







环境配置:VMware10 + CentOS 6.5 + JDK1.7.0_67 + Hadoop 2.5.0
注意:
①除必须外,一定要使用普通用户操作;
②hadoop的相关命令在没有配置其环境变量的情况下,需要在相应的脚本文件目录操作;
③涉及浏览器访问的要使用主流浏览器(如Google Chrome);
一、系统环境准备工作
1、把网卡IP设置成静态(NAT模式)
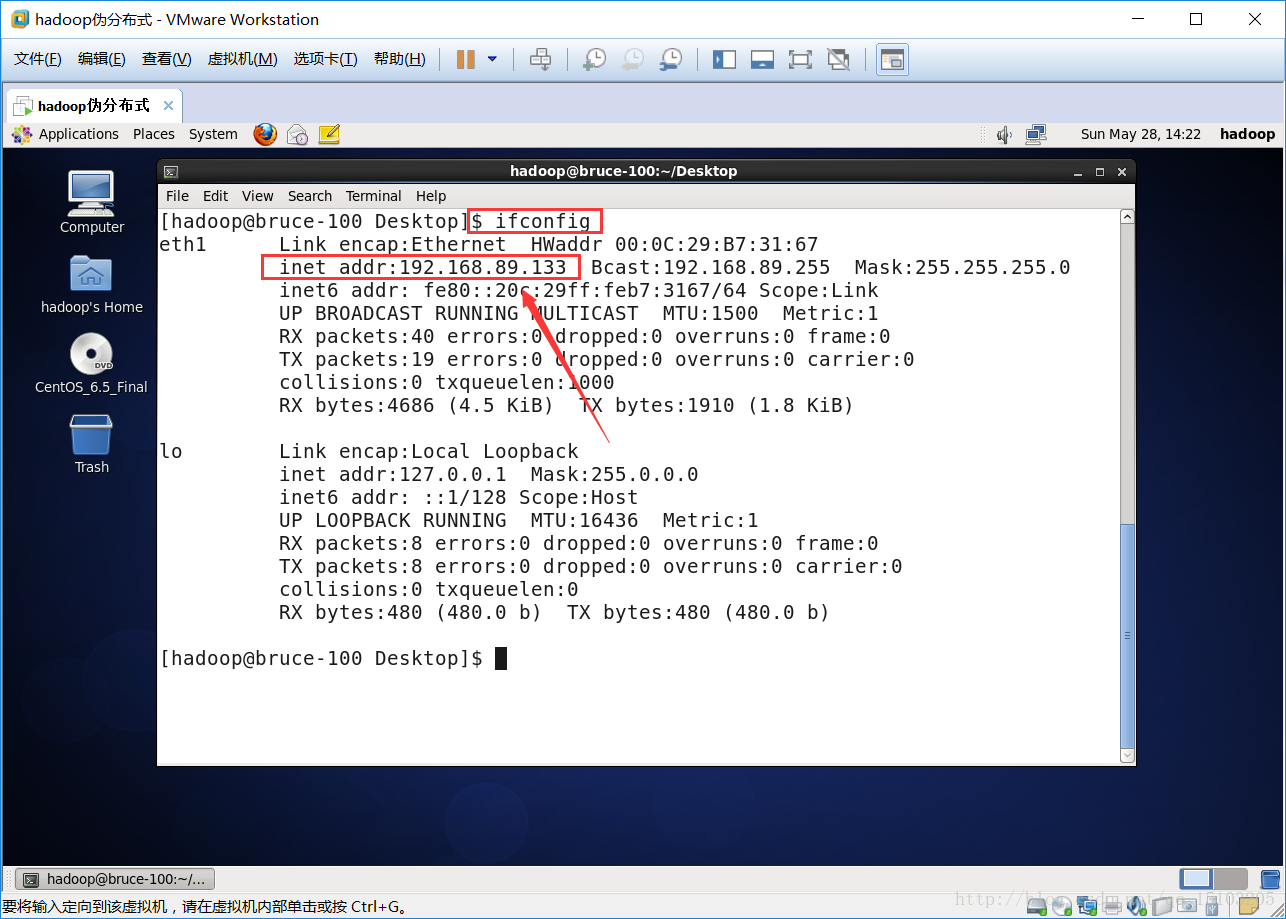
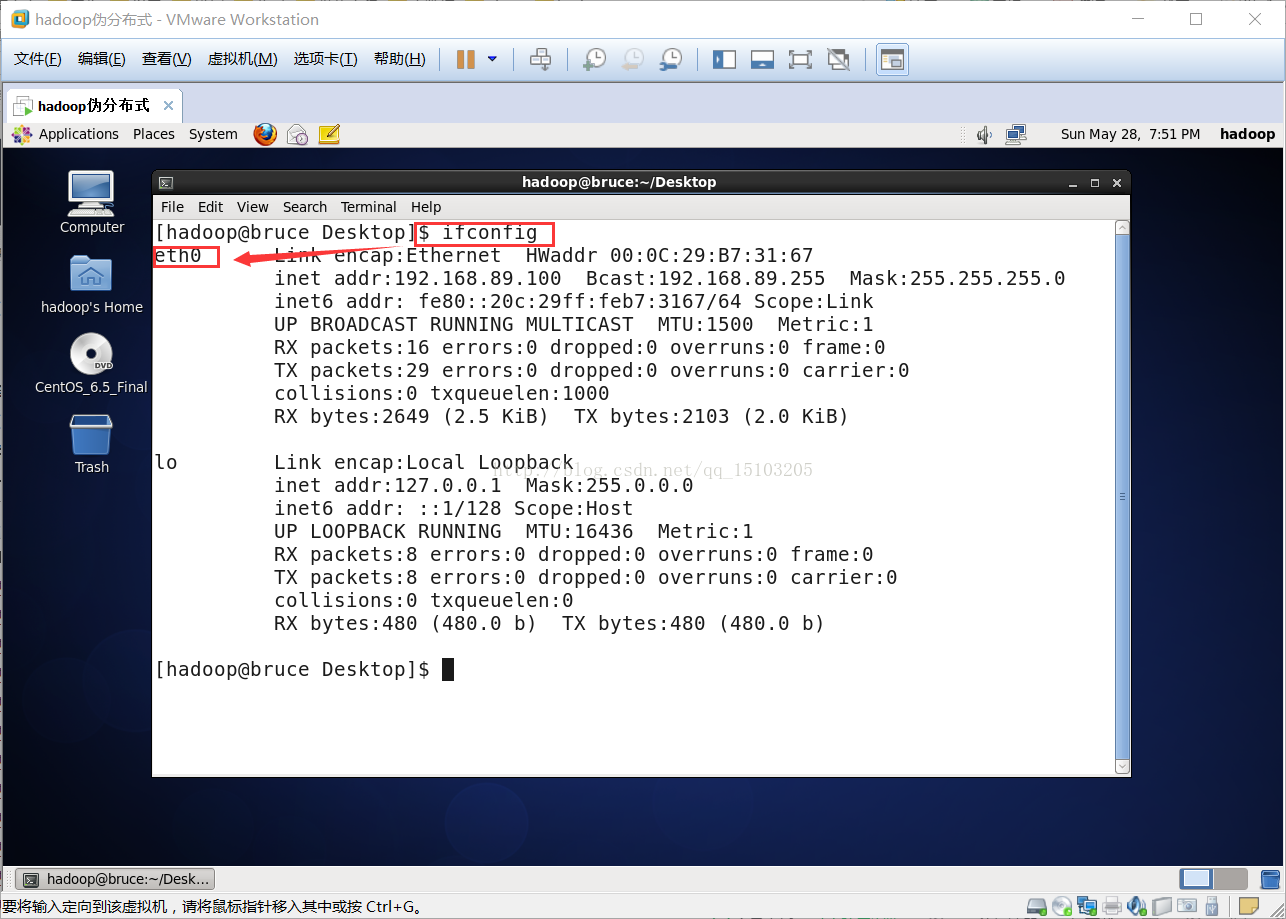
⑴查看网卡IP:ip a或者ifconfig
⑵配置VPN(Virtual Private Network 虚拟专用网络)
①查看NAT模式子网IP、子网掩码、网关IP;
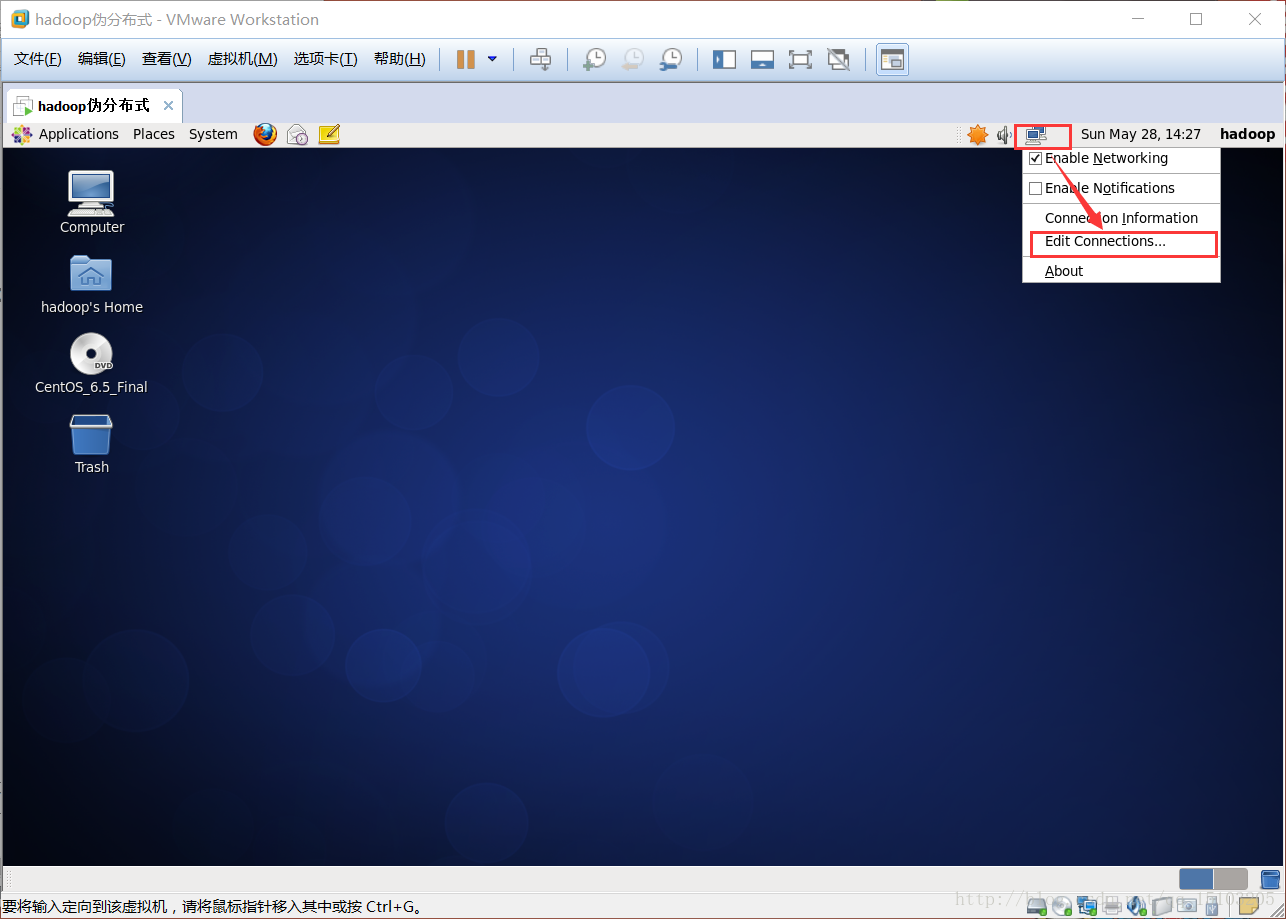
②右键选择网络图标,点击编辑连接;
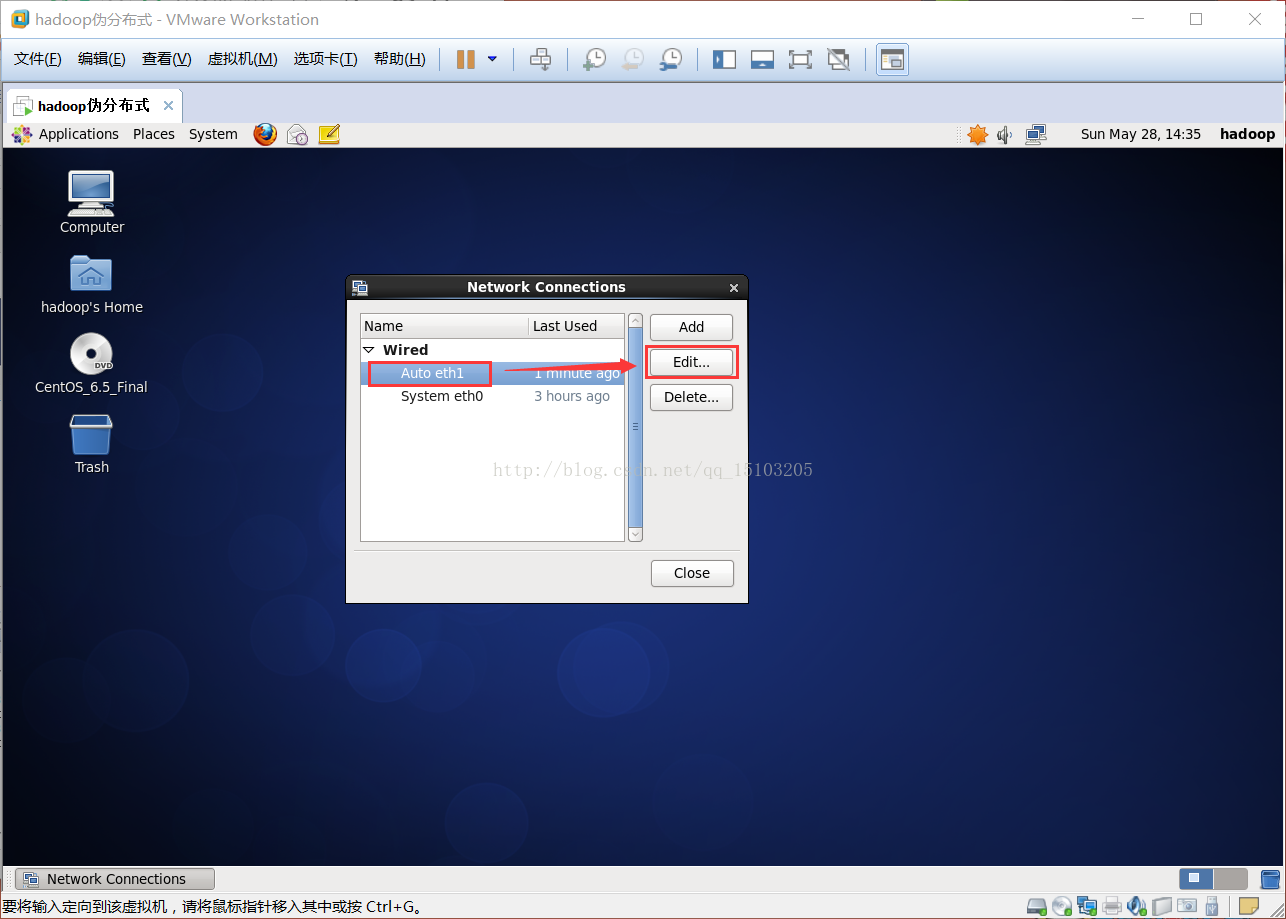
③配置VPN(网卡名称默认为“System eth0”,如果只有一个网卡,直接编辑即可,如果有多个网卡,则先删除默认名称的网卡,再选择名为“Auto eth1”的网卡编辑;通常新创建的虚拟机只有一个默认网卡,如果是克隆的虚拟机则自动生成新网卡“Auto eth1”)
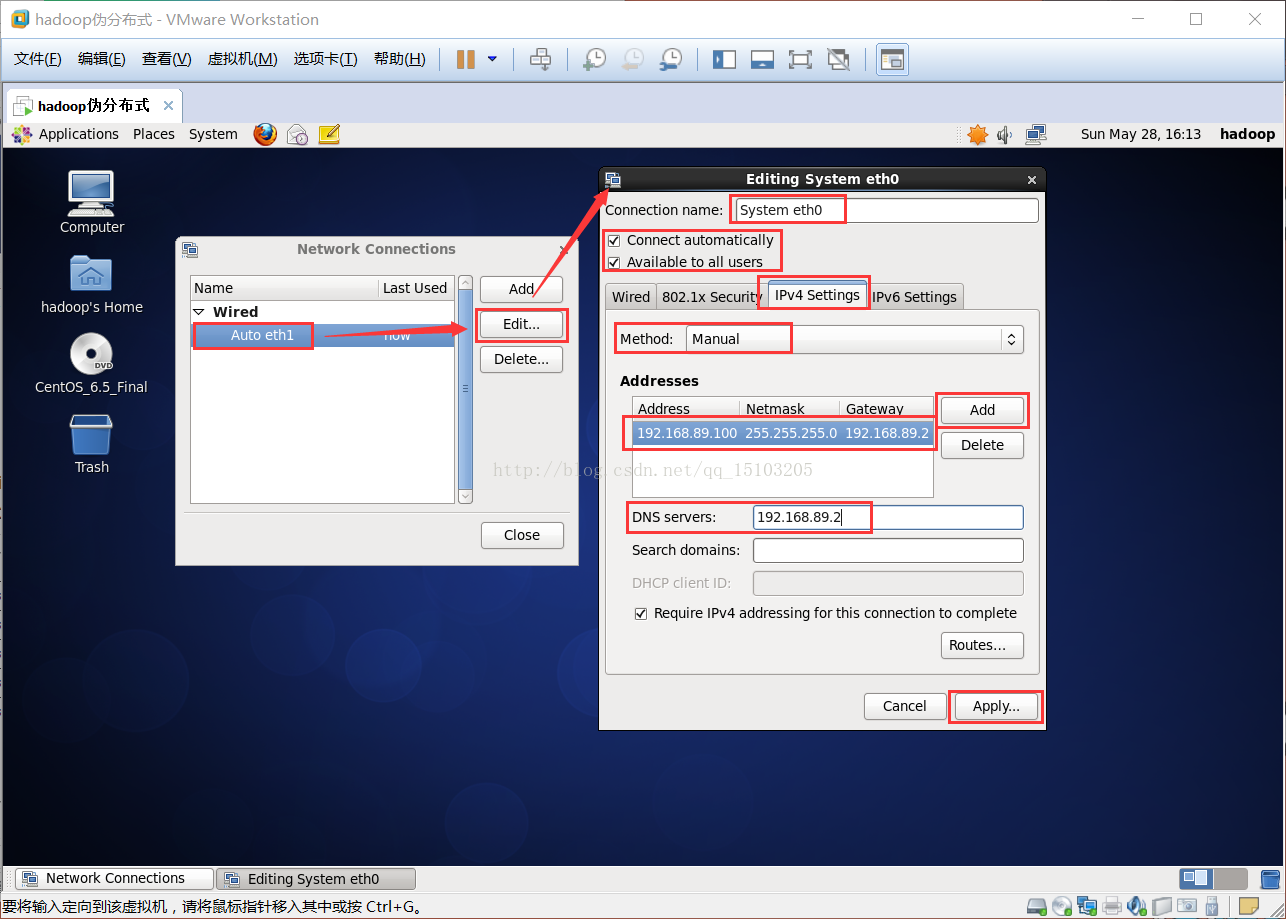
④IPV4页面设置;方法:手动;添加:地址 子网掩码 网关;DNS服务器;(需要root权限确认)


