






Kafka 作为分布式流处理平台,以卓越的速度和高吞吐量在大数据领域广受青睐。
它究竟依靠哪些技术实现了如此惊人的性能?Kafka 背后有的 7 大技术优势,从零拷贝网络和磁盘到无锁轻量级 offset 设计,每一项技术都是 Kafka 为快提供了坚实的基础。
码哥将开启《Kafka 性能提升的 7 大秘诀》系列,分为七个章节。本系列你不仅可以学习到 Kafka 性能优化的各种手段,也可以提炼出各种性能优化的方法论,这些方法论也可以应用到我们自己的项目之中,助力我们写出高性能的项目。
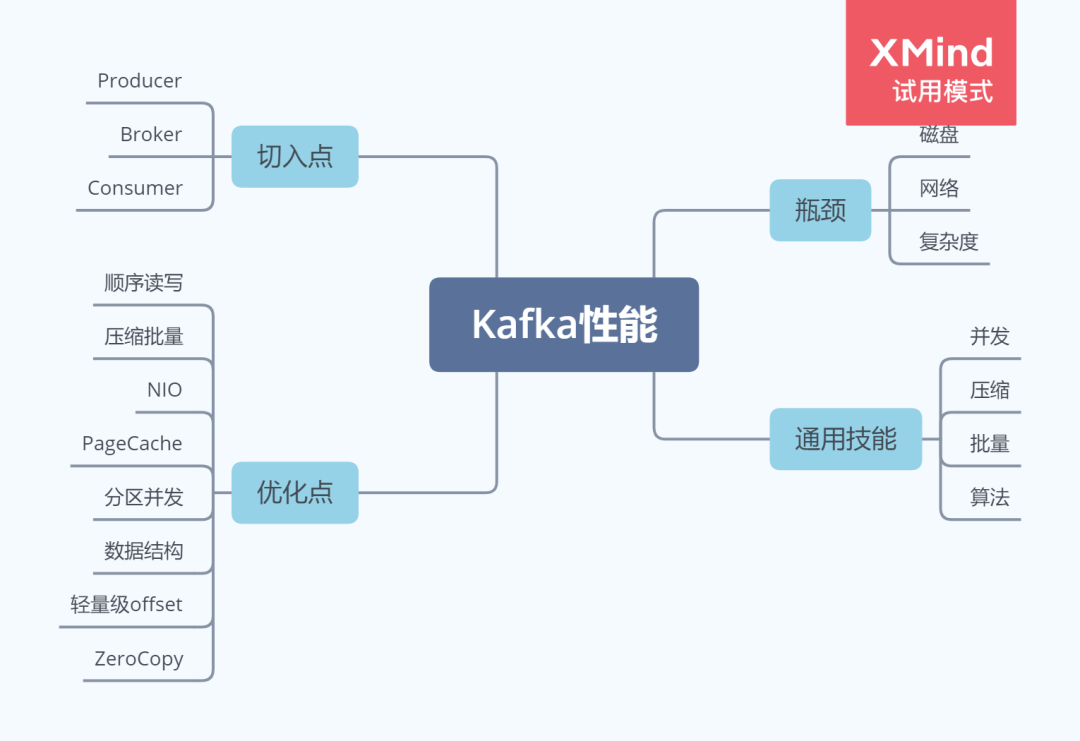
从高度抽象的角度来看,性能问题逃不出下面三个方面:
网络
磁盘
复杂度
对于 Kafka 这种网络分布式队列来说,网络和磁盘更是优化的重中之重。针对于上面提出的抽象问题,解决方案高度抽象出来也很简单:
Partition 并行
数据压缩
批量处理数据
顺序读写磁盘
算法
知道了问题和思路,我们再来看看,在 Kafka 中,有哪些角色,而这些角色就是可以优化的点:
Producer
Broker
Consumer
是的,所有的问题,思路,优化点都已经列出来了,我们可以尽可能的细化,三个方向都可以细化,如此,所有的实现便一目了然,即使不看 Kafka 的实现,我们自己也可以想到一二点可以优化的地方。
这就是思考方式。提出问题 > 列出问题点 > 列出优化方法 > 列出具体可切入的点 > tradeoff和细化实现。
今天作为 《Kafka 性能提升的 7 大秘诀》系列的开篇,先从零拷贝技术说起。
传统 I/O
在说零拷贝之前,我们先了解下传统 I/O 在 Linux 系统中如何运行的。
传统的访问方式是通过 write()和 read() 两个系统调用实现的,通过 read()函数读取文件到到缓存区中,然后通过 write() 方法把缓存中的数据输出到网络端口。伪代码如下。
readFile(file_fd, buffer)
write(socket_fd, buffer)从 Kafka 的 Consumer 消费消息过程中, Broker 读取磁盘数据,接着通过 write 把缓存中的数据发送 Consumer 的场景来看,如果使用传统的 IO 模型,这一过程通常涉及以下几个步骤:
读取数据:通过
read系统调用将磁盘数据通过 DMA copy 到内核空间缓冲区(Read buffer)。拷贝数据:将数据从内核空间缓冲区(Read buffer) 通过 CPU copy 到用户空间缓冲区(Application buffer)。
写入数据:通过
write()系统调用将数据从用户空间缓冲区(Application) CPU copy 到内核空间的网络缓冲区(Socket buffer)。发送数据:将内核空间的网络缓冲区(Socket buffer)DMA copy 到网卡目标端口,通过网卡将数据发送到目标主机。
这一过程经过的四次 copy 如图 1 所示。
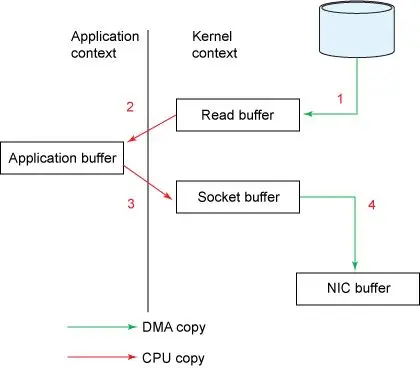
图 1
图 1 整个过程涉及 2 次 CPU 拷贝、2 次 DMA 拷贝,总共 4 次拷贝。还有 4 次上下文切换,如图 2 所示。















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









