






1.概述
通过工作流 ,可视化界面快速构建复杂的工作流和自动化流程。结合文档识别技术和工作流引擎,可以实现文档的自动识别、数据提取后对比知识库的信息,提示文档的内容是否正确,减少认为判断错误的误差。
2.需求分析
- 文档提取:自动从PDF文档中提取关键信息(本文是维修单,包含设备名称、规格型号、所属部门等信息)。
- 数据验证:对提取的数据与知识库进行比对,知识库包含设备的一些基本信息,对错误信息进行提示,确保其准确性和完整性
3.技术选型
deepseek+Dify
4. 实现步骤
4.1 设计工作流
step1 创建开始节点 字段类型选择单文件,支持的文件类型选文档
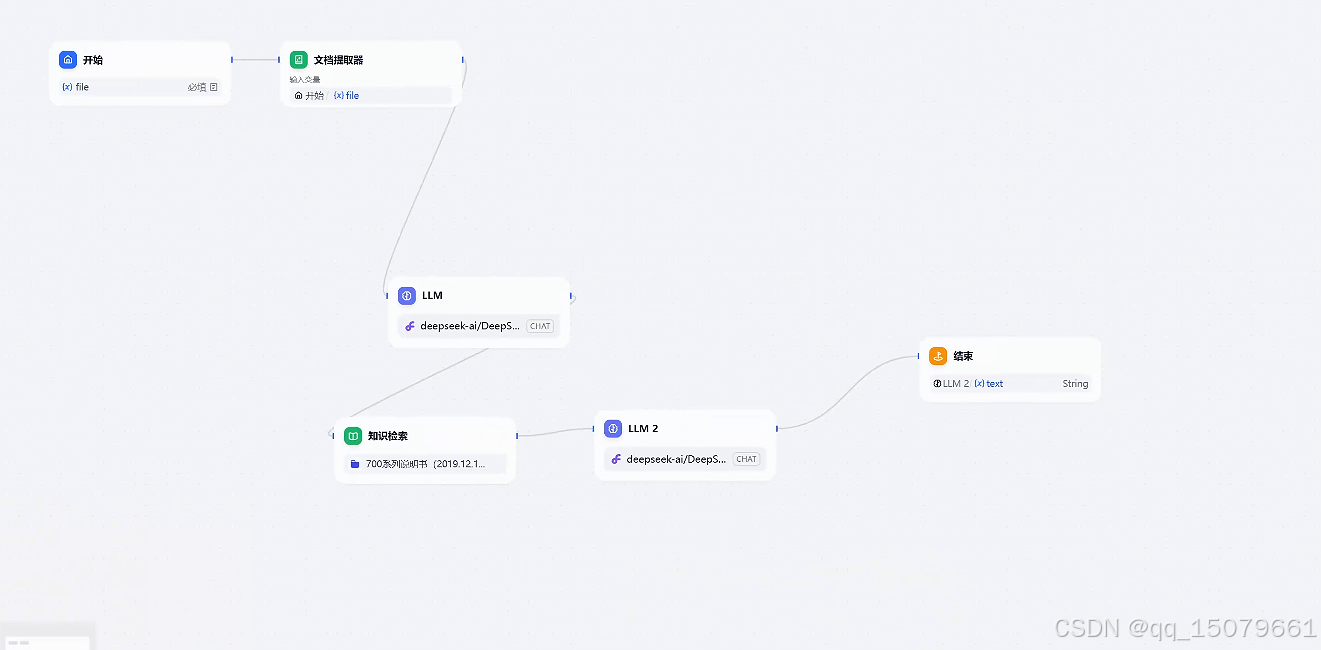
step2 点击+号,选择知识检索
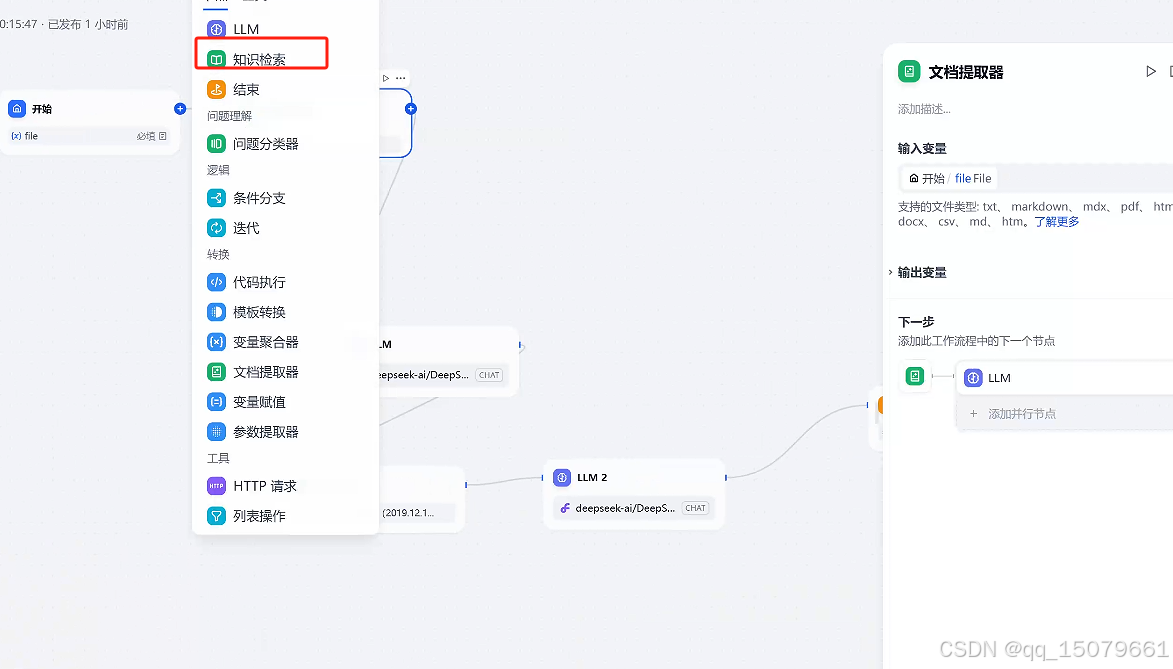