2、网卡配置
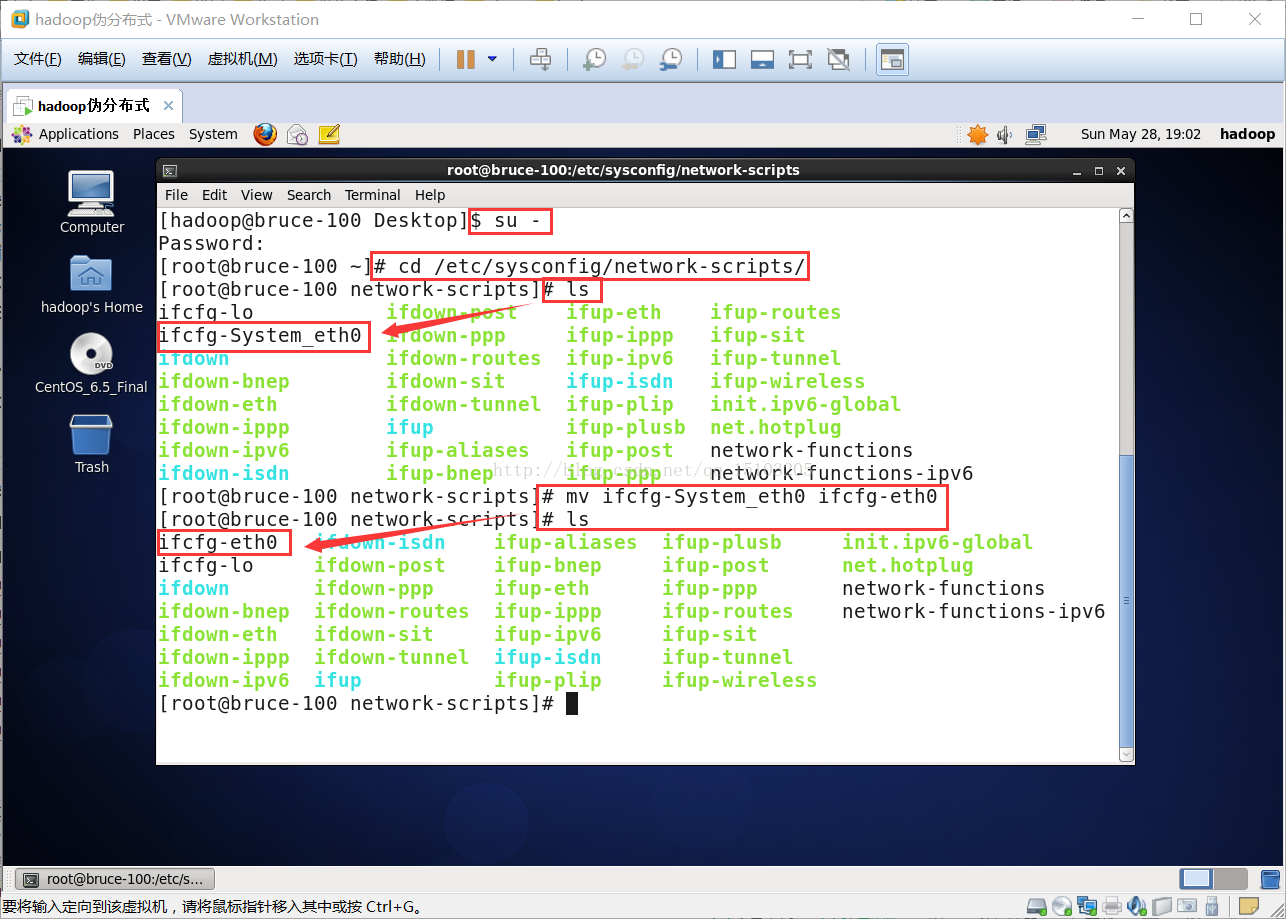
⑴修改网卡文件
# vi /etc/sysconfig/network-scripts/ifcfg-eth0
注意:克隆的虚拟机ifcfg-eth0文件名发生了变化,可以先到目录下# cd /etc/sysconfig/network-scripts/,发现类似文件重命名为ifcfg-eth0即可。
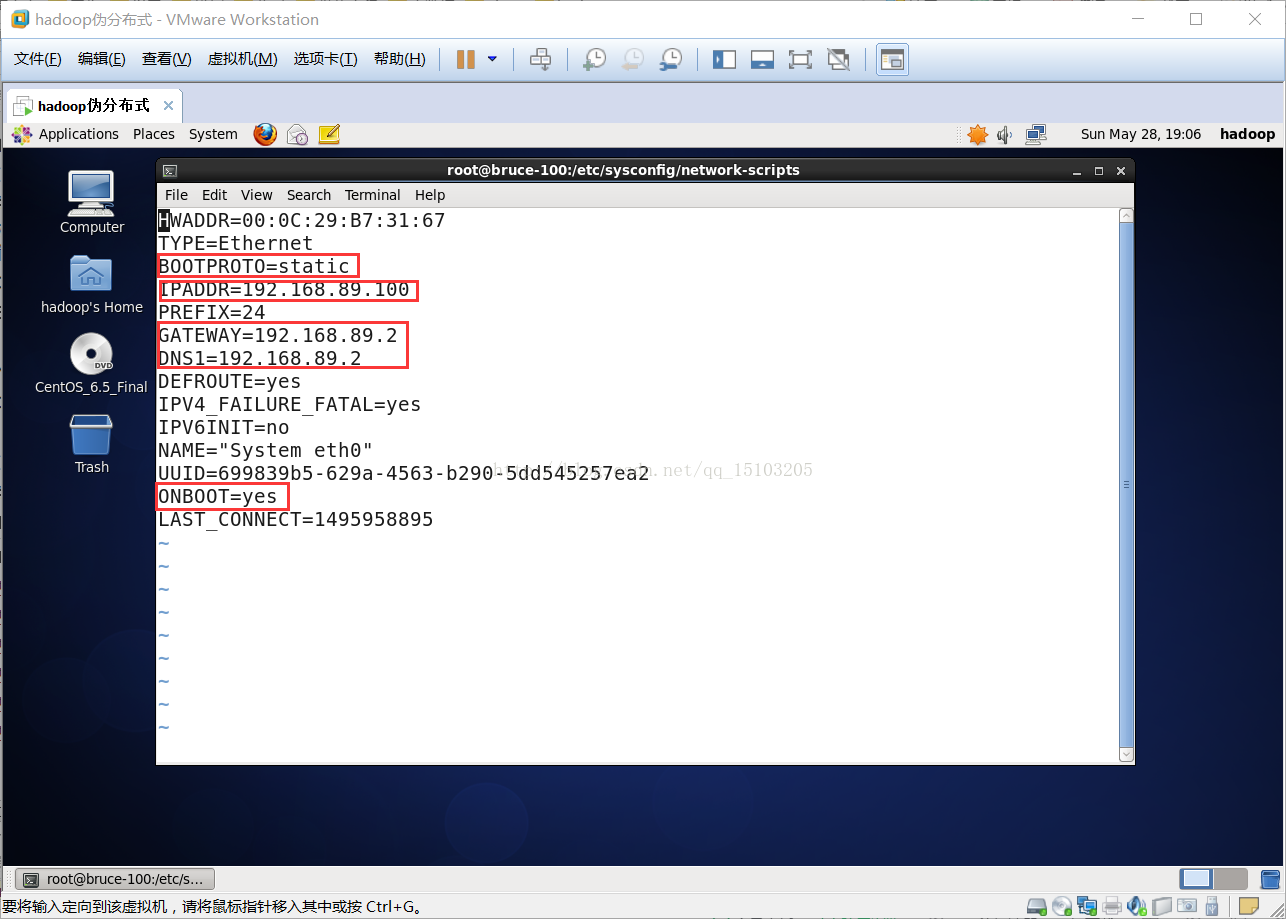
ONBOOT=yes (把网卡设置成开机启动)
BOOTPROTO=static (把DHCP改为static,Linux严格区分大小写,一定要注意)
IPADDR=192.168.89.100 (IP地址,网段下的3~255任选一即可)
NETMASK=255.255.255.0 (子网掩码,固定为255.255.255.0)
GATEWAY=192.168.89.2 (网关,前三位相同,末位设置为2,是NAT模式特有的做法)
DNS1=192.168.89.2 (同网关)
修改网卡信息
# vi /etc/udev/rules.d/70-persistent-net.rules
注意:无论是新创建的虚拟机还是通过克隆的虚拟机,设备的MAC地址是设备的唯一标识,这里如果有则需要删除原来的网卡信息,并修改现在的网卡信息NAME="eth0" 。
修改后:


⑵重启网卡
# ifup eth0 (Linux中eth0,eth1,eth2分别表示网卡一,网卡二,网卡三。。。)
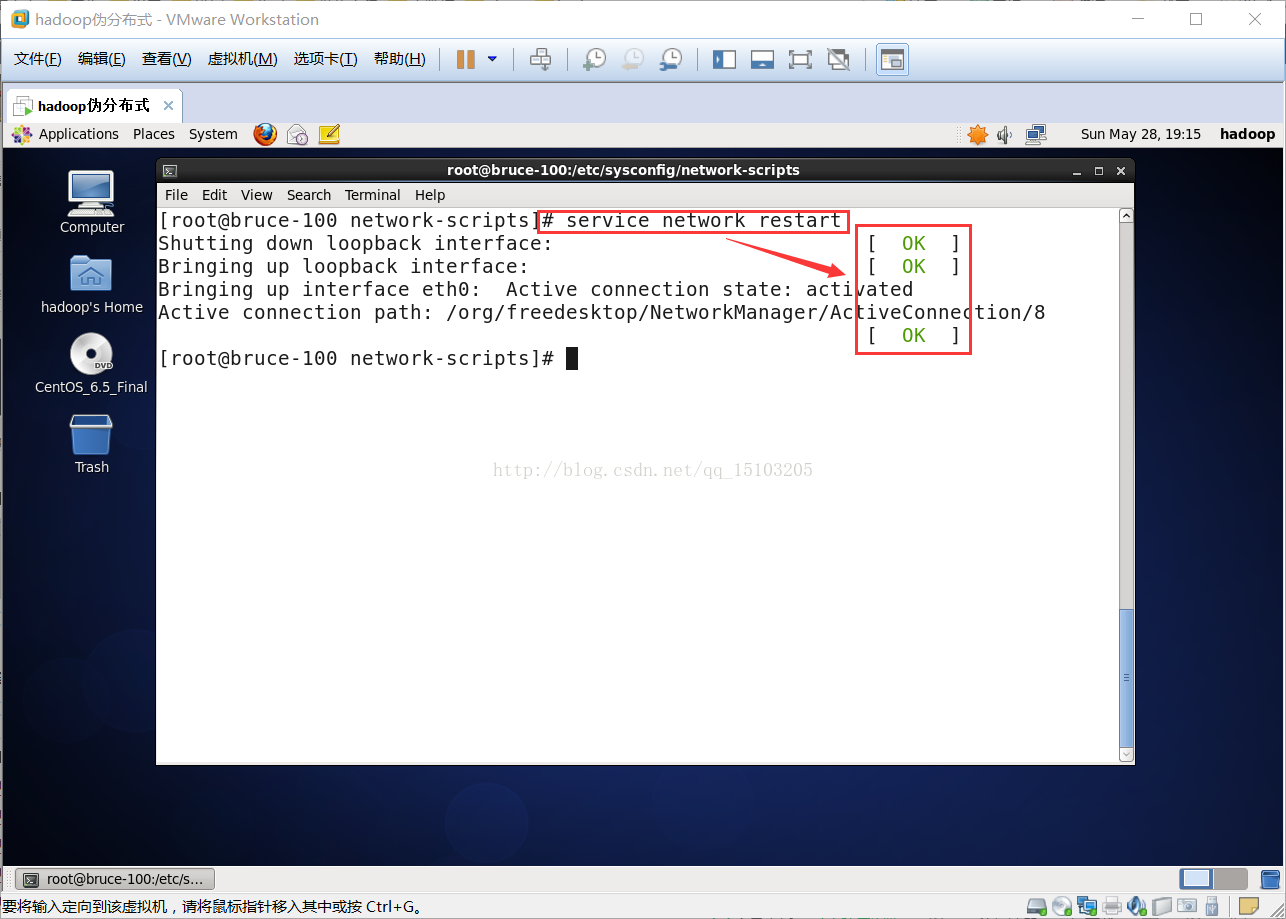
⑶重启网络服务
# service network restart
⑷重启虚拟机后的网卡

3、修改主机名(永久)
⑴修改主机名(虚拟机重启后生效)
# vi /etc/sysconfig/network
HOSTNAME=bruce.mydomain
修改后重启前主机名:

