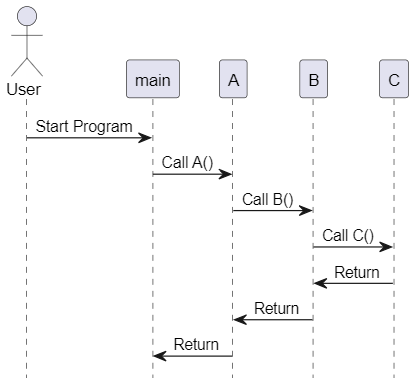
栈帧在错误处理中的应用
栈帧在错误处理和调试过程中也非常有用。例如,当程序发生错误(如 panic)时,调用栈中的栈帧信息可以帮助我们快速定位问题。Go 语言中的 runtime 包提供了丰富的函数用于获取调用栈信息,如 runtime.Callers 和 runtime.CallersFrames。
package main
import (
"fmt"
"runtime"
)
func trace() {
pcs := make([]uintptr, 10)
n := runtime.Callers(2, pcs)
frames := runtime.CallersFrames(pcs[:n])
for {
frame, more := frames.Next()
fmt.Printf("Function: %s\nFile: %s\nLine: %d\n", frame.Function, frame.File, frame.Line)
if !more {
break
}
}
}
func A() {
trace()
}
func main() {
A()
}
通过上述代码,可以在程序中获取并打印调用栈信息,有助于调试和错误定位。
结论
程序调用栈和栈帧是理解程序执行原理的重要概念。调用栈管理函数调用的顺序,而栈帧则保存每个函数调用的详细信息。通过掌握这些概念,开发者可以更好地进行调试、错误处理和性能优化。希望本文能够帮助读者深入理解调用栈与栈帧的工作原理,在实际开发中充分利用这些知识提升编程技能。
















 232
232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











