







https://datastrato.ai/blog/gravitino-unified-metadata-lake/
Gravitino - the unified metadata lake
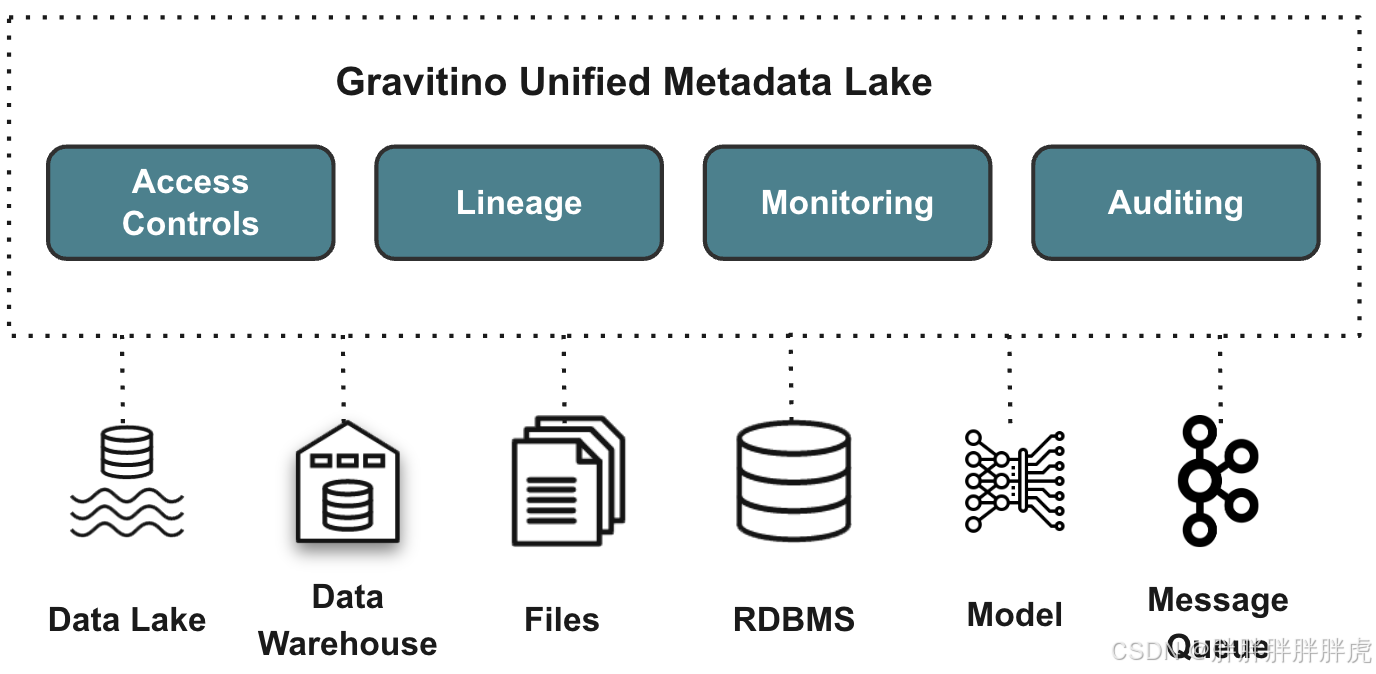
Gravitino is a high-performance, geo-distributed, and federated
metadata lake. It manages the metadata directly in different sources,
types, and regions. It also provides users with unified metadata
access for data and AI assets.The goal of Gravitino is to provide the user with
a unified data management and governance platform no matter where the
data stored.