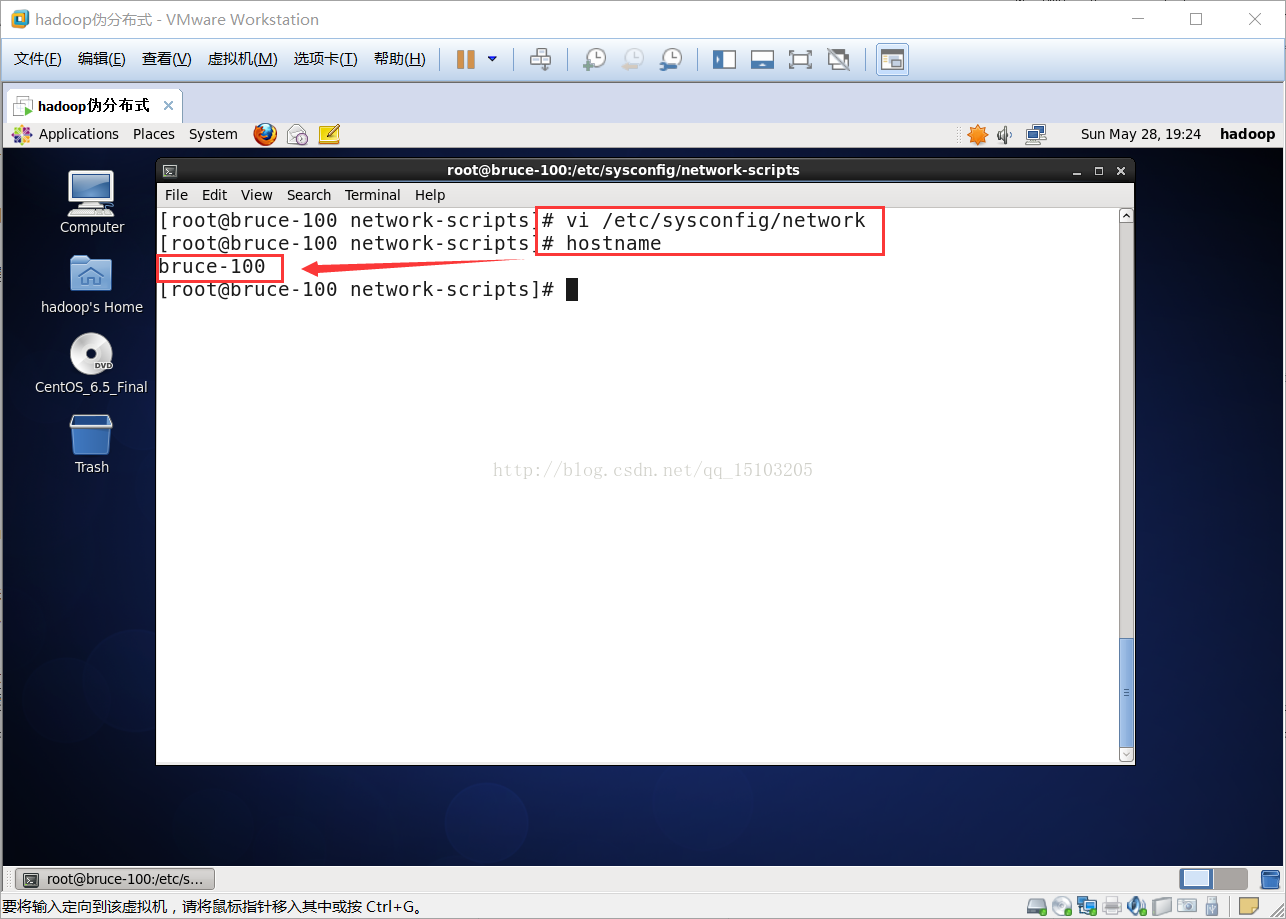
⑵重启后查看主机名
$ hostname

⑶注意:
①集群内部的主机名通常都会使用统一的命名格式;
②hadoop里主机名不能使用下划线;
③示例:bruce01.mydomain
bruce02.mydomain
bruce03.mydomain
4、添加主机名映射
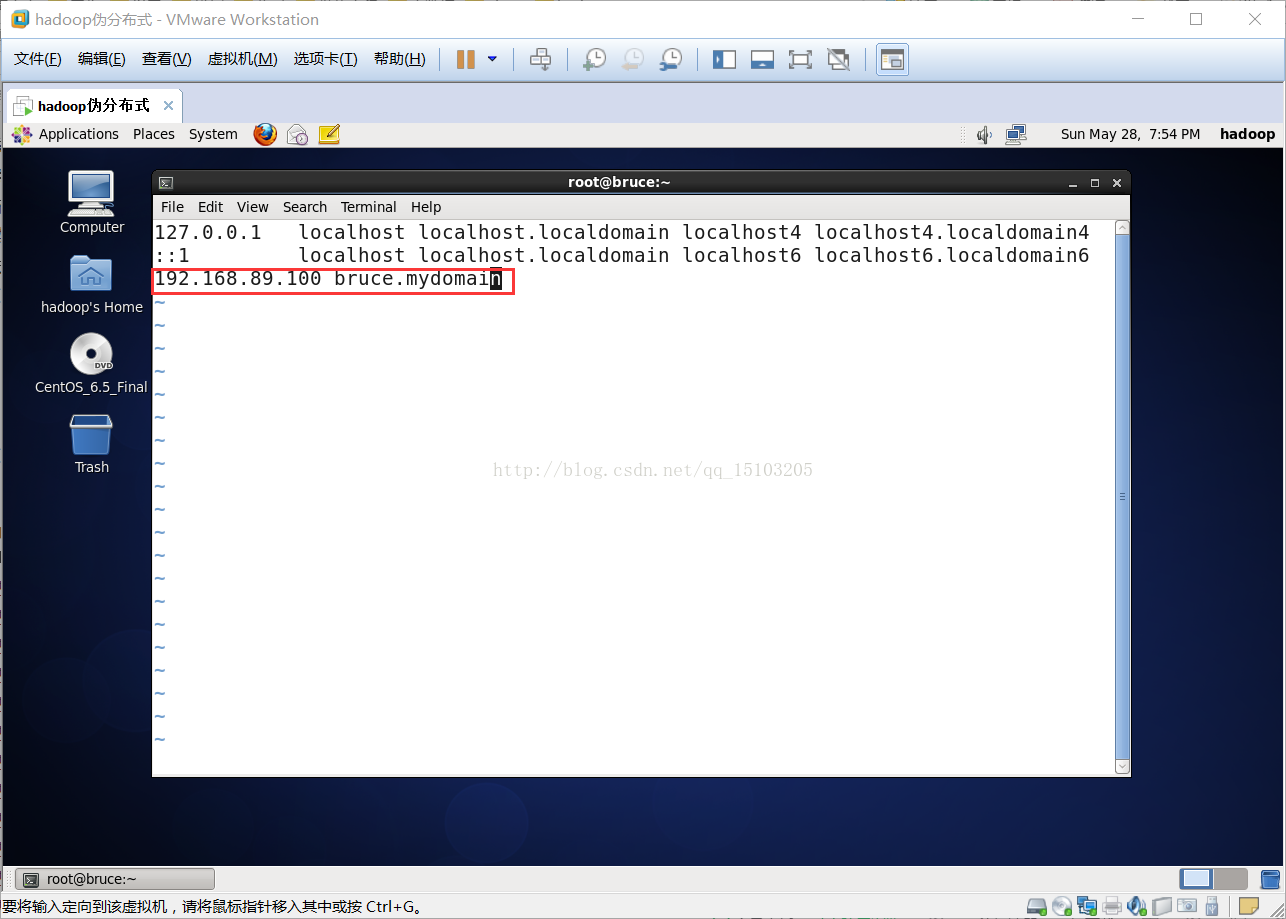
# vi /etc/hosts
注意:在最后一行添加:IP地址 主机名
如:192.168.89.100 bruce.mydomain
5、关闭Linux防火墙和selinux安全子系统
⑴关闭Linux防火墙
默认情况下,防火墙只开启了22号端口,会影响集群通讯
# service iptables stop (关闭防火墙服务)
# service iptables status (查看防火墙状态)
# chkconfig iptables off (设置为开机不启动)
拓展(不需要操作):
# chkconfig --list (列出所有的系统服务)
# chkconfig --list | grep iptables (查询某个系统服务)

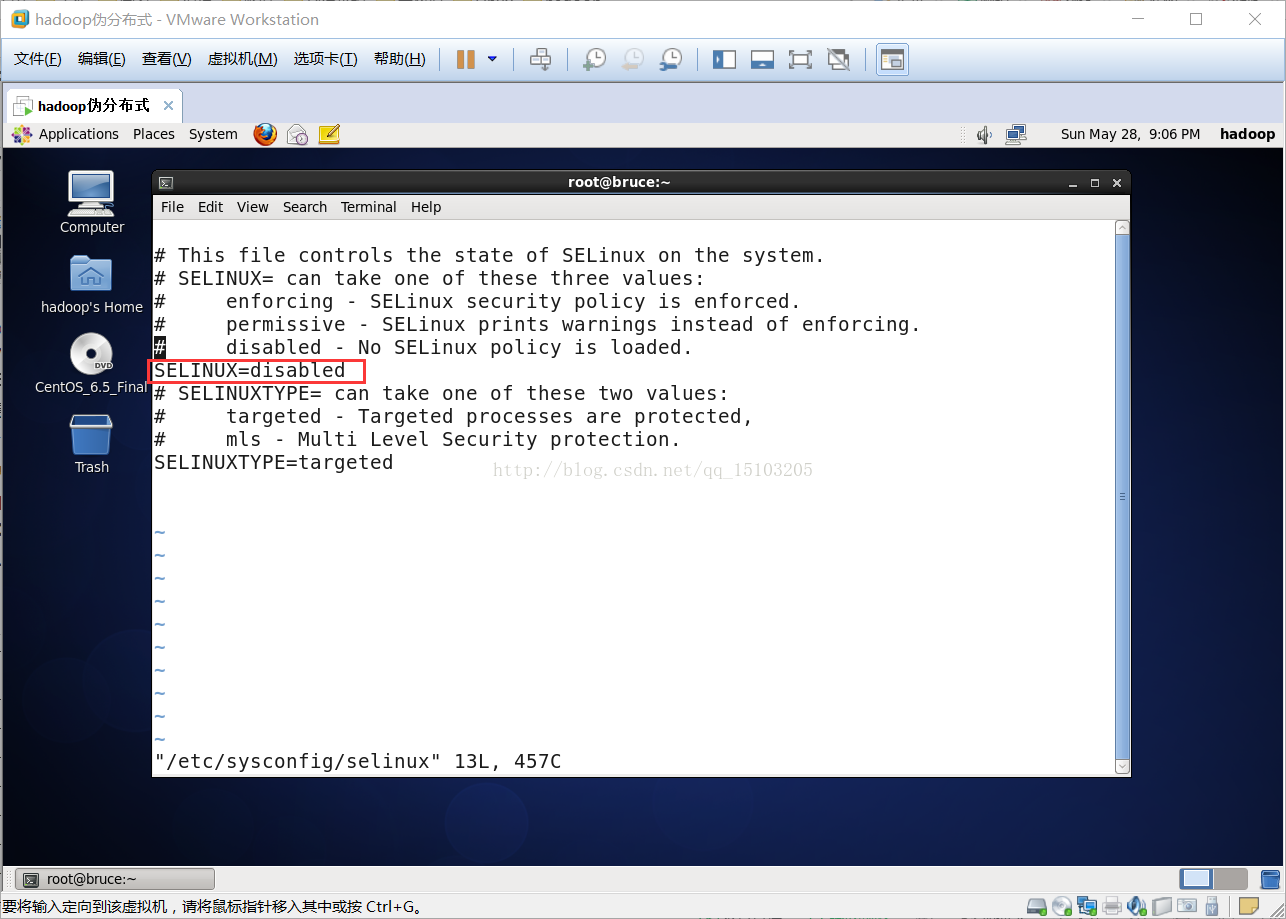
⑵ 关闭selinux,是一个安全子系统,它能控制程序只能访问特定文件
# vi /etc/sysconfig/selinux(注意:此文件在notepad中不可见)SELINUX=disabled # 把enforcing改成disabled
6、创建普通用户
后期所有操作都尽量使用普通用户来进行
# useradd hadoop(创建用户hadoop)
# passwd hadoop(设置密码)
二、JDK安装
1、创建软件下载安装目录并授权
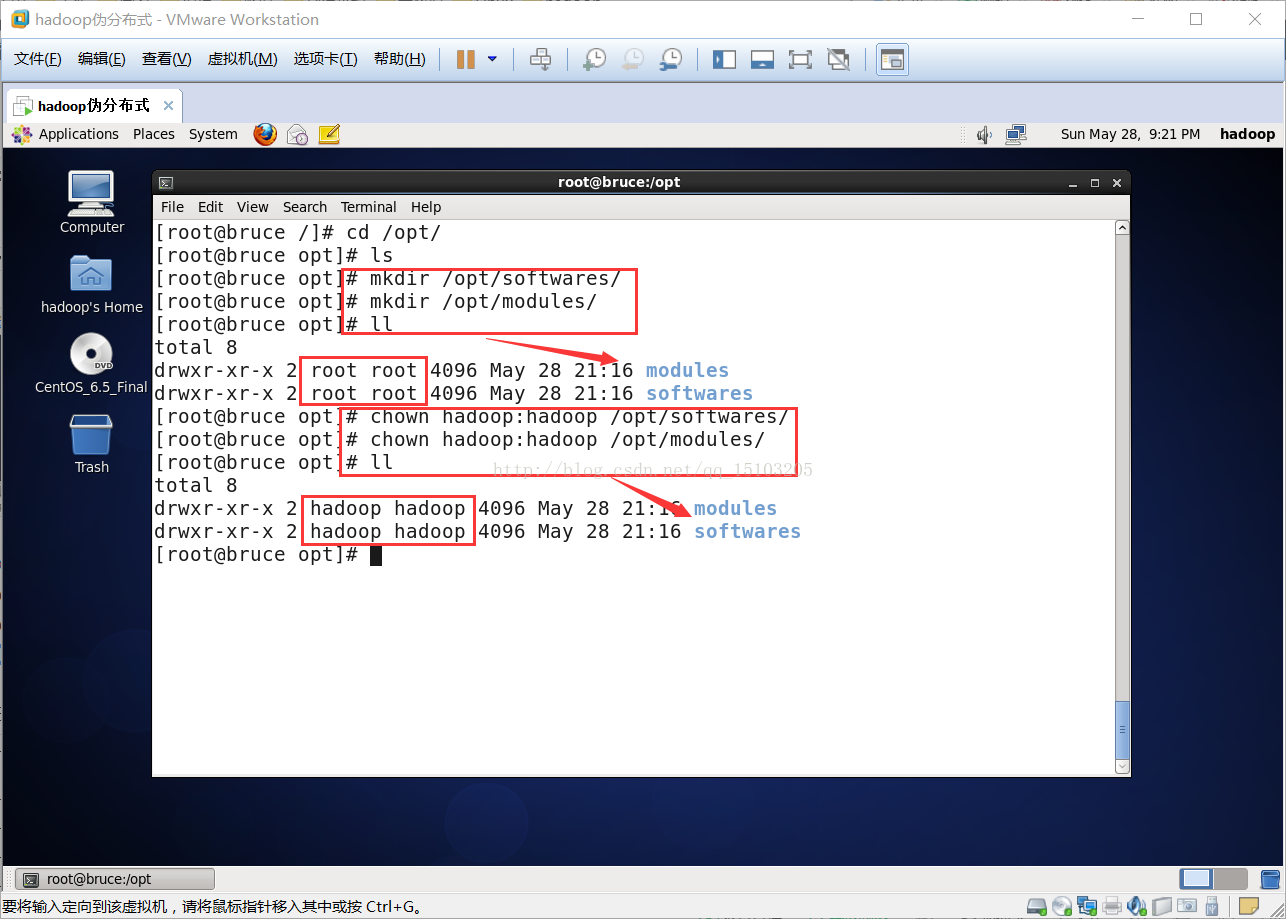
⑴创建软件下载安装目录
$ su - (普通用户在/opt目录没有权限,需要切换到root用户)
# mkdir /opt/softwares/ (用于存放下载软件目录)
# mkdir /opt/modules/(用于软件安装目录)

