






转载至:http://blog.csdn.net/Dandelionyu/article/details/45971209
1. 模型评估与模型选择
在实际应用中,针对具体的监督学习问题,为了评估所训练出的模型是否有较好地泛化能力,可以把数据集切割成训练集和测试集两部分(注意使训练集和测试集中均含有各种类型的数据)。
用训练集在各种条件下(如:不同的参数个数)训练模型,学习出其参数后,再在测试集上评价各个模型的测试误差。选择测试误差最小的模型。
引用Andrew Ng的机器学习课程中的一个例子进行说明。
假设要在10个不同次数的多项式模型之间进行选择:
1. hθ(x)=θ0+θ1x
2. hθ(x)=θ0+θ1x+θ2x2
3. hθ(x)=θ0+θ1x+⋯+θ3x3
⋮
10. hθ(x)=θ0+θ1x+⋯+θ10x10
决策函数 hθ(x)
训练集误差 Jtrain(θ)
测试集误差 Jtest(θ)
交叉验证集误差 Jcv(θ)
首先,针对这10个模型分别对目标函数求解最优化问题即 minJtrain(θ) ,得到参数 Θ(1) , Θ(2) , ⋯ , Θ(10) (即得到相应的各个模型) 。然后在测试集上求出各个模型的测试误差 Jtest(θ) 的值。选择使 Jtest(θ) 值最小的参数 Θ(i) 作为模型最终学习到的参数来对未知数据进行预测。
然而,按照这种做法选择出来的参数 Θ(i) 可能只是对我们挑选出的这部分测试集的拟合效果比较好,它并不是一个在完全未知的数据集上选择出的最优模型。所以为了更准确的对模型的泛化能力进行评估,我们有必要使用交叉验证来帮助进行模型选择。
2. 交叉验证
交叉验证法把数据集分成三部分:数据集,交叉验证集,测试集(如6:2:2分配)。还是上面那个例子,模型选择的方法是:
- 使用训练集训练出10个模型;
- 用10个模型上分别对交叉验证集计算出交叉验证误差 Jcv(θ) 的值;
- 选取使 Jcv(θ) 值最小的模型;
- 用步骤3中选出的模型对测试集计算得出泛化误差( Jtest(θ) 的值)。
3. 模型诊断
实际中训练出的模型可能存在 过拟合 或 欠拟合 的情况,这时候就需要对模型所处的情况做出准确地判断以指导模型的改进。下图描述了训练集和交叉验证集与模型复杂度之间的关系。
