






算法
dfs
test 1
给你一个大小为 m x n 的二进制矩阵 grid 。岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。岛屿的面积是岛上值为 1 的单元格的数目。
计算并返回 grid 中最大的岛屿面积。如果没有岛屿,则返回面积为 0 。
示例1: 输入:grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]] 输出:6 示例2: 输入:grid = [[0,0,0,0,0,0,0,0]] 输出:0
class Solution {
int[] dx = new int[]{0,0,-1,1};
int[] dy = new int[]{-1,1,0,0};
public int maxAreaOfIsland(int[][] grid) {
int max = 0;
for(int i=0;i<grid.length;i++){
for(int j=0;j<grid[0].length;j++){
if(grid[i][j]==1){
int count = dfs(grid,i,j);
if(count>max){
max = count;
}
}
}
}
return max;
}
public int dfs(int[][] grid, int y, int x){
if(!(y>=0 && x>=0 && y<grid.length && x<grid[0].length && grid[y][x]==1)){
return 0;
}
grid[y][x]=0;
int ans = 1;
for(int i=0;i<4;i++){
int x1 = x+dx[i];
int y1 = y+dy[i];
ans += dfs(grid,y1,x1);
}
return ans;
}
}可以作为模板,需要统计数量就添加ans变量,只需修改二维数组就不用ans
test 2
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。初始状态下,所有 next 指针都被设置为 NULL。
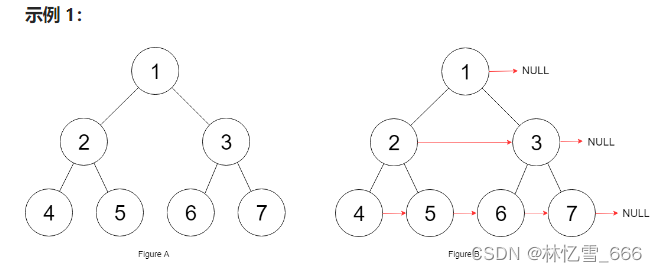
示例1: 输入:root = [1,2,3,4,5,6,7] 输出:[1,#,2,3,#,4,5,6,7,#] 解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,'#' 标志着每一层的结束。 示例2: 输入:root = [] 输出:[]
/*
// Definition for a Node.
class Node {
public int val;
public Node left;
public Node right;
public Node next;
public Node() {}
public Node(int _val) {
val = _val;
}
public Node(int _val, Node _left, Node _right, Node _next) {
val = _val;
left = _left;
right = _right;
next = _next;
}
};
*/
class Solution {
public Node connect(Node root) {
if(root==null){
return null;
}
if(root.left!=null){
root.left.next = root.right;
if(root.next!=null){
root.right.next = root.next.left;
}
connect(root.left);
connect(root.right);
}
return root;
}
}在dfs的基础上,visit()方法换成实际的业务逻辑。上层简历了next后,可以通过上层的next简历兄弟节点的子节点之间的next
滑动窗口
test 1
给你两个字符串 s1 和 s2 ,写一个函数来判断 s2 是否包含 s1 的排列。如果是,返回 true ;否则,返回 false 。换句话说,s1 的排列之一是 s2 的 子串 。
class Solution {
public boolean checkInclusion(String s1, String s2) {
int s1len = s1.length();
int s2len = s2.length();
if(s1len>s2len){
return false;
}
int[] next1 = new int[26];
int[] next2 = new int[26];
for(int i=0;i<s1len;i++){
next1[s1.charAt(i)-'a']++;
next2[s2.charAt(i)-'a']++;
}
if(Arrays.equals(next1,next2)){
return true;
}
for(int i=s1len;i<s2len;i++){
next2[s2.charAt(i)-'a']++;
next2[s2.charAt(i-s1len)-'a']--;
if(Arrays.equals(next1,next2)){
return true;
}
}
return false;
}
}Arrays.equals(next1,next2); //判断两个数组是否相等,判断一个字符串是否是另一个字符串的排列,可先初始化两个next数组,在使用该方法判断两个数组相等就是排列。
固定窗口大小的滑动窗口:先初始化窗口,按照窗口大小,前面加一个元素,后面就删一个元素。
test 2
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
class Solution {
public int lengthOfLongestSubstring(String s) {
int length = s.length();
int[] next = new int[128];
Arrays.fill(next,-1);
int max = 0;
int left = 0;
for(int right=0;right<length;right++){
if(next[s.charAt(right)]!=-1 && left<next[s.charAt(right)]+1){
left = next[s.charAt(right)]+1;
}
next[s.charAt(right)] = right;
int len = right-left+1;
if(len>max){
max = len;
}
}