⑵授权目录权限给之前创建的普通用户
# chown hadoop:hadoop /opt/softwares/ (授权用户及用户组)
# chown hadoop:hadoop /opt/modules/
# ll /opt/ (查看授权结果)
2、解压缩安装
# su - hadoop(除非必须,全部使用普通用户来操作)
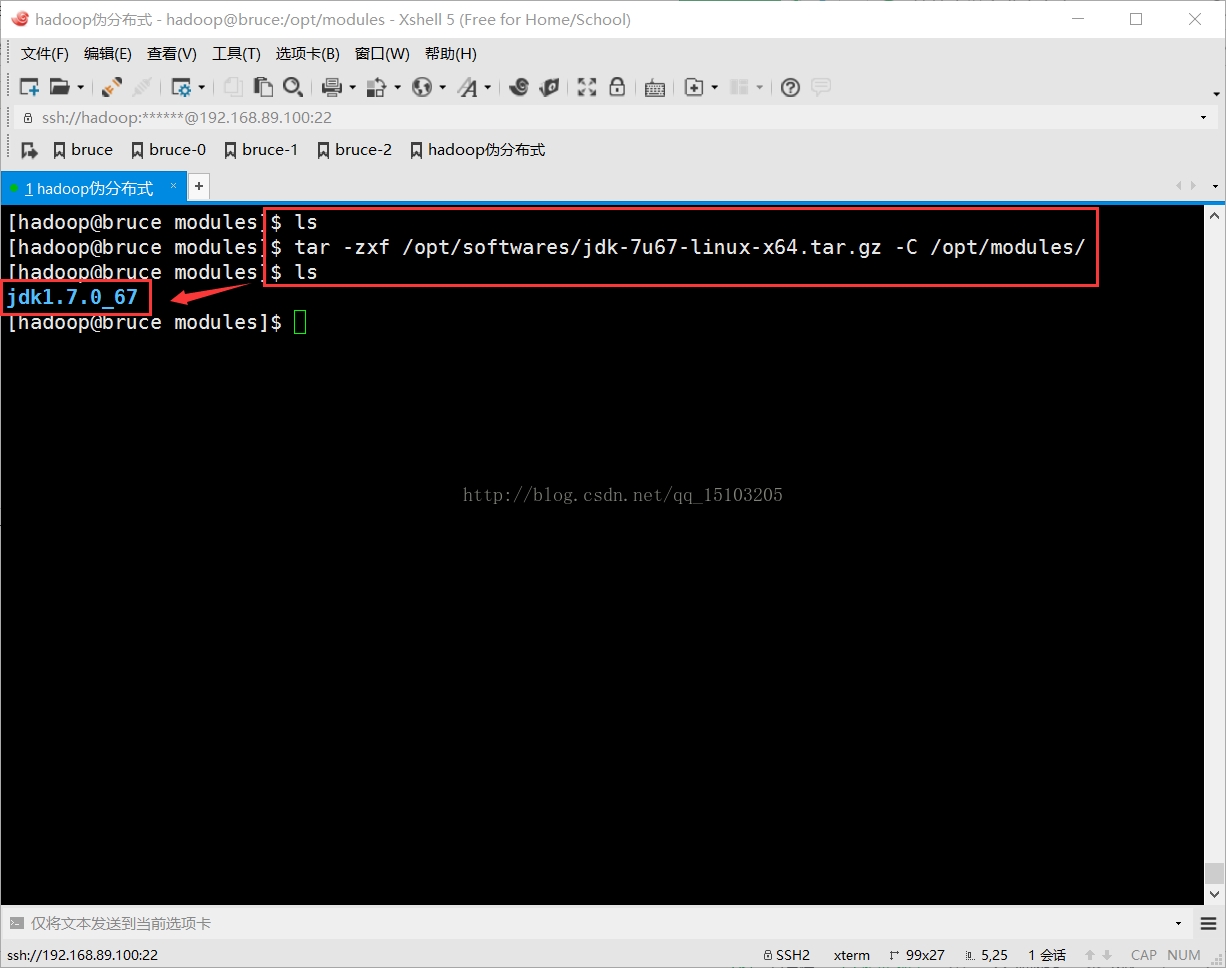
$ tar -zxvf /opt/softwares/jdk-7u67-linux-x64.tar.gz -C /opt/modules/
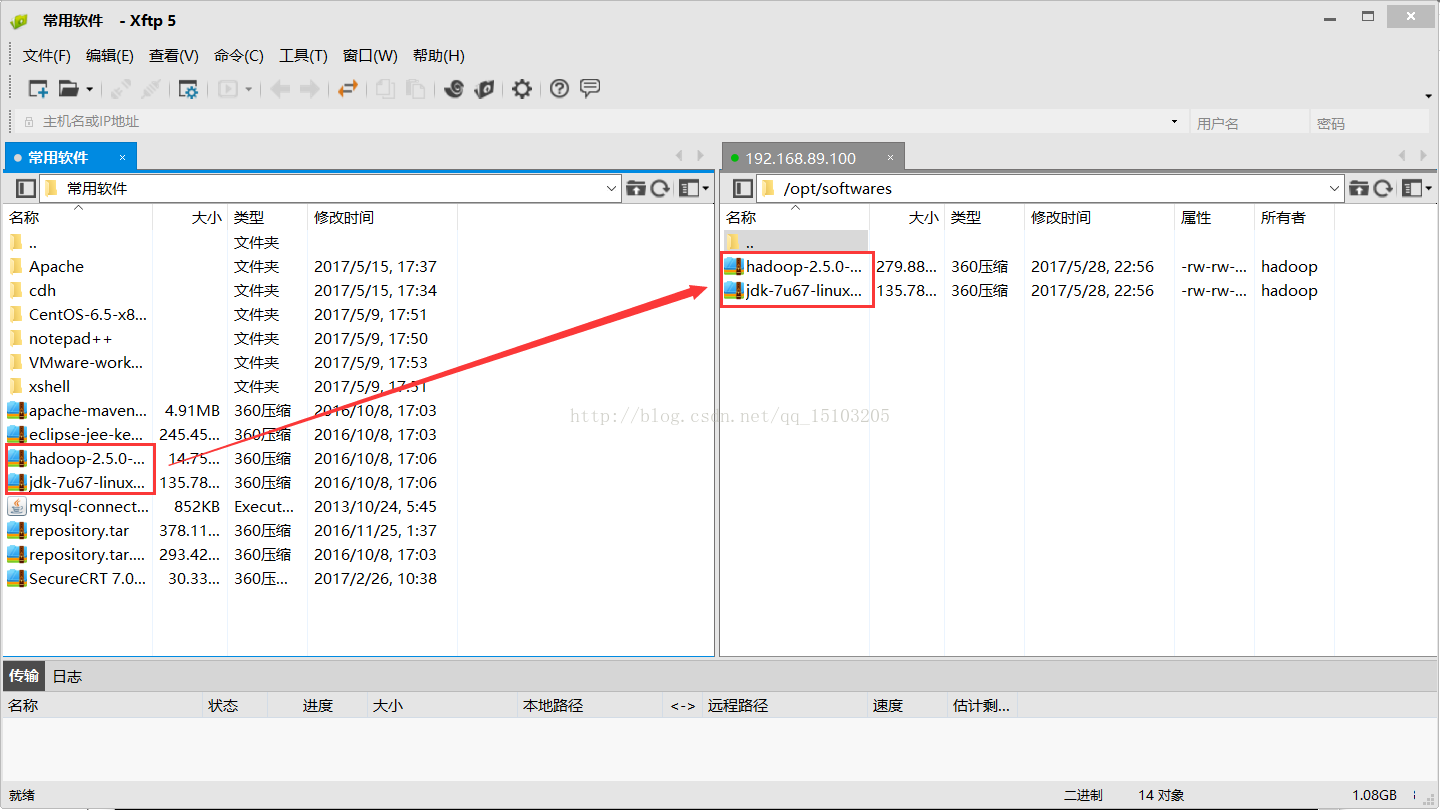
使用xshell上传安装包(打开xftp快捷键:Ctrl+Alt+F):
解压缩安装JDK
3、配置环境变量
$ su - (修改profile文件需要root权限)
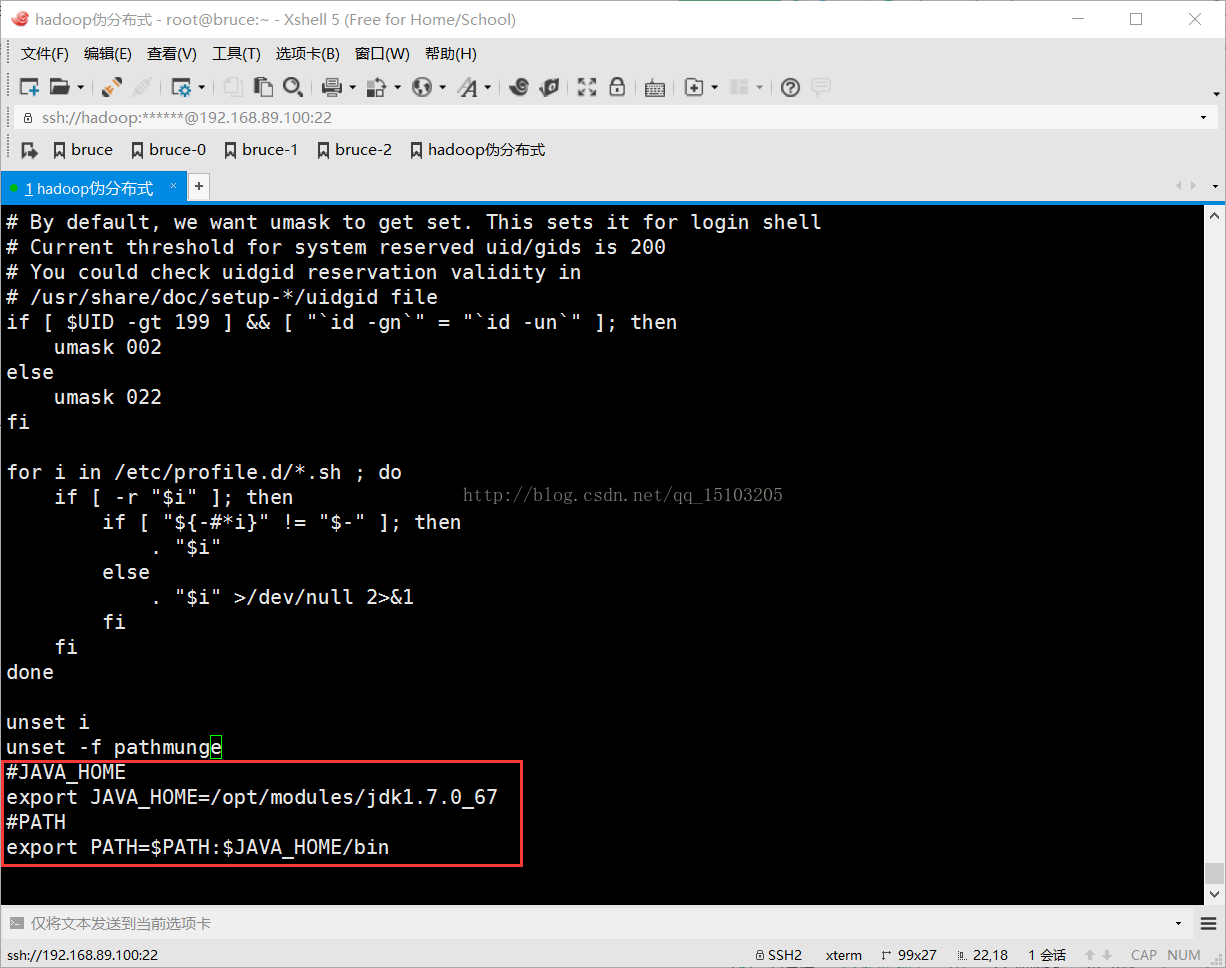
# vi /etc/profile (环境变量文件)
JAVA_HOME=/opt/modules/jdk1.7.0_67
export PATH=$PATH:$JAVA_HOME/bin
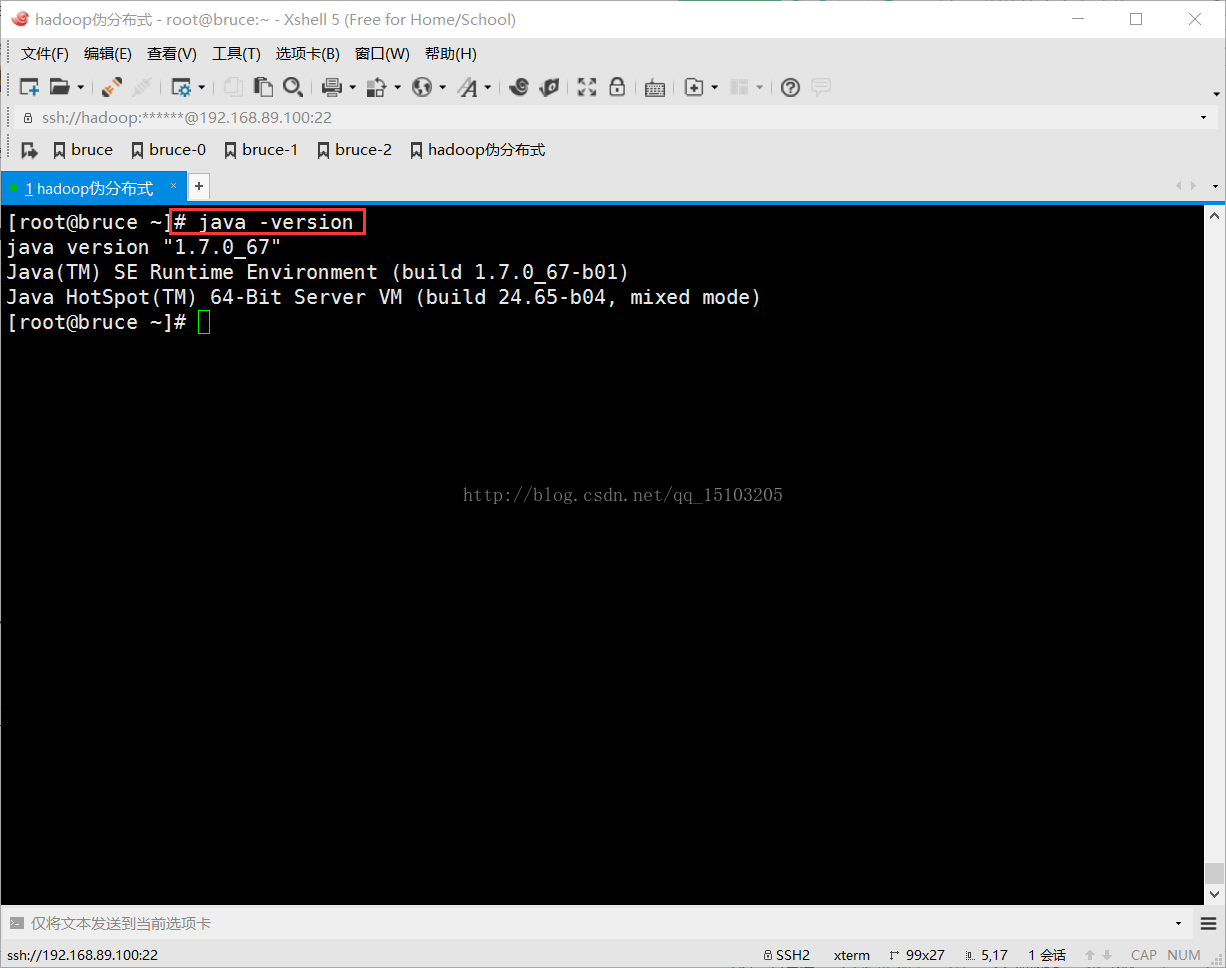
4、测试安装是否成功(卸载其他软件捆绑安装的JDK)
# java -version (如果结果不是自己安装的,则需要查询并卸载捆绑安装的JDK)
拓展(无需操作):
# rpm -qa (查看所有已经安装的rpm包)
# rpm -qa | grep -i java (-i 忽略大小写,查询已经安装的JDK)
# rpm -e --nodeps java-1.7.0-open (卸载捆绑安装的JDK)
三、Hadoop安装配置
1、Hadoop安装
2、HDFS配置(Hadoop Distributed File System)$ tar -zxf /opt/softwares/hadoop-2.5.0-cdh5.3.6.tar.gz -C /opt/modules/
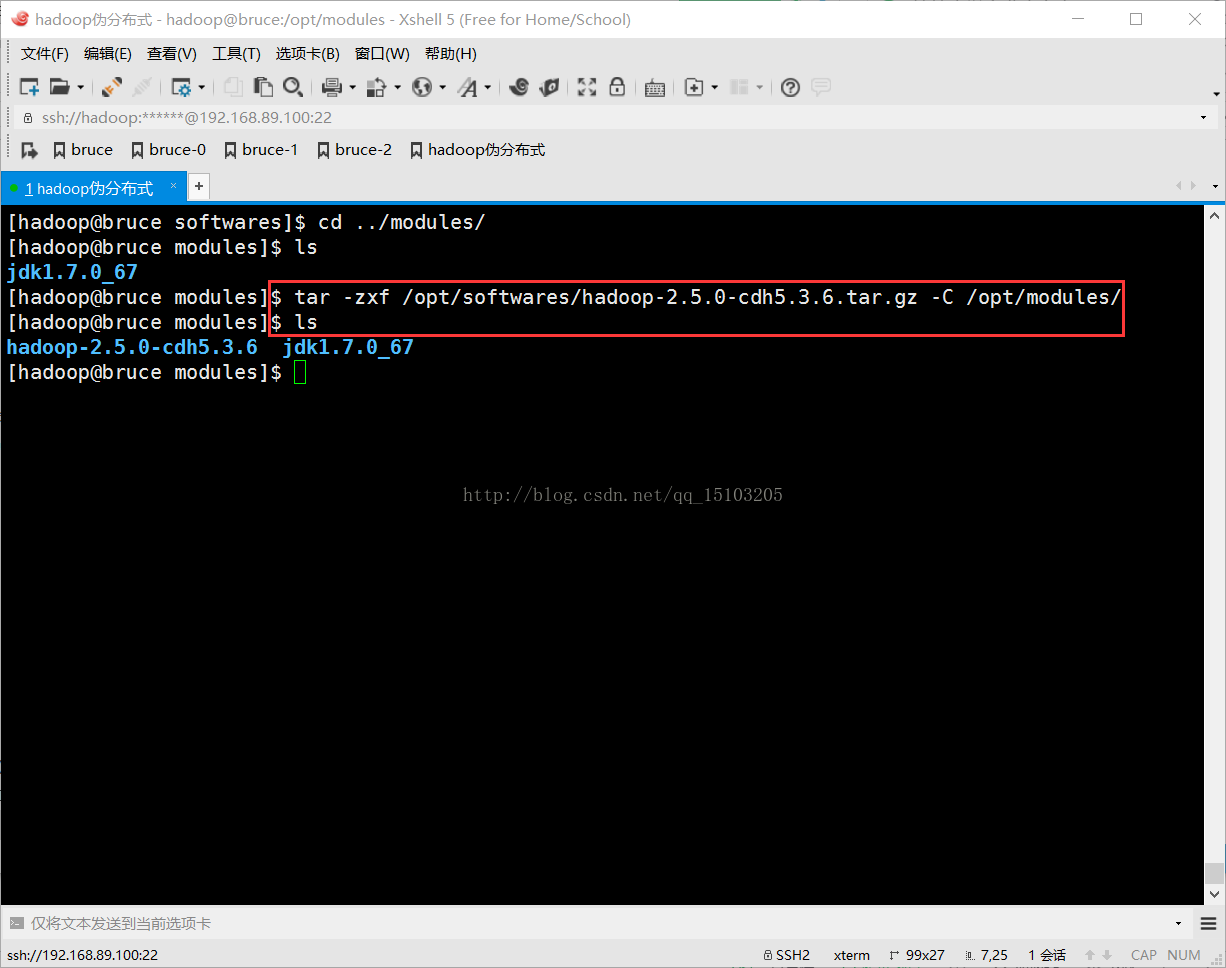
配置文件目录:Hadoop安装目录/etc/hadoop/
⑴修改hadoop-env.sh
export JAVA_HOME=/opt/modules/jdk1.7.0_67