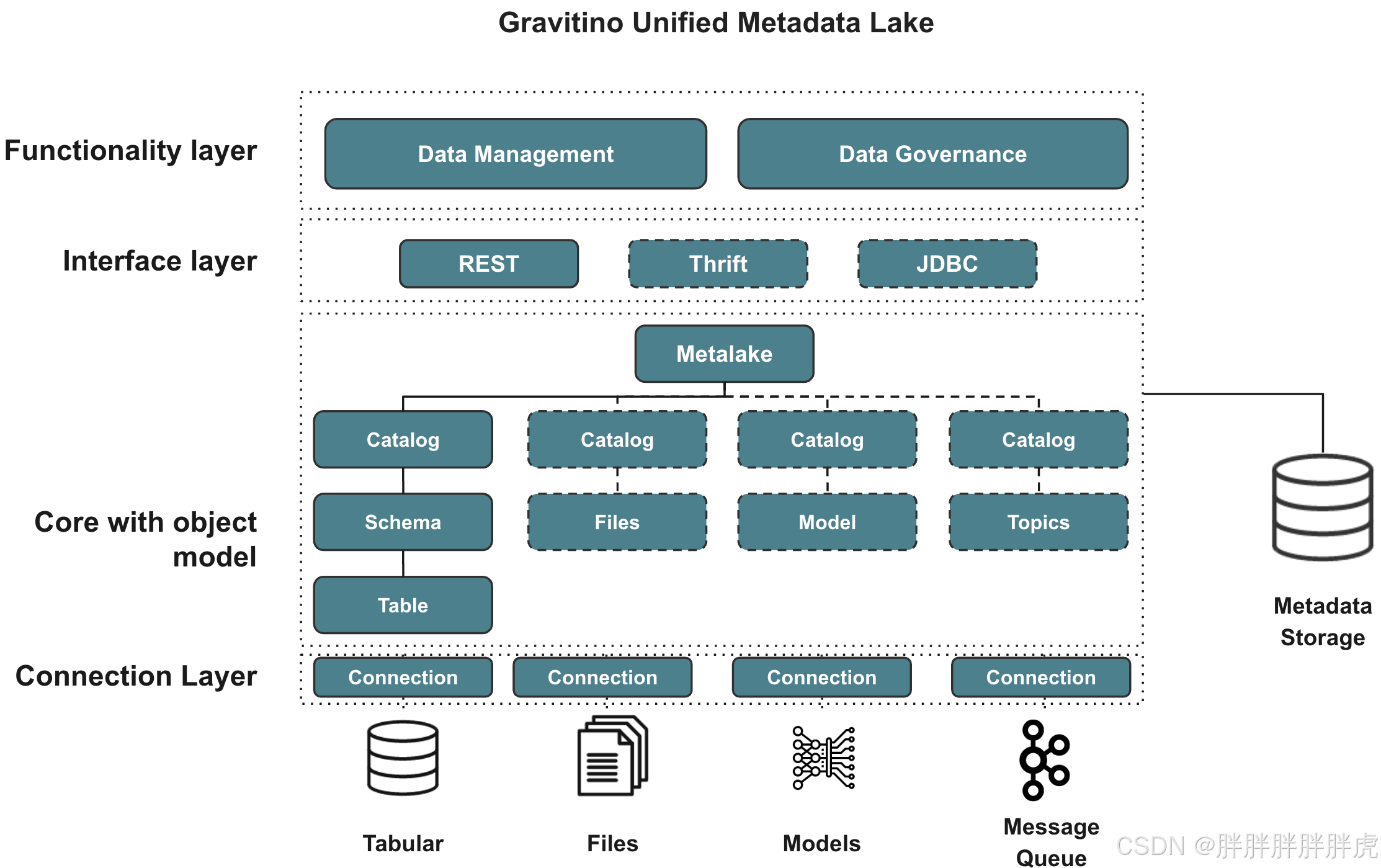
The architecture of Gravitino
https://gravitino.apache.org/docs/0.6.1-incubating/how-to-install
The playground is a complete Apache Gravitino Docker runtime environment with Hive, HDFS, Trino, MySQL, PostgreSQL, Jupyter, and a Gravitino server.
Depending on your network and computer, startup time may take 3-5 minutes. Once the playground environment has started, you can open http://localhost:8090 in a browser to access the Gravitino Web UI.
