








raw_data=pd.read_table("E:/data/book/python_book/chapter6/products_sales.txt",delimiter=",")1.查看数据样例,raw_data.tail(2)) 或者 head
2.查看数据概况 print(raw_data.describe().round(1).T) T 应该是转换行列的方法
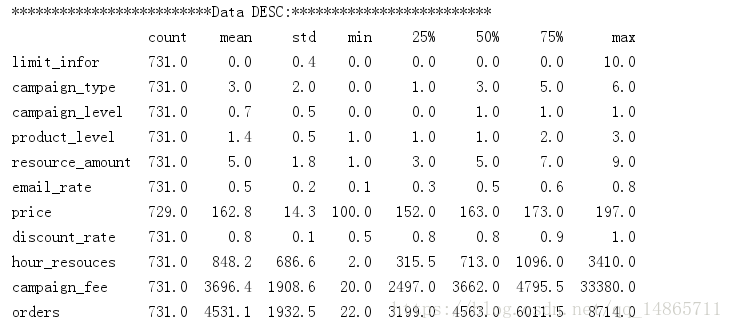
count 统计有值的数量 可以看到那些列存在空值
mean 求列均值
std 标准差
min 最小值
25%
50%
75% 猜想应该和四分位数相关(后续确定)
max 最大值
.异常值域分布,查看分类变量的值域分布
col_names=["limit_infor","campaign_type","campaign_level","product_level"]
for col_name in col_names:
unque_value=np.sort(raw_data[col_name].unique())#获取列的唯一值
print('{:*^50}'.format('{1} unique values:{0}').format(unque_value,col_name))
3.缺失值审查
#缺失值审查
na_cols=raw_data.isnull().any(axis=0) #查看每一列是否有缺失值
print('{:*^60}'.format('NA Cols::'))
print(na_cols)#打印缺失值
na_lines=raw_data.isnull().any(axis=1) #查看每一列是否有缺失值
print('total number of NA lines is :{0}'.format(na_lines.sum()))
要点:
isnull()
any(axis=0) #查看每一列是否有缺失值
any(axis=1) #查看每一列是否有缺失值
sum() 对象求和 true 为1 false为0 参与计算
4.变量的共线性检查
print('{:*^60}'.format('Correlation Analyze:'))
short_name=['li','ct','cl','pl','ra','er','price','dr','hr','cf','orders']
long_name=raw_data.columns
print(long_name)
name_dict=dict(zip(long_name,short_name))
print(raw_data.corr().round(2).rename(index=name_dict,columns=name_dict))
print(name_dict)
核心方法 raw_data.corr() 相关性分析
https://blog.csdn.net/lll1528238733/article/details/75114360
发现er和ra 相关性较强 后续需要做处理 (使用特定算法或者降维)















 1067
1067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