⑵修改core-site.xml
<!--NameNode的访问URI,也可以写为IP,8020为默认端口,可改-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bruce.mydomain:8020</value>
</property>
<!--临时数据目录,用来存放数据,格式化namenode时会自动生成-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.5.0/data</value>
</property>

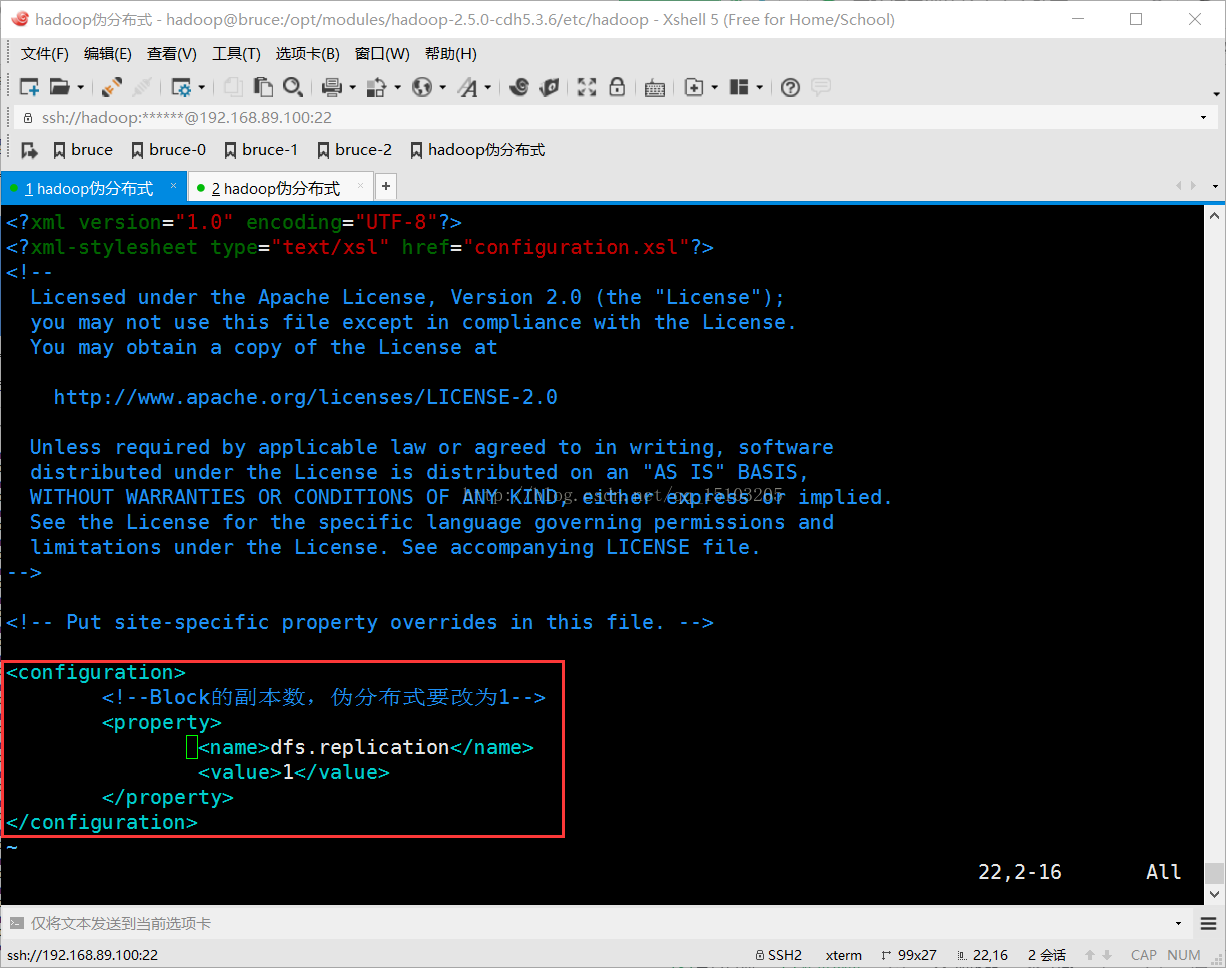
⑶修改hdfs-site.xml
<configuration>
<!--Block的副本数,伪分布式要改为1-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
⑷格式化namenode
$ cd /opt/modules/hadoop-2.5.0-cdh5.3.6/
$ bin/hdfs namenode -format (格式化namenode时会自动生成data目录)
⑸启动守护进程(服务)
$ cd /opt/modules/hadoop-2.5.0-cdh5.3.6/
$ sbin/hadoop-daemon.sh start namenode (stop用来停止守护进程)
$ sbin/hadoop-daemon.sh start datanode
$ jps (Process Status查看进程,jps用来查看Java进程,数字为PID,即Process id)
PS:若提示某个服务已经启动,可以去/tmp目录下删除对应的pid文件;
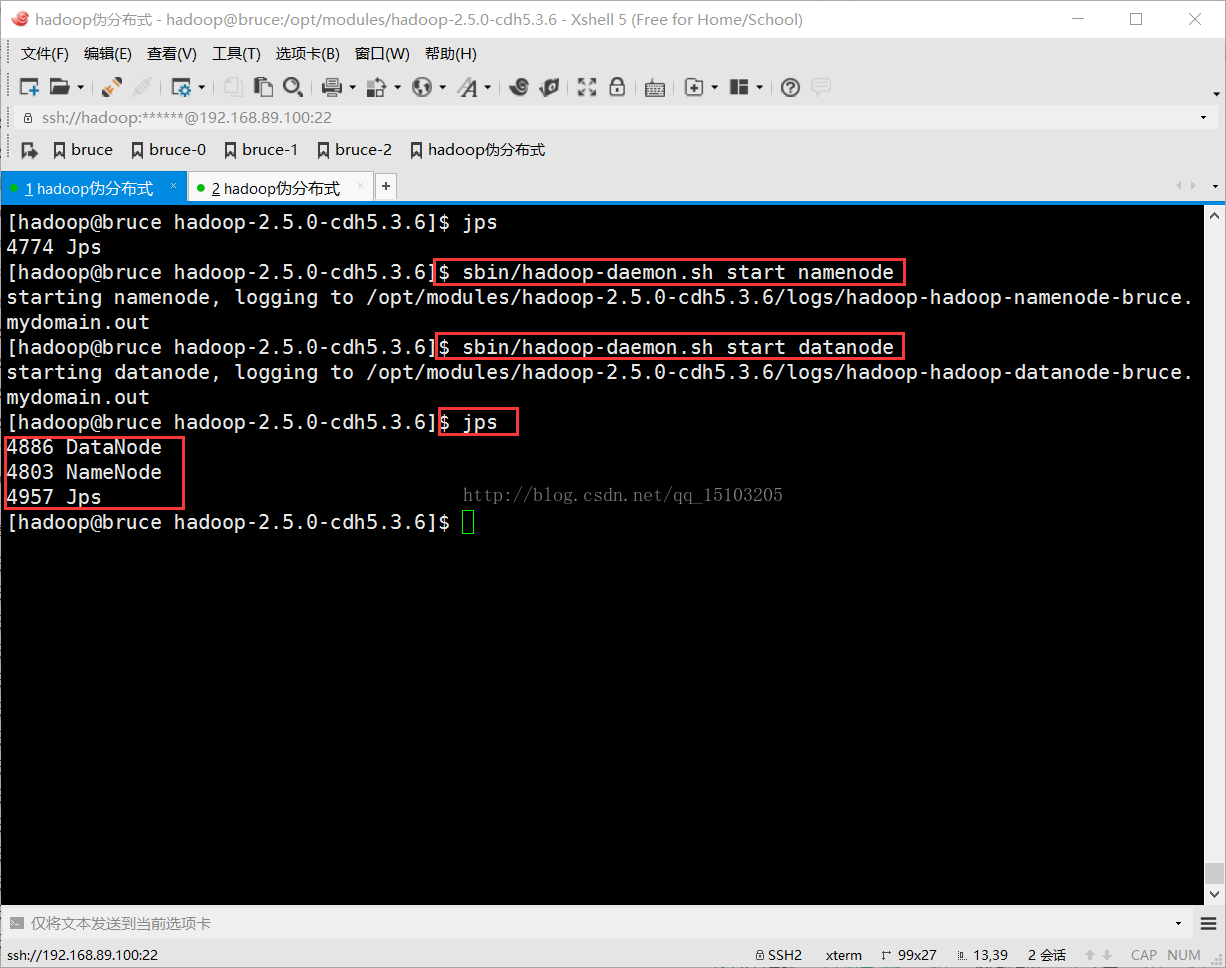
⑹测试
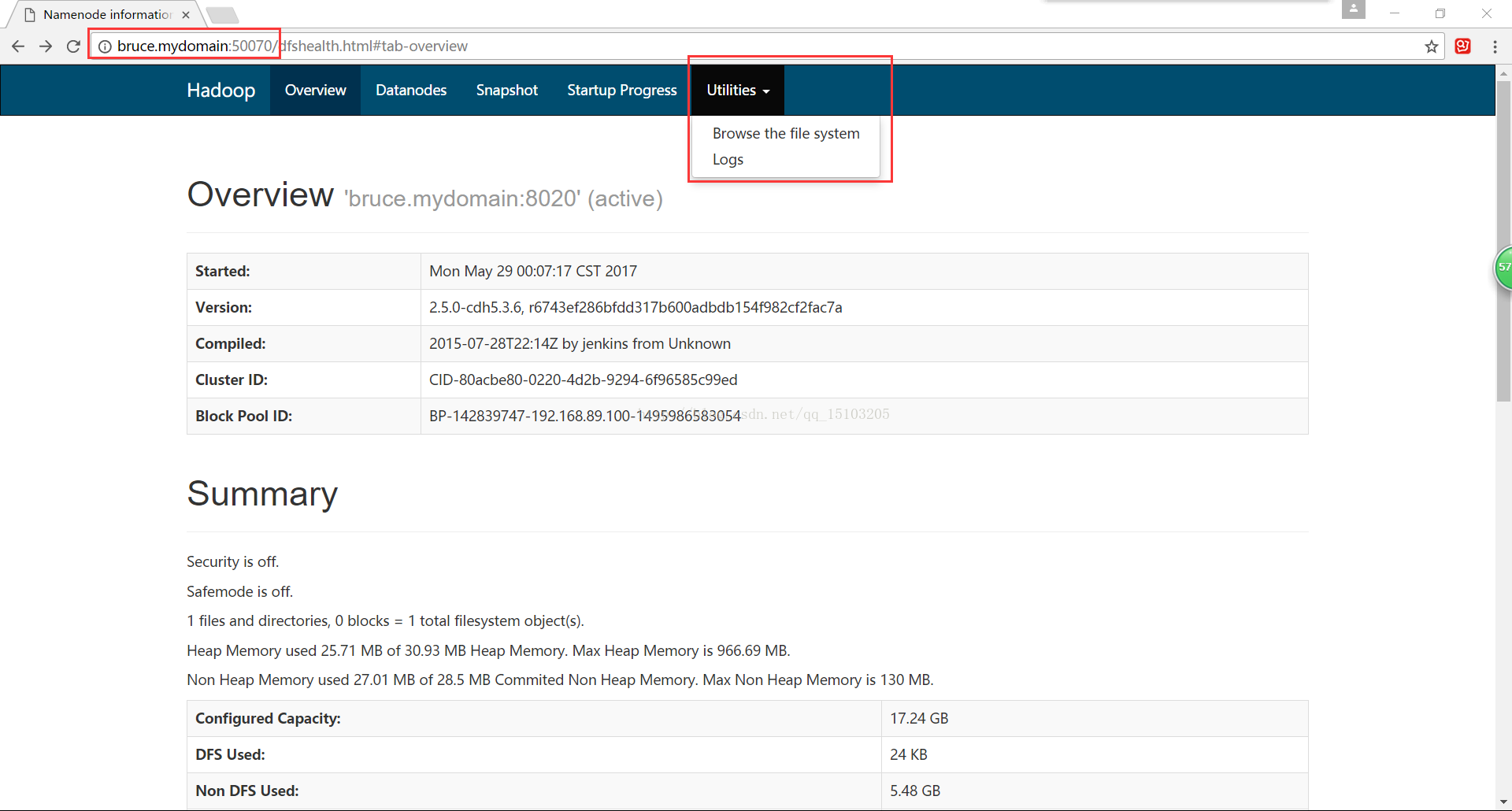
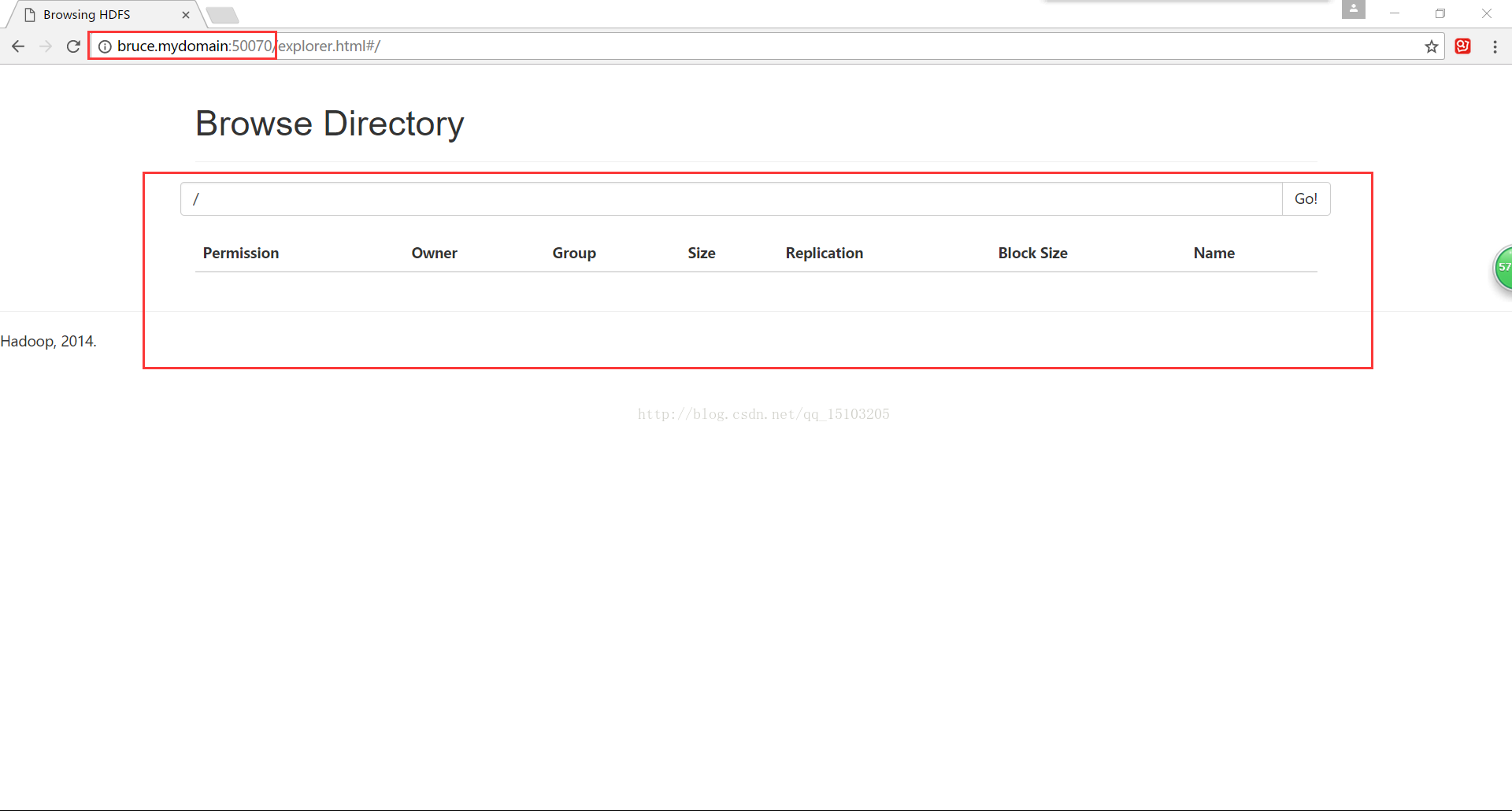
3、YARN配置①打开浏览器:http://bruce.mydomain:50070/
打开网址,Utilities-->Browse file system
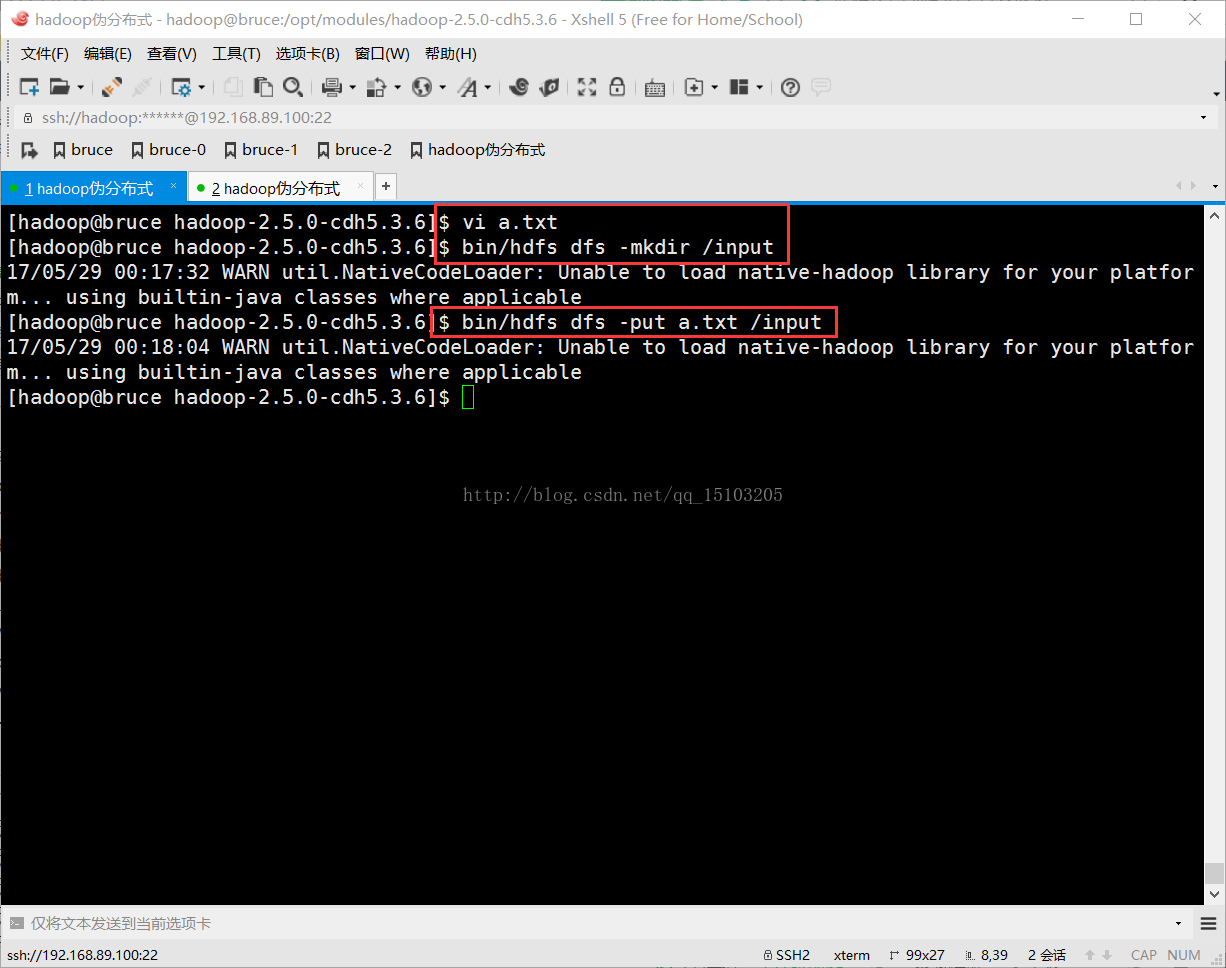
②上传文件:(测试HDFS)
$ cd /opt/modules/hadoop-2.5.0-cdh5.3.6/
$ vi a.txt (随便创建一个文件a.txt,测试用)
$ bin/hdfs dfs -mkdir /input (在HDFS上创建文件夹)
$ bin/hdfs dfs -put a.txt /input (把本地文件拷贝到HDFS)