sudo docker run -d -i -p 8090:8090 --name gravitino apache/gravitino:0.6.1-incubating
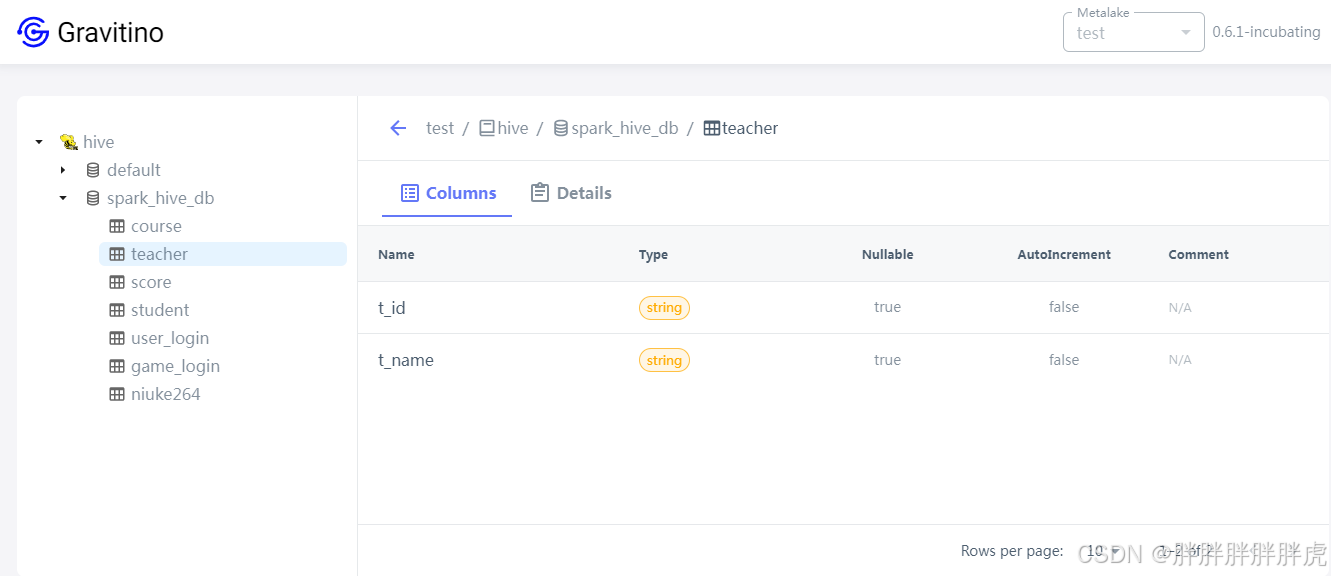
gravitino restful API
查询表列表
[hadoop@hadoop03 conf]$ curl http://192.168.153.103:8090/api/metalakes/test/catalogs/hive/schemas/default/tables | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 86 100 86 0 0 321 0 --:--:-- --:--:-- --:--:-- 322
{
"code": 0,
"identifiers": [
{
"namespace": [
"test",
"hive",
"default"
],
"name": "game_login"
}
]
}
查询表分区
[hadoop@hadoop03 conf]$ curl http://192.168.153.103:8090/api/metalakes/test/catalogs/hive/schemas/spark_hive_db/tables/income_info/partitions | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 37 100 37 0 0 46 0 --:--:-- --:--:-- --:--:-- 46
{
"code": 0,
"names": [
"day=2024-11-13"
]
}
查询表信息
[hadoop@hadoop03 conf]$ curl http://192.168.153.103:8090/api/metalakes/test/catalogs/hive/schemas/spark_hive_db/tables/income_info | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1396 100 1396 0 0 2047 0 --:--:-- --:--:-- --:--:-- 2049
