







前言:在机器学习训练完模型之后我们要考虑模型的效率问题,常用的模型效率分析手段有:
研究模型学习曲线,判断模型是否过拟合或者欠拟合,并做出相应的调整;
对于模型权重参数进行分析,对于权重绝对值高/低的特征,可以对特征进行更细化的工作,也可以进行特征组合;
进行bad-case分析,对错误的例子分析是否还有什么可以修改挖掘
模型融合:模型融合就是训练多个模型,然后按照一定的方法集成过个模型,应为它容易理解、实现也简单,同时效果也很好,在工业界的很多应用,在天池、kaggle比赛中也经常拿来做模型集成。
这篇文章主要机器学习中的模型融合,包括bagging,Boosting两种思想的方法。
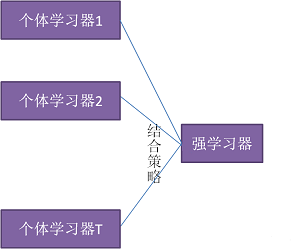
一、模型融合的认识、分析:1,模型融合的概念:下图介绍了模型融合的一般结构:先产生一组”个体学习器,再用某种策略将它们结合起来,加强模型效果。
2,模型融合应用广发的原因:可以通过数学证明模型,随着集成中个体分类器数目T的增大,集成的错误率将指数级下降,最终趋向于零。具体证明在周志华和李航老师的书中都有。
3,模型融合的条件:个体学习器准确性越高、多样性越大,则融合越好。(
,E代表融合后的误差加权均值,
代表个体学习器的误差加权均值,
代表模型的多样性,也就是各个模型之间的分歧值)
BaseModel之间的相关性要尽可能的小。这就是为什么非Tree-basedModel往往表现不是最好但还是要将它们包括在Ensemble里面的原因。Ensemble的Diversity越大,最终Model的Bias就越低。BaseModel之间的性能表现不能差距太大。这其实是一个Trade-off,在实际中很有可能表现相近的Model只有寥寥几个而且它们之间相关性还不低。但是实践告诉我们即使在这种情况下Ensemble还是能大幅提高成绩。
4,模型融合的分类:按照个体学习器的关系可以分为两类:
个体学习器问存在强依赖关系、必须串行生成的序列化方法,代表Boosting方法;
个体学习器间不存在强依赖关系、可同时生成的并行化方法,代表是Bagging 和”随机森林” 。
二、个体学习器依赖的融合-boosting:1,boosting方法的思想:Boosting算法的工作机制是首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2;如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
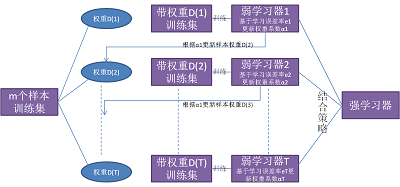
2,Boosting系列算法里最著名算法主要有AdaBoost算法和提升树(boostingtree)系列算法。提升树系列算法里面应用最广泛的是梯度提升树(GradientBoostingTree)。
AdaBoost算法:是加法模型、损失函数为指数函数、学习算法为前向分布算法时的二分类算法。
提升树:是加法模型、学习算法为前向分布算法时的算法。不过它限定基本学习器为决策树。对于二分类问题,损失函数为指数函数,就是把AdaBoost算法中的基本学习器限定为二叉决策树就可以了;对于回归问题,损失函数为平方误差,此时,拟合的是当前模型的残差。