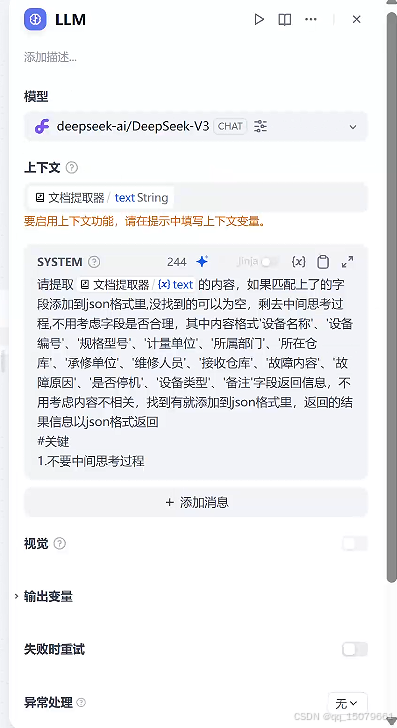
step3 点击+号,选择LLM,提示词为
step4 点击+号,选择知识检索,点击+号选择已经上传的知识库,本实例的知识库是设备维修说明书
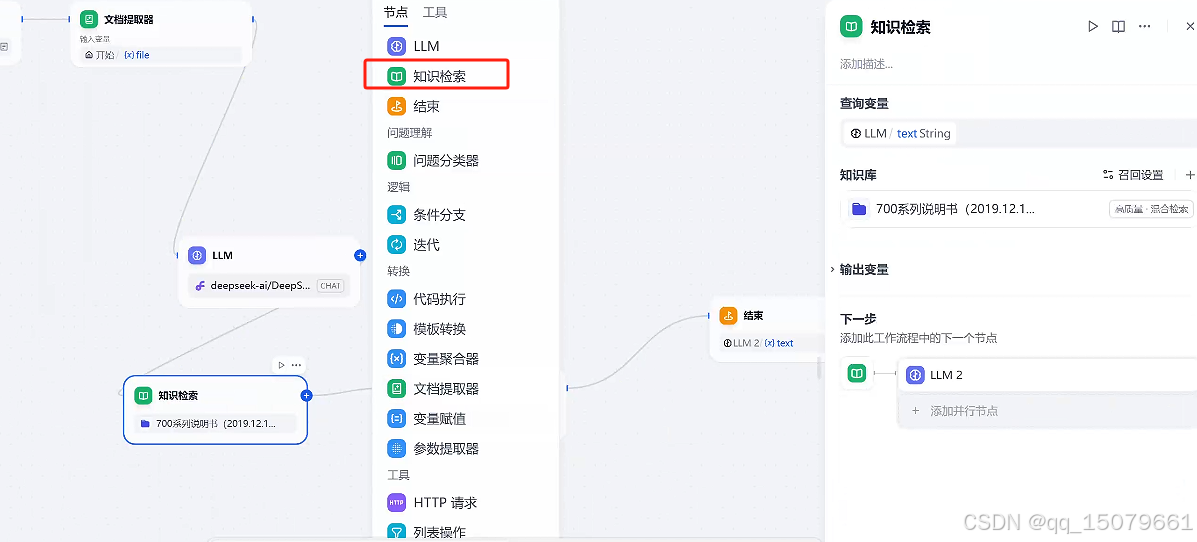
step5 选择LLM,这个节点主要处理json数据和知识库的内容进行比对
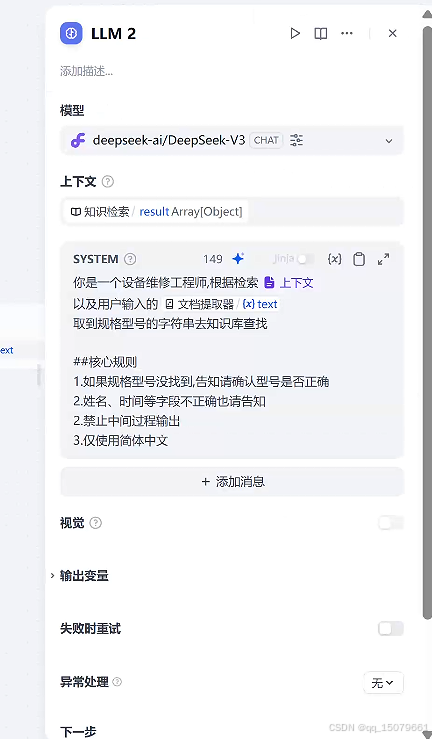
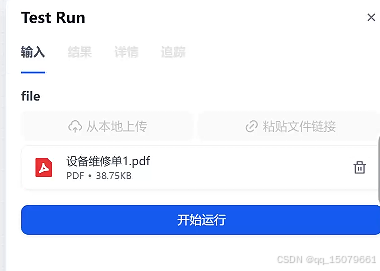
step6 运行,上传维修单,输出结果



















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