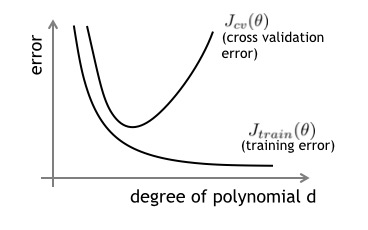
- 对于训练集来说,当d较小时,模型较简单,对数据拟合程度低,误差大;随着d的增大,模型越来越复杂,拟合程度高,误差降到一个比较小得值。
- 对于交叉验证集来说,当d小时,拟合程度低,误差大,但随着d的增大,误差呈现先减小后增大的趋势,转折点是开始出现模型过拟合训练集的情况时。
那么,当交叉验证集的误差 Jcv(θ) 比较大时,则根据上图可以判断:
- Jcv(θ) 和 Jtrain(θ) 相近,都比较大时:欠拟合
- Jcv(θ) 很大,而 Jtrain(θ) 比较小时:过拟合
3.1 正则化
在训练模型时,一般会选择正则化方法来防止过拟合,正则化项的系数 λ 可能会选择的过高或过低,用一个例子来说明:
用参数向量的 L2 范数作正则化项,模型是
hθ(x)=θ0+θ1x+θ2x2+θ3x3+θ4x4要优化的目标函数为J(θ)=12m∑i=1m(hθ(xi)−yi)2+λ2m∑j=1mθj2
(注意正则化项是从 j=1 开始的,没有包含常数项 θ0 )
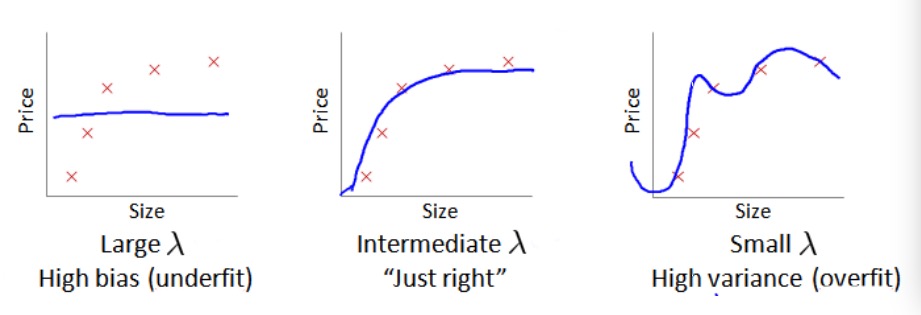
- λ 过大时,求解 minJ(θ) 的结果将使得 θj≈0 (j=1,2,⋯,m) ,此时 hθ(x)≈θ0 是一条水平直线如上图左所示,模型处于欠拟合情况。
- λ 过小( λ≈0 )时,正则化项对模型的修正效果很小近似于无,如上图右所示,模型处于欠拟合情况。
- 为了取得上图中所示比较好的拟合情况,需要选择一个合适的 λ 值,即还是需要考虑和刚才选择多形式模型的次数相类似的问题。
我们选择一系列想要测试的
λ
值,通常是
0∼10
间的呈现2倍关系的值(如:0,0.01,0.02,
⋯
,5.12,10共12个)。
依旧把数据集分为:训练集,交叉验证集,测试集。
则选择 λ 的方法为:
- 针对12个不同的 λ 值,用训练集训练出12个不同的正则化模型
- 在交叉验证集上用12个模型分别计算出对应的交叉验证误差 Jcv(θ)
- 选择使 Jcv(θ) 值最小的模型
- 用步骤3中选择的模型计算得出泛化误差 Jtest(θ)