梯度提升树:是对提升树算法的改进,提升树算法只适合误差函数为指数函数和平方误差,对于一般的损失函数,梯度提升树算法利用损失函数的负梯度在当前模型的值,作为残差的近似值。(GBDT算法有两种描述思路,一个是基于残差的版本(当损失函数是均方差损失时,因为对均方差求导后就是2(y-y_hat)就是真实值和预测值得残差方向,一个是基于梯度gradient的版本(当损失函数是其它损失函数时,例如交叉熵损失)。说白了都是基于梯度的,只不过均方差求导后变成残差了)
三、个体学习器不依赖依赖的融合-bagging:1,bagging方法的思想:bagging算法的思想是通过对样本采样的方式,使我们的基本学习器存在较大的差异。
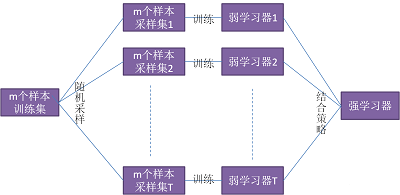
2,bagging系类算法常见有bagging算法和随机深林算法
bagging算法:采用的是自助采样法(Bootstapsampling),即对于m个样本的原始训练集,我们每次先随机采集一个样本放入采样集,接着把该样本放回,也就是说下次采样时该样本仍有可能被采集到,这样采集m次,最终可以得到m个样本的采样集,由于是随机采样,这样每次的采样集是和原始训练集不同的,和其他采样集也是不同的,这样得到多个不同的弱学习器。
随机森林:是对bagging算法的改进。改进一:基本学习器限定为决策树,改进二:除了bagging的在样本上加上扰动,同时在属性上也加上扰动,即是在决策树学习的过程中引入了随机属性选择,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。
四、模型融合的结合策略:基本学习器学习完后,需要将各个模型进行融合,常见的策略有:
1,平均法:平均法有一般的评价和加权平均,这个好理解。对于平均法来说一般用于回归预测模型中,在Boosting系列融合模型中,一般采用的是加权平均融合。
2,投票法:有绝对多数投票(得票超过一半),相对多数投票(得票最多),加权投票。这个也好理解,一般用于分类模型。在bagging模型中使用。
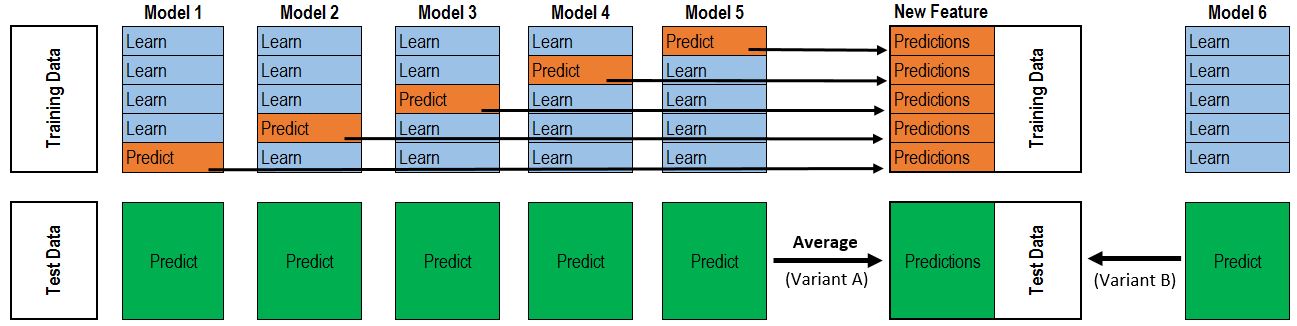
3,学习法:一种更为强大的结合策略是使用”学习法”,即通过另一个学习器来进行结合,把个体学习器称为初级学习器,用于结合的学习器称为次级学习器或元学习器。常见的有Stacking和Blending两种(1)Stacking方法:Stacking先从初始数据集训练出初级学习器,然后”生成”一个新数据集用于训练次级学习器。在这个新数据集中,初级学习器的输出被当作样例输入特征,而初始样本的标记仍被当作样例标记。stacking一般使用交叉验证的方式,初始训练集D被随机划分为k个大小相似的集合D1,D2,…,Dk,每次用k-1个部分训练T个模型,对另个一个部分产生T个预测值作为特征,遍历每一折后,也就得到了新的特征集合,标记还是源数据的标记,用新的特征集合训练一个集合模型。
五、多样性增强:模型的多样性可以改善融合后的效果,增强的手段有:
数据样本的扰动:bagging中提到的给定初始数据集, 可从中产生出不同的数据子集, 再利用不同的数据子集训练出不同的个体学习器。
输入属性的扰动:随机深林提到的使用控制属性的子空间的不同,产生差异较大的模型。
输出表示的扰动:输出表示进行操纵以增强多样性,可对训练样本的类标记稍作变动。
算法参数的扰动:基学习算法一般都有参数需进行设置,例如神经网络的隐层神经元数、初始连接权值等,通过随机设置不同的参数,往往可产生差别较大的个体学习器。















 903
903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