return max;
}
}使用next数组进行模式匹配
链表
test 1
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例1: 输入:head = [1,2,3,4,5] 输出:[5,4,3,2,1] 示例2: 输入:head = [1,2] 输出:[2,1] 示例3: 输入:head = [] 输出:[]
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
if(head==null){
return head;
}
ListNode pre = null;
ListNode index = head;
ListNode next = null;
while(index!=null){
next = index.next;
index.next = pre;
pre = index;
index = next;
}
return pre;
}
}SQL
test 1
某网站包含两个表,Customers 表和 Orders 表。编写一个 SQL 查询,找出所有从不订购任何东西的客户。
Customers
+----+-------+
| Id | Name |
+----+-------+
| 1 | Joe |
| 2 | Henry |
| 3 | Sam |
| 4 | Max |
+----+-------+
Orders
+----+------------+
| Id | CustomerId |
+----+------------+
| 1 | 3 |
| 2 | 1 |
+----+------------+
result
+-----------+
| Customers |
+-----------+
| Henry |
| Max |
+-----------+不在枚举内:not in
select Name as Customers from Customers where Id not in (select CustomerId from Orders);test 2
编写一个 SQL 删除语句来 删除 所有重复的电子邮件,只保留一个id最小的唯一电子邮件。以 任意顺序 返回结果表。注意: 仅需要写删除语句,将自动对剩余结果进行查询。
Person
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| email | varchar |
+-------------+---------+
id是该表的主键列。
该表的每一行包含一封电子邮件。电子邮件将不包含大写字母。Person
+----+------------------+
| id | email |
+----+------------------+
| 1 | john@example.com |
| 2 | bob@example.com |
| 3 | john@example.com |
+----+------------------+
result
+----+------------------+
| id | email |
+----+------------------+
| 1 | john@example.com |
| 2 | bob@example.com |
+----+------------------+内连接删除:delete 表名 from 表名 p1,表名 p2 where ...
delete p1 from Person p1,Person p2 where p1.email=p2.email and p1.id>p2.id;test3
写一个查询语句,返回一个客户列表,列表中客户的推荐人的编号都 不是 2。
customer
+------+------+-----------+
| id | name | referee_id|
+------+------+-----------+
| 1 | Will | NULL |
| 2 | Jane | NULL |
| 3 | Alex | 2 |
| 4 | Bill | NULL |
| 5 | Zack | 1 |
| 6 | Mark | 2 |
+------+------+-----------+
result
+------+
| name |
+------+
| Will |
| Jane |
| Bill |
| Zack |
+------+在MySQL中,null和有值属于两种数据类型,判断不等于时,会去除值为null的记录,所以查询某一字段不为某个值,查询条件需要加上:字段名 is null
select name from customer where referee_id <> 2 or referee_id is null;test4
请你编写一个 SQL 查询来交换所有的 'f' 和 'm' (即,将所有 'f' 变为 'm' ,反之亦然),仅使用 单个 update 语句 ,且不产生中间临时表。注意,你必须仅使用一条 update 语句,且 不能 使用 select 语句。
Salary
+-------------+----------+
| Column Name | Type |
+-------------+----------+
| id | int |
| name | varchar |
| sex | ENUM |
| salary | int |
+-------------+----------+
id 是这个表的主键。
sex 这一列的值是 ENUM 类型,只能从 ('m', 'f') 中取。
本表包含公司雇员的信息。Salary
+----+------+-----+--------+
| id | name | sex | salary |
+----+------+-----+--------+
| 1 | A | m | 2500 |
| 2 | B | f | 1500 |
| 3 | C | m | 5500 |
| 4 | D | f | 500 |
+----+------+-----+--------+
result
+----+------+-----+--------+
| id | name | sex | salary |
+----+------+-----+--------+
| 1 | A | f | 2500 |
| 2 | B | m | 1500 |
| 3 | C | f | 5500 |
| 4 | D | m | 500 |
+----+------+-----+--------+按条件修改:case判断字段sex的值,当sex值为when中子句的值时,设为then中子句的值,否则设为else中子句的值,判断结束写end