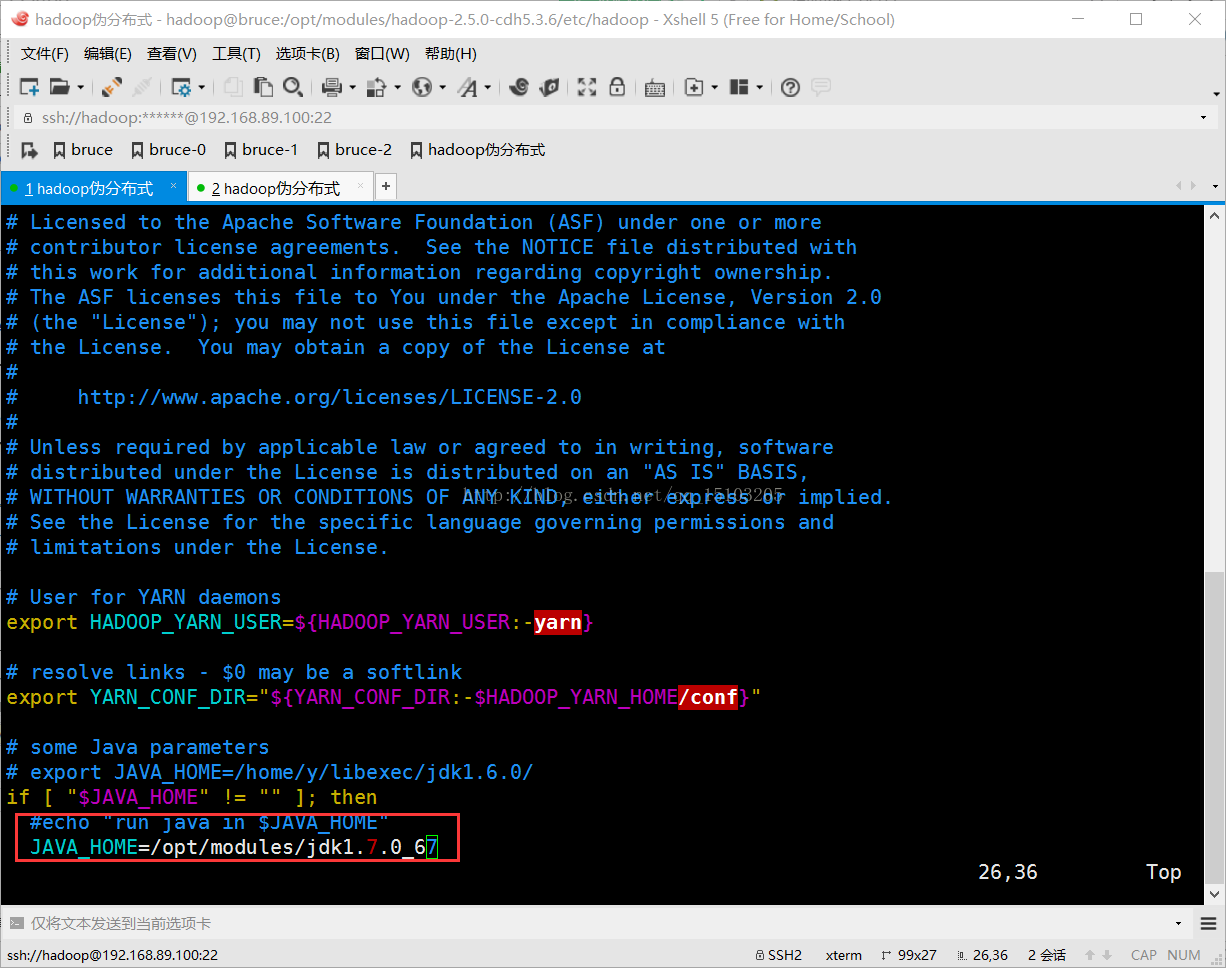
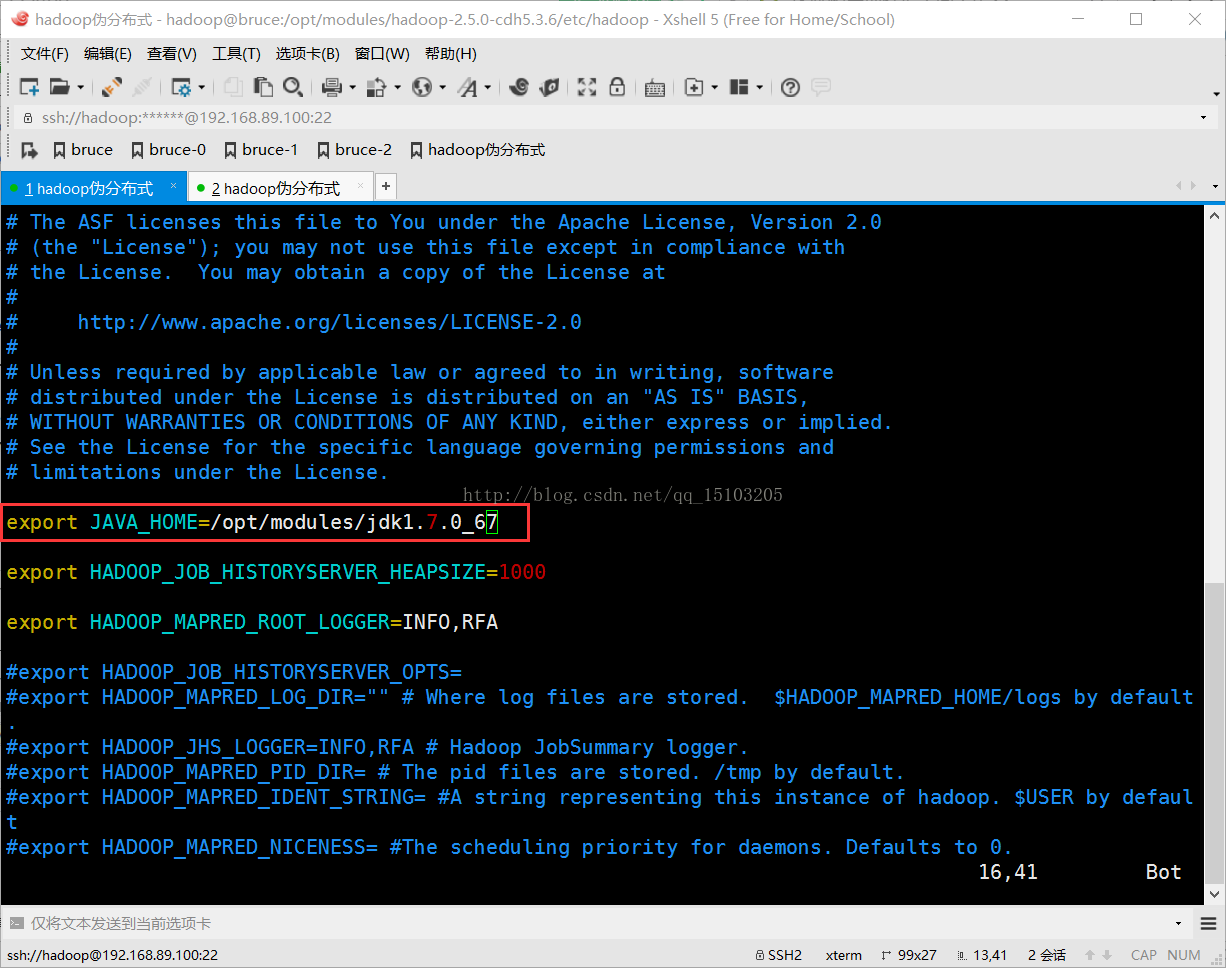
⑴修改yarn-env.sh和mapred-env.sh文件
export JAVA_HOME=/opt/modules/jdk1.7.0_67 (取消该行注解并配置)
⑵修改yarn-site.xml文件
<!--NodeManager上运行的辅助(auxiliary)服务,需配置成mapreduce_shuffle,才可运行MapReduce程序-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourcemanager主机-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bruce.mydomain</value>
</property>