训练集和交叉验证集与正则化项参数
λ
的关系如下图所示:
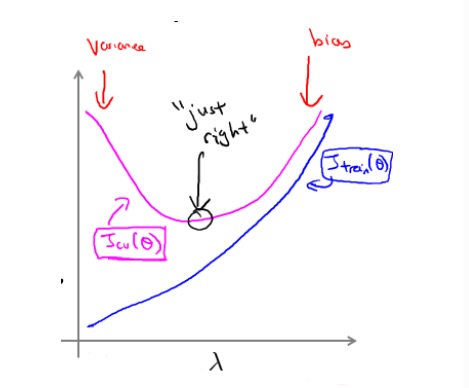
- λ 比较小时,训练集误差 Jtrain(θ) 比较小而交叉验证集 误差 Jcv(θ) 比较大 :过拟合
- 随着 λ 增大,训练集误差 Jtrain(θ) 不断增加而交叉验证集 误差 Jcv(θ) 先减小后增加 :欠拟合
3.2 学习曲线(learning curves)
学习曲线是将训练集误差和交叉验证集误差作为训练集样本数量(
m
)的函数绘制的曲线图。
即,假如有100行数据,从第1行数据开始,逐渐学习更多行的数据。思想是:当训练较少行的数据时,训练的模型将能够完美的适应较少的数据,但是训练出来的模型却不能很好地适应交叉验证集或测试集数据。
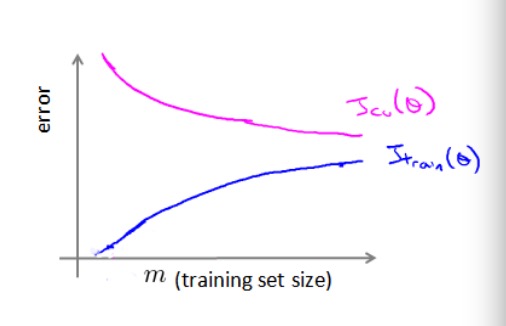
3.2.1 用学习曲线识别欠拟合
作为例子,假设只用一条直线来拟合下面的数据,可以看出,即使训练集样本量不断增大,数据拟合的效果也不会有太大改善:
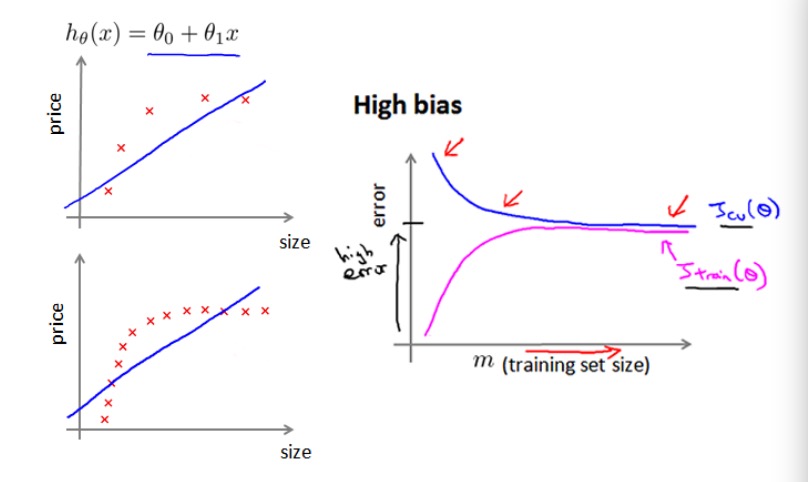
这说明,如果模型处于欠拟合状态,增加训练集的数据量对改善误差没什么帮助。也就是说如果你的模型误差很高,且在增加训练集样本后依然没什么改善,那么就可以判断模型处于欠拟合的状态。
3.2.2 用学习曲线识别过拟合
假设我们使用一个很高次的多项式模型,而且正则化项系数很小,可以看出,当交叉验证集误差远大于训练集误差时,增加训练集里样本数量往往可以有效地提高模型效果:
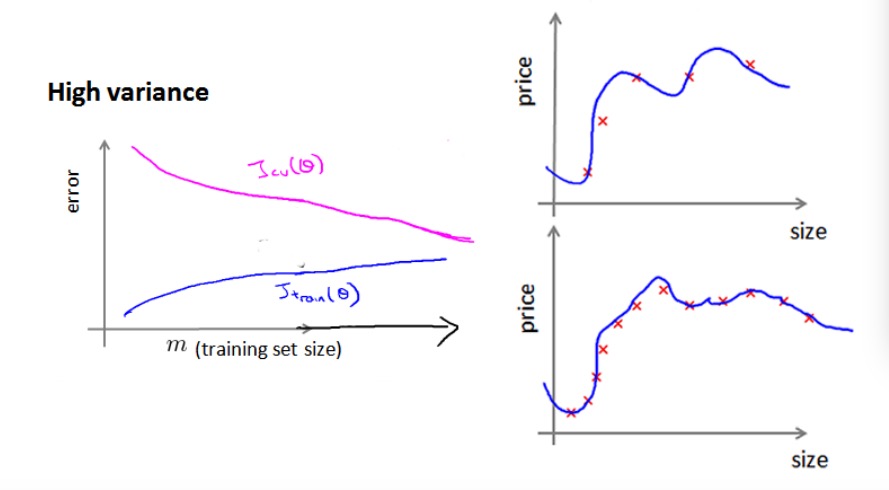
即,模型在过拟合情况下,增加训练集的样本数量可能有效地改善算法效果。
小结
若模型处于过拟合状态,可采取方法:
- 增加训练集样本量
- 减少特征集数量
- 增加正则化项系数 λ 的值
若模型处于欠拟合状态,可采取方法:
- 增加特征集数量
- 增加多项式特征(组合特征)
- 减小正则化项系数 λ 的值















 3475
3475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