update Salary
set sex=case sex
when 'f' then 'm'
else 'f' end;test5
编写一个 SQL 查询来查找每个日期、销售的不同产品的数量及其名称。每个日期的销售产品名称应按词典序排列。返回按 sell_date 排序的结果表。
Activities
+-------------+---------+
| 列名 | 类型 |
+-------------+---------+
| sell_date | date |
| product | varchar |
+-------------+---------+
此表没有主键,它可能包含重复项。
此表的每一行都包含产品名称和在市场上销售的日期。
Activities
+------------+-------------+
| sell_date | product |
+------------+-------------+
| 2020-05-30 | Headphone |
| 2020-06-01 | Pencil |
| 2020-06-02 | Mask |
| 2020-05-30 | Basketball |
| 2020-06-01 | Bible |
| 2020-06-02 | Mask |
| 2020-05-30 | T-Shirt |
+------------+-------------+
result
+------------+----------+------------------------------+
| sell_date | num_sold | products |
+------------+----------+------------------------------+
| 2020-05-30 | 3 | Basketball,Headphone,T-shirt |
| 2020-06-01 | 2 | Bible,Pencil |
| 2020-06-02 | 1 | Mask |
+------------+----------+------------------------------+去掉重复项:字段前加distinct
分组查询时,按分组将每组的数组转字符串:group_concat(字段名 separator ’,‘)
select
sell_date,
count(distinct product) as num_sold,
group_concat(distinct product order by product separator ',') products
from Activities
group by sell_date
order by sell_date;test6
编写一个 SQL 查询来修复名字,使得只有第一个字符是大写的,其余都是小写的。返回按 user_id 排序的结果表。
Users
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| user_id | int |
| name | varchar |
+----------------+---------+
user_id 是该表的主键。
该表包含用户的 ID 和名字。名字仅由小写和大写字符组成。Users
+---------+-------+
| user_id | name |
+---------+-------+
| 1 | aLice |
| 2 | bOB |
+---------+-------+
result
+---------+-------+
| user_id | name |
+---------+-------+
| 1 | Alice |
| 2 | Bob |
+---------+-------+字符串所有字母转大写:upper(str)
字符串所有字母转小写:lower(str)
从左开始截取长度为len的字符串:left(str,len)
从左开始截取长度为str长度-1的字符串:right(str,length(str)-1)
select
user_id,
concat(upper(left(name,1)),lower(right(name,length(name)-1))) name
from Users
order by user_id;test7
写出一个SQL 查询语句,计算每个雇员的奖金。如果一个雇员的id是奇数并且他的名字不是以'M'开头,那么他的奖金是他工资的100%,否则奖金为0。Return the result table ordered by employee_id。返回的结果集请按照employee_id排序。
Employees
+-------------+---------+
| 列名 | 类型 |
+-------------+---------+
| employee_id | int |
| name | varchar |
| salary | int |
+-------------+---------+
employee_id 是这个表的主键。
此表的每一行给出了雇员id ,名字和薪水。Employees
+-------------+---------+--------+
| employee_id | name | salary |
+-------------+---------+--------+
| 2 | Meir | 3000 |
| 3 | Michael | 3800 |
| 7 | Addilyn | 7400 |
| 8 | Juan | 6100 |
| 9 | Kannon | 7700 |
+-------------+---------+--------+
result
+-------------+-------+
| employee_id | bonus |
+-------------+-------+
| 2 | 0 |
| 3 | 0 |
| 7 | 7400 |
| 8 | 0 |
| 9 | 7700 |
+-------------+-------+字符串不以M开头:str not like ’M%‘
按条件返回查询值:if(条件表达式,value1,value2),符合条件返回value1,不符合返回value2。
select
employee_id,
if(employee_id%2=1 and name not like 'M%',salary,0) as bonus
from Employees order by employee_id;














 1942
1942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