⑶修改mapred-site.xml文件
$ cp mapred-site.xml.template mapred-site.xml (拷贝并重命名文件为mapred-site.xml)
<!--mapreduce是一种编程模型,运行在yarn平台上面-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
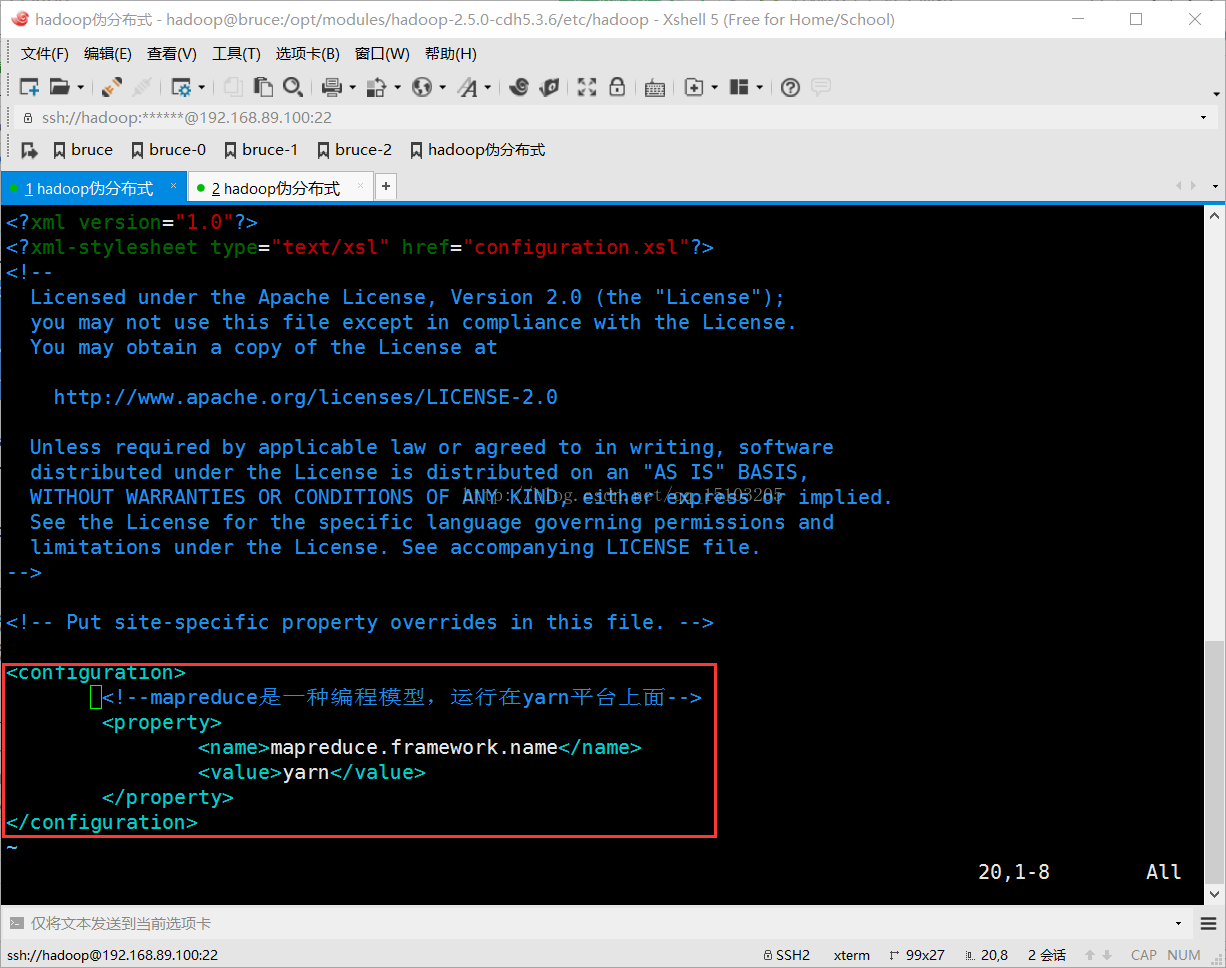
⑷修改slaves文件
bruce.mydomain (记录哪些主机是DataNode,每行一个主机名,删除原来的localhost)

⑸启动yarn
$ cd /opt/modules/hadoop-2.5.0-cdh5.3.6/
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager

⑹测试
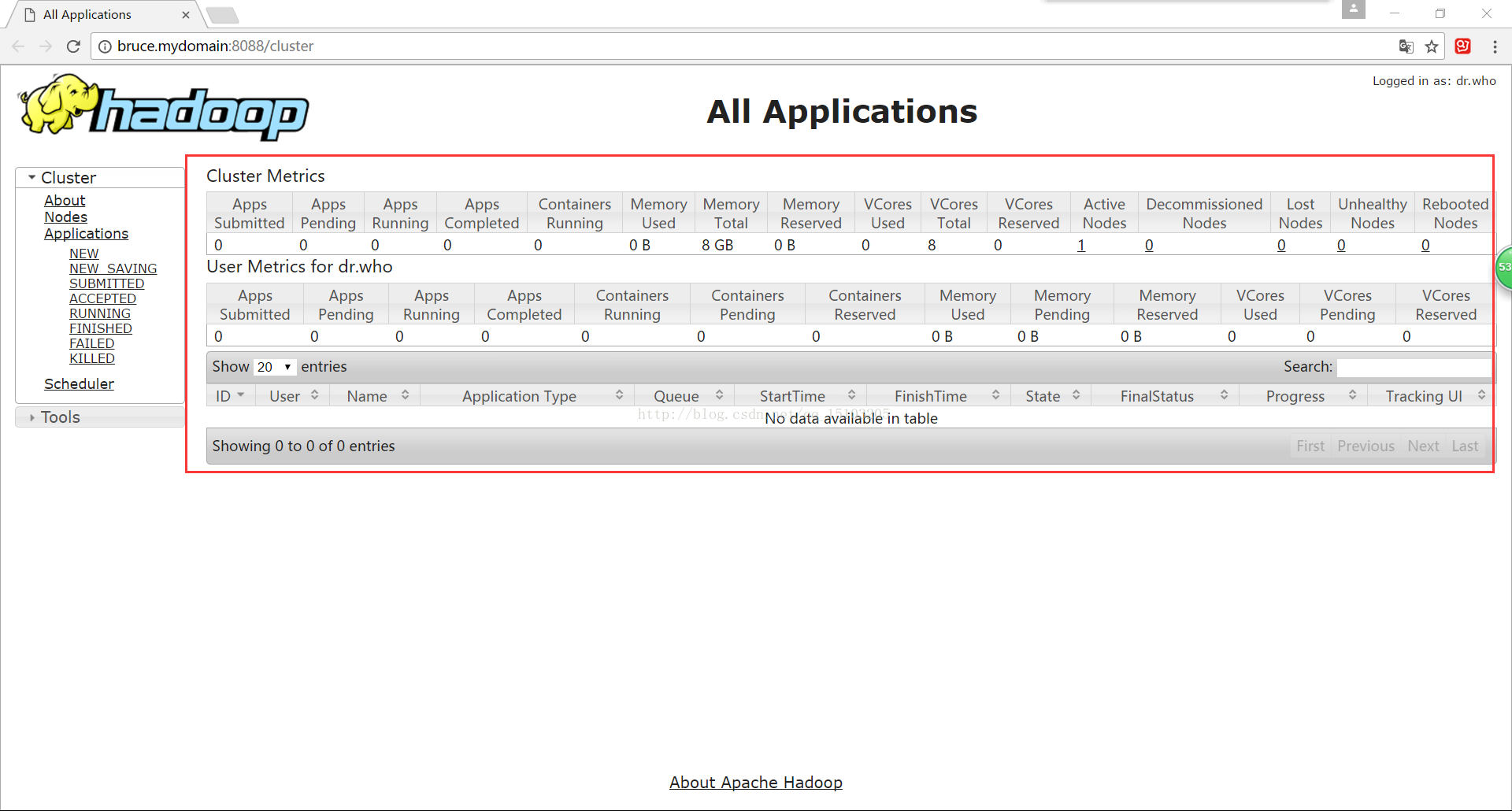
①yarn的作业监控平台:http://bruce.mydomain:8088
(显示yarn平台上运行job的所有资源(CPU、内存)等信息)
②运行一个mapreduce作业
(需要启动namenode和DataNode守护进程,在http://bruce.mydomain:50070上查看目标文件和结果文件)
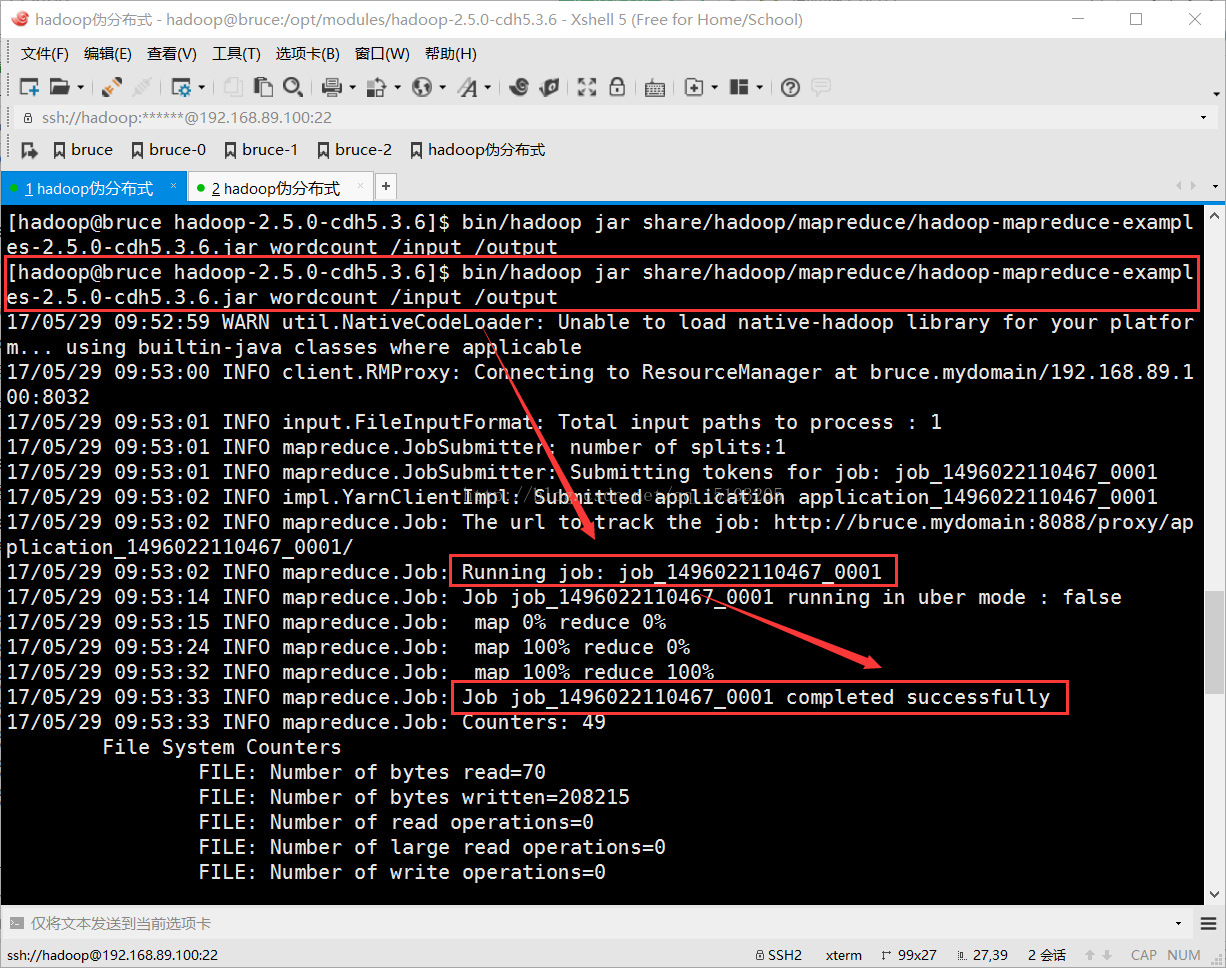
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /input /output
PS:运行官方提供的jar包,进行文件内单词统计(该例子是以tab键‘\t’作为单词间的分隔符);
程序名:wordcount ;
/input是输入路径,统计目录里的所有文件(可以上传多个文件);
/output是输出路径,为了防止结果被意外覆盖,Hadoop规定输出文件一定不能存在;
可以打开http://bruce.mydomain:8088,查看运行信息;
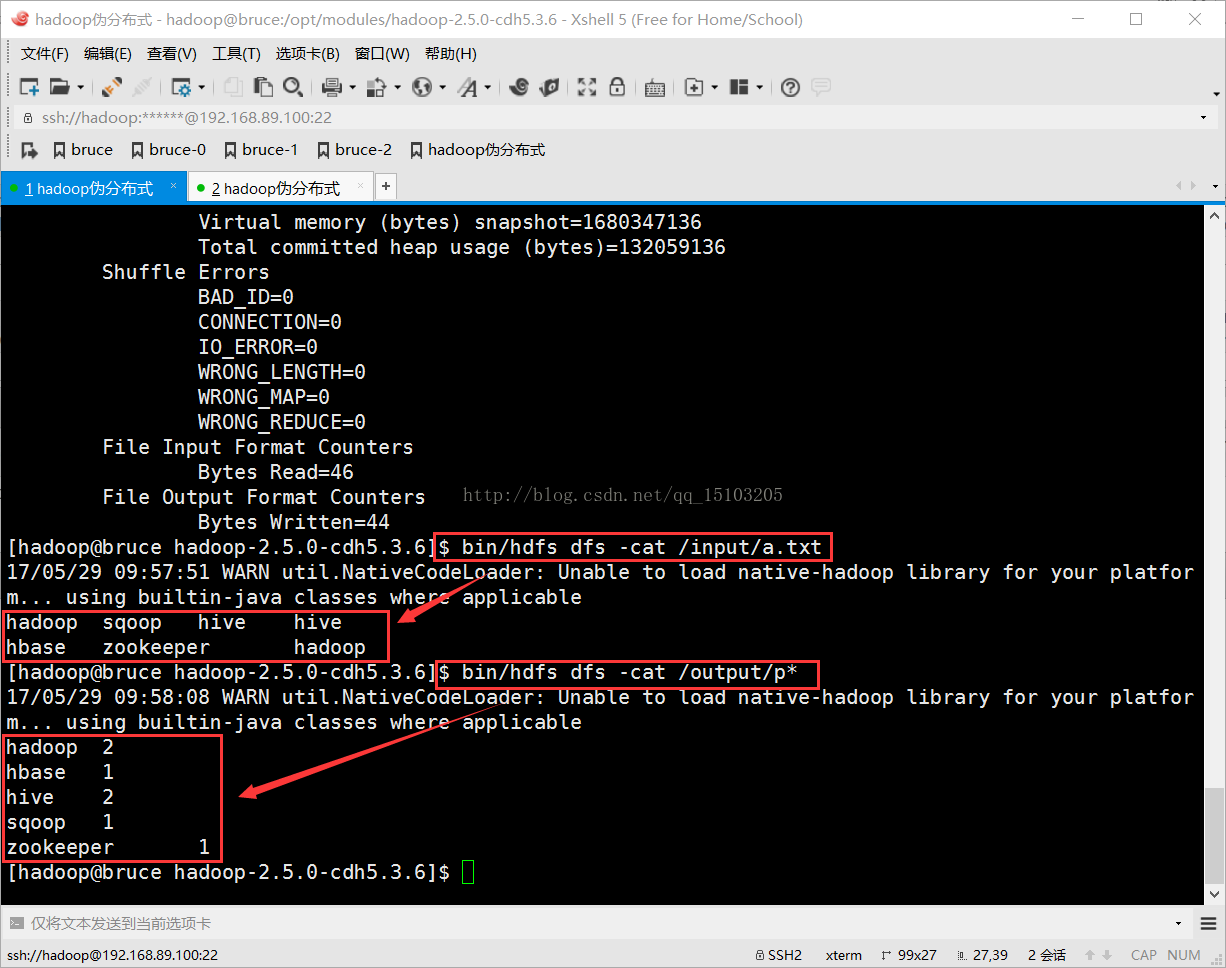
$ bin/hdfs dfs -cat /output/p* (命令窗口查看统计结果)
yarn平台监控wordcount运行:
wordcount运行结果:

四、配置日志服务器
(如果没有启动historyserver服务,则点击history无效;此外,还需要在Windows目录添加域名映射,即在C:\Windows\System32\drivers\etc里面的hosts文件里添加映射)
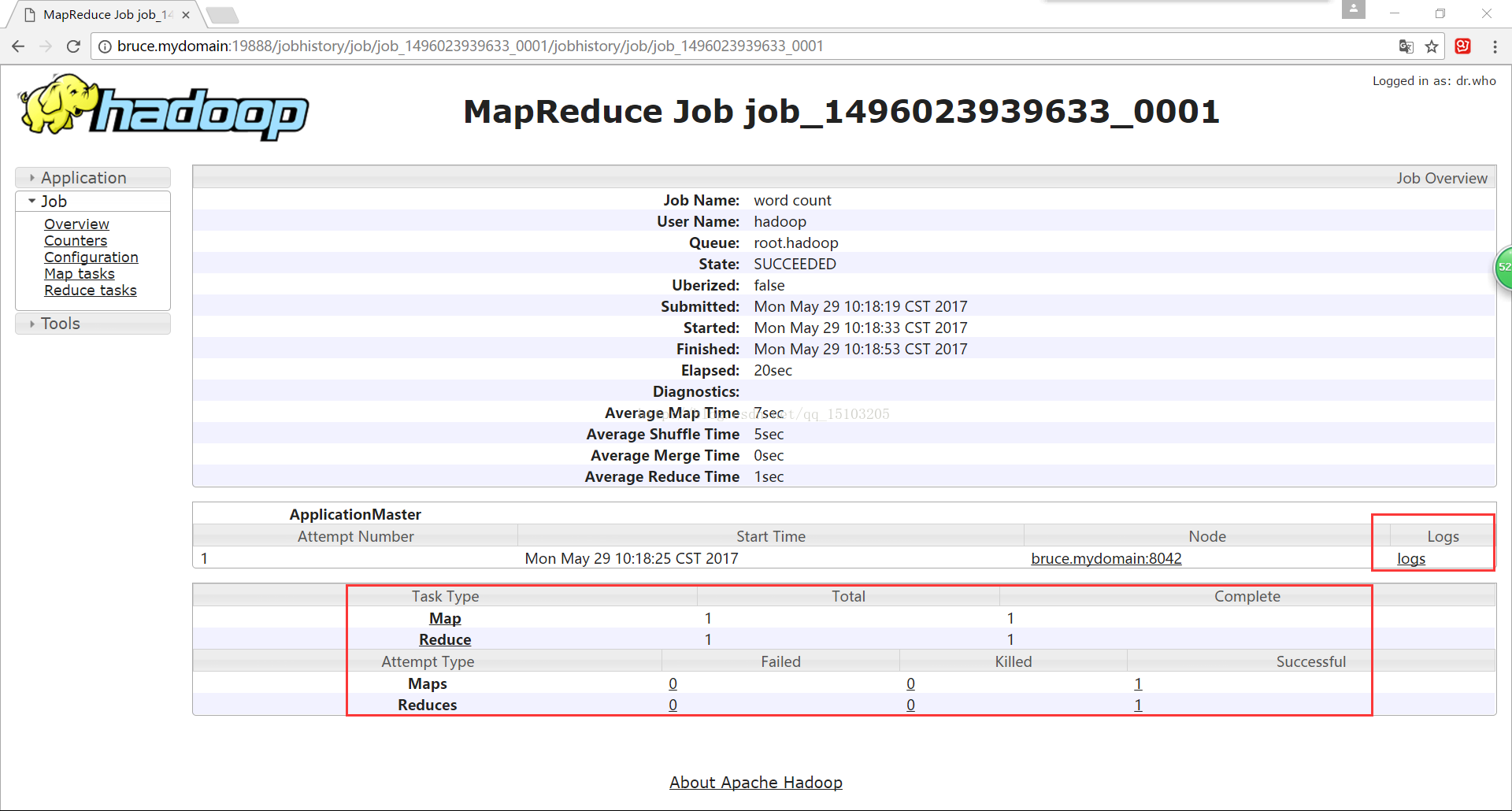
(历史服务:可以查看已经运行完成的mapreduce作业记录,比如本次作业用了多少map、reduce、作业提交时间、启动时间、完成时间等信息;)
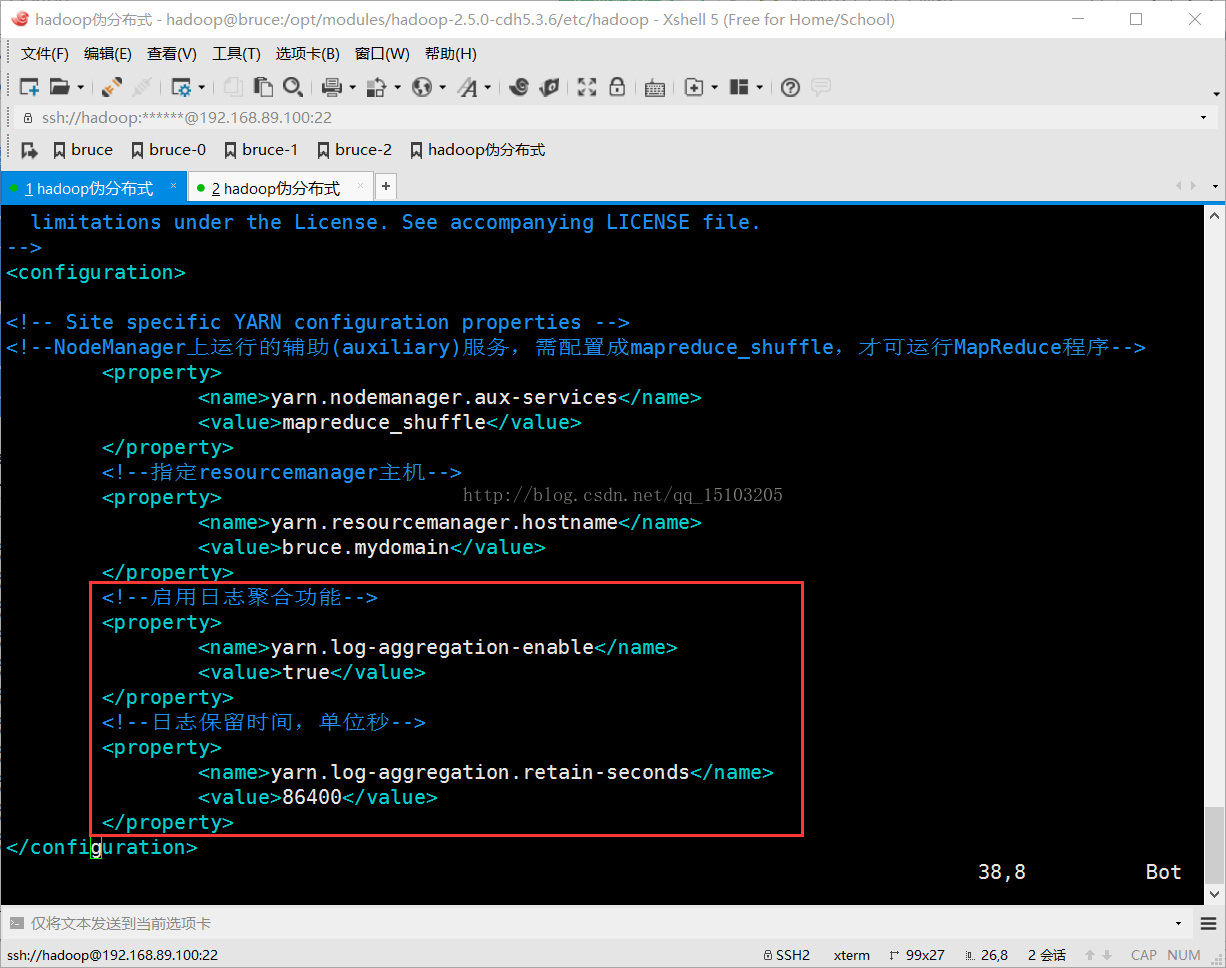
1、修改yarn-site.xml文件
<!--启用日志聚合功能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志保留时间,单位秒-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
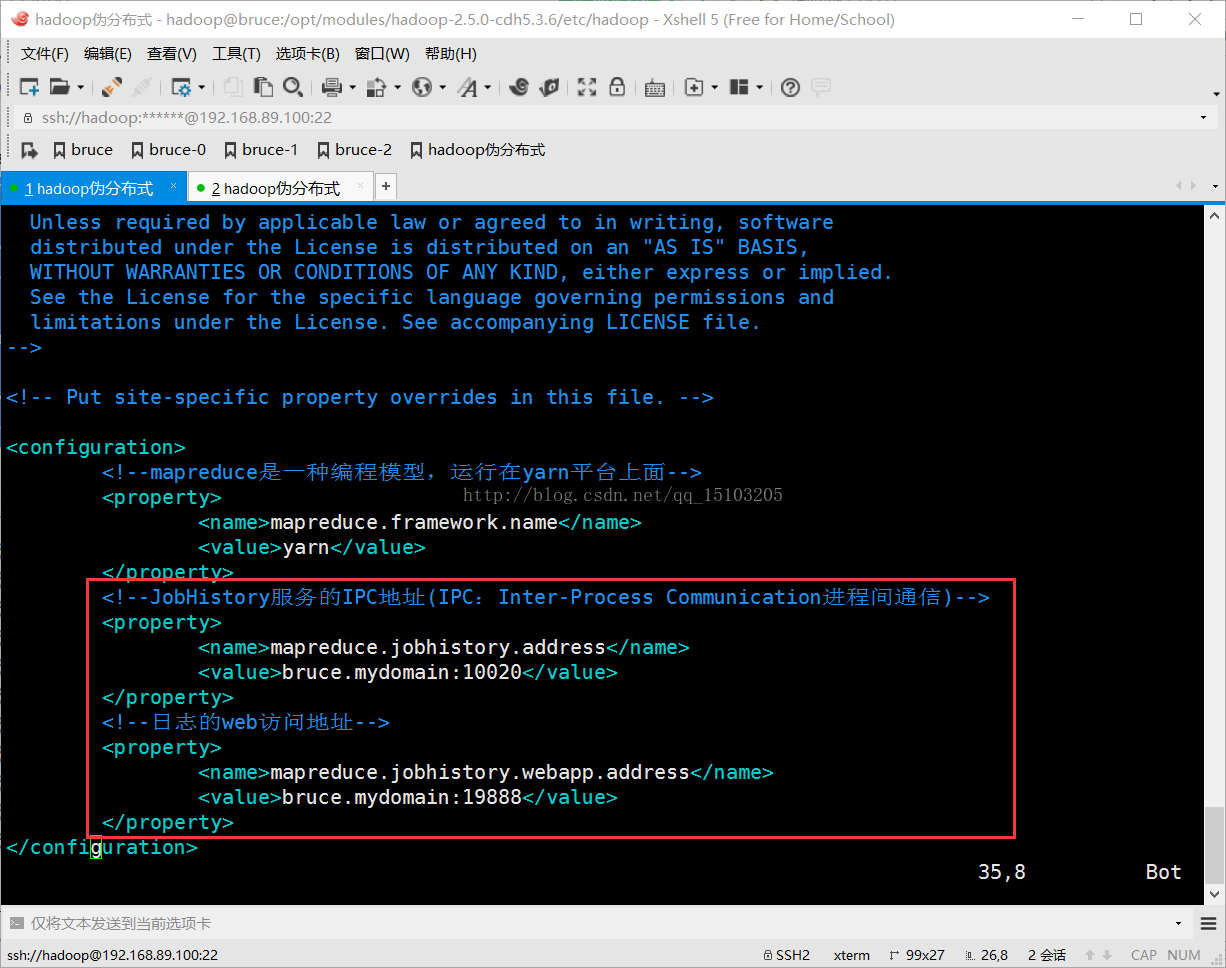
2、修改mapred-site.xml文件
<!--JobHistory服务的IPC地址(IPC:Inter-Process Communication进程间通信)-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>bruce.mydomain:10020</value>
</property>
<!--日志的web访问地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bruce.mydomain:19888</value>
</property>
3、重启yarn服务
$ sbin/yarn-daemon.sh stop resourcemanager
$ sbin/yarn-daemon.sh stop nodemanager
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager

4、启动historyserver服务
$ sbin/mr-jobhistory-daemon.sh start historyserver

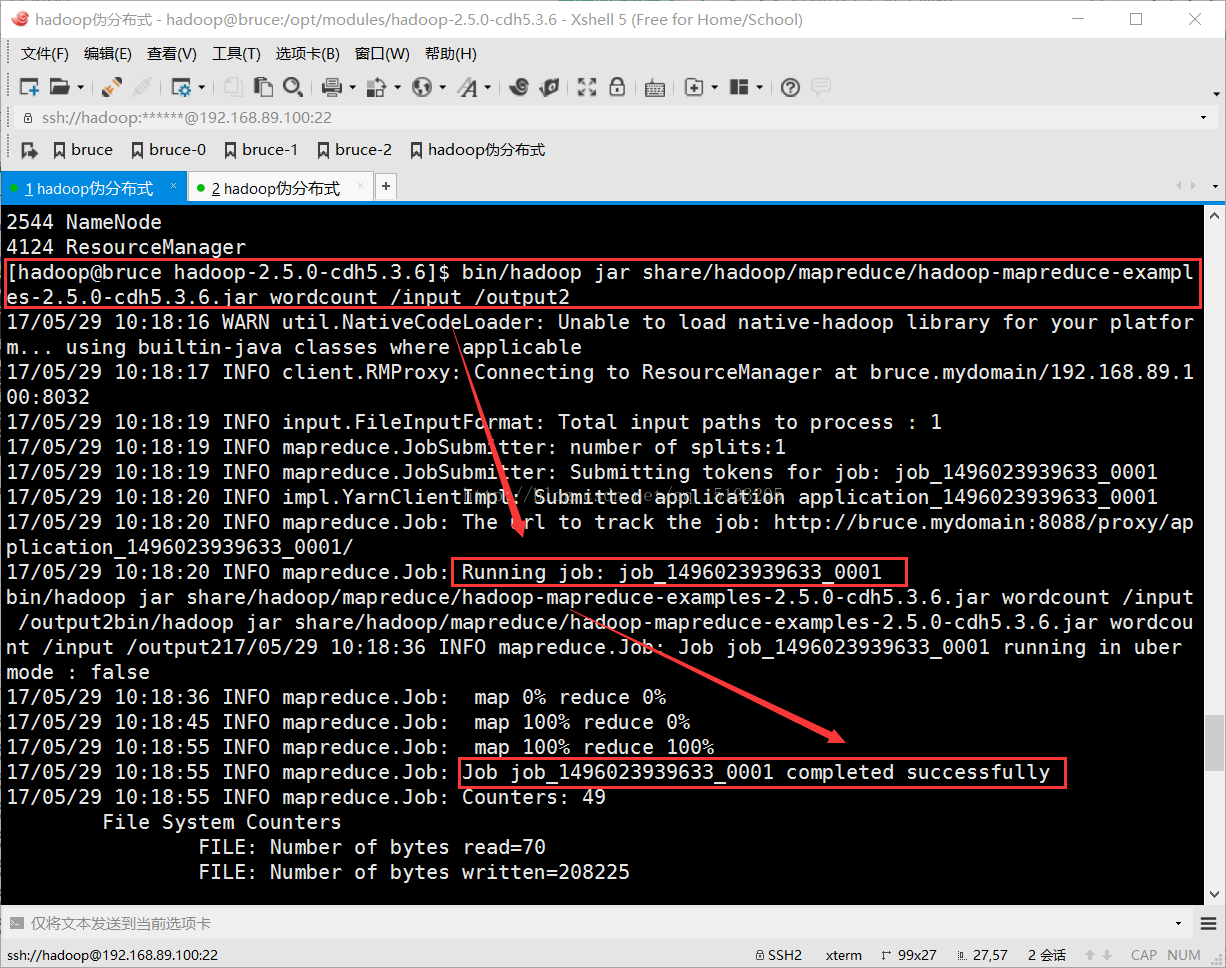
5、再次运行mapreduce作业(必须改变输出目录)
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /input /output2
查看mapreduce的运行历史及日志:
















 7916
7916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