{
"code": 0,
"table": {
"name": "income_info",
"comment": "?????",
"columns": [
{
"name": "id",
"type": "string",
"comment": "??id",
"nullable": true,
"autoIncrement": false
},
{
"name": "name",
"type": "string",
"comment": "????",
"nullable": true,
"autoIncrement": false
},
{
"name": "income_data",
"type": "string",
"comment": "??",
"nullable": true,
"autoIncrement": false
},
{
"name": "income_month",
"type": "string",
"comment": "??????",
"nullable": true,
"autoIncrement": false
},
{
"name": "income_type",
"type": "string",
"comment": "????",
"nullable": true,
"autoIncrement": false
},
{
"name": "income_datetime",
"type": "string",
"comment": "??????",
"nullable": true,
"autoIncrement": false
},
{
"name": "day",
"type": "string",
"comment": "????????",
"nullable": true,
"autoIncrement": false
}
],
"properties": {
"input-format": "org.apache.hadoop.hive.ql.io.orc.OrcInputFormat",
"serde.parameter.line.delim": "\n",
"transient_lastDdlTime": "1731517128",
"output-format": "org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat",
"serde.parameter.serialization.format": "\t",
"serde.parameter.field.delim": "\t",
"table-type": "MANAGED_TABLE",
"location": "hdfs://hadoop03:9000/user/hive/warehouse/spark_hive_db.db/income_info",
"serde-lib": "org.apache.hadoop.hive.ql.io.orc.OrcSerde"
},
"audit": {
"creator": "hadoop",
"createTime": "2024-11-13T16:58:48Z"
},
"distribution": {
"strategy": "none",
"number": 0,
"funcArgs": []
},
"sortOrders": [],
"partitioning": [
{
"strategy": "identity",
"fieldName": [
"day"
]
}
],
"indexes": []
}
}
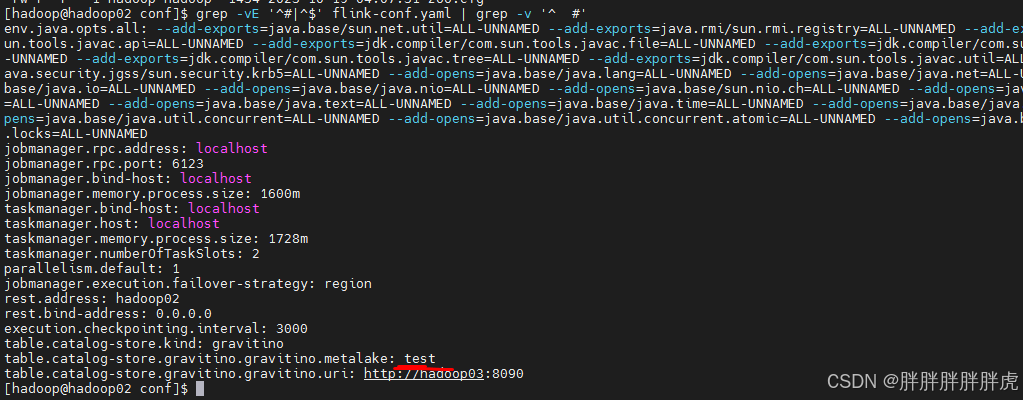
gravitino flink connector
hive catalog
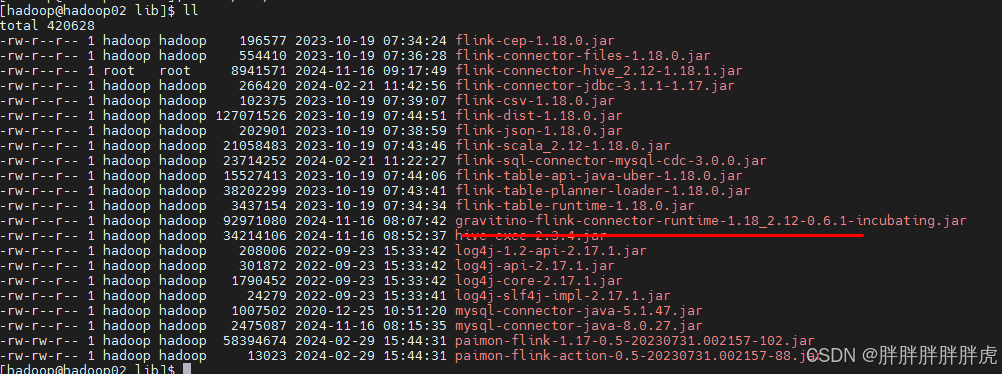
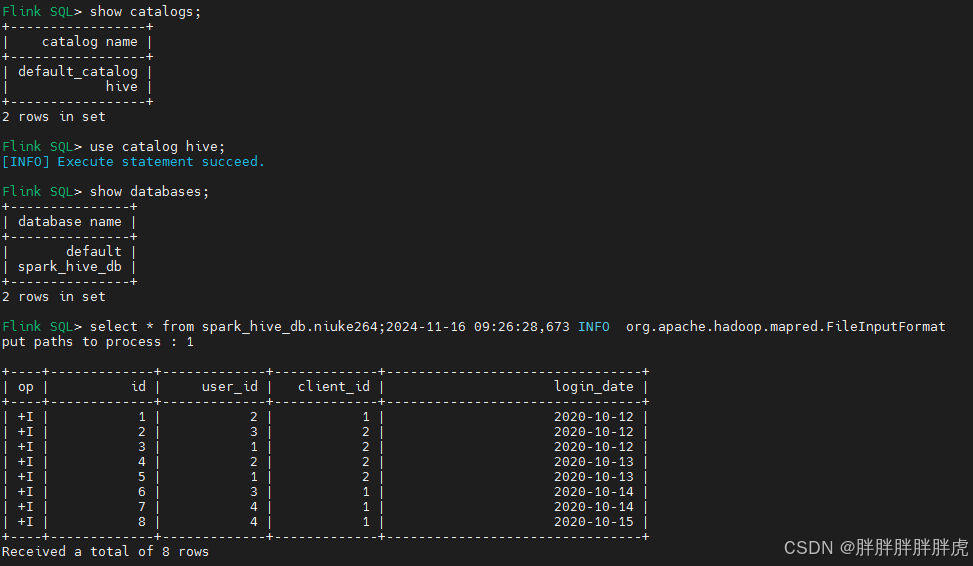
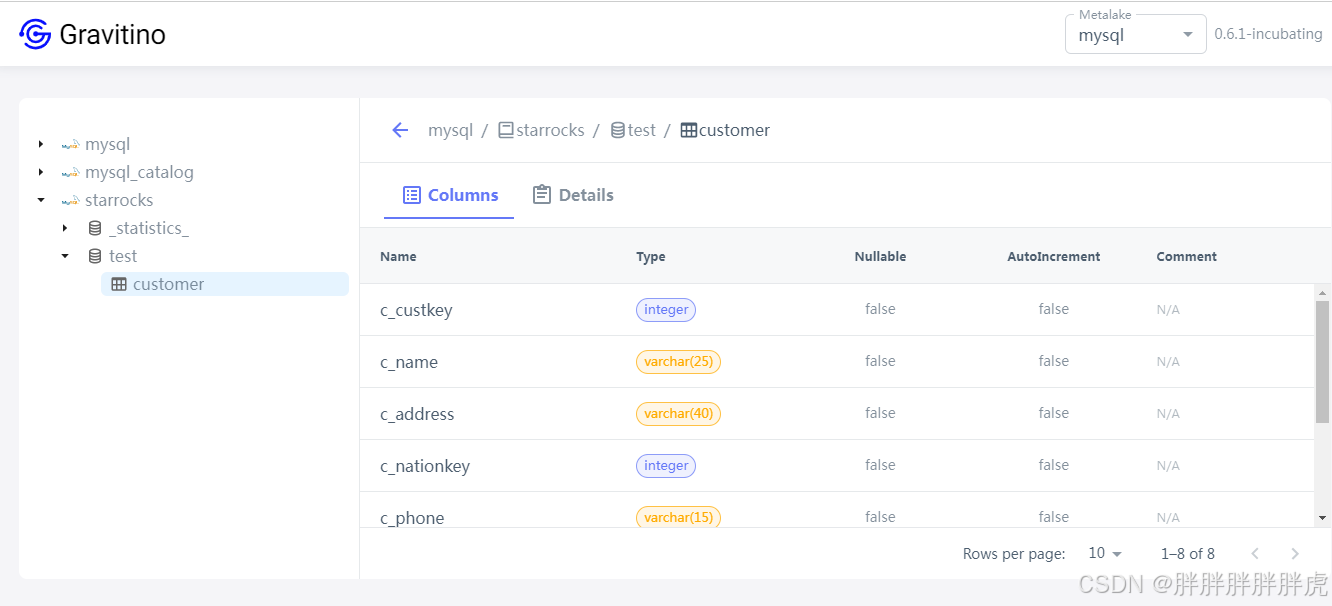
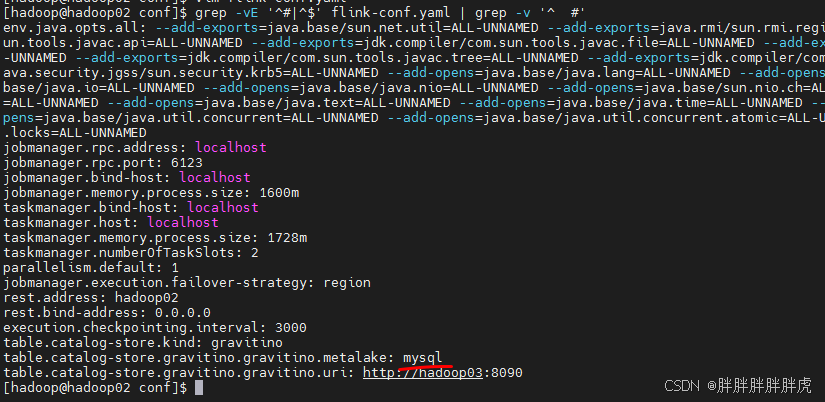
mysql
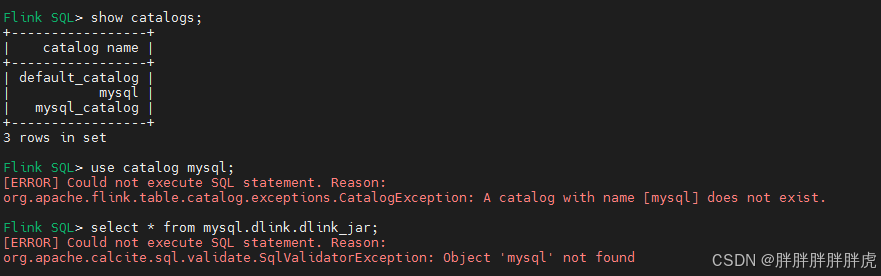
org.apache.flink.table.catalog.exceptions.CatalogException: A catalog with name [mysql] does not exist.
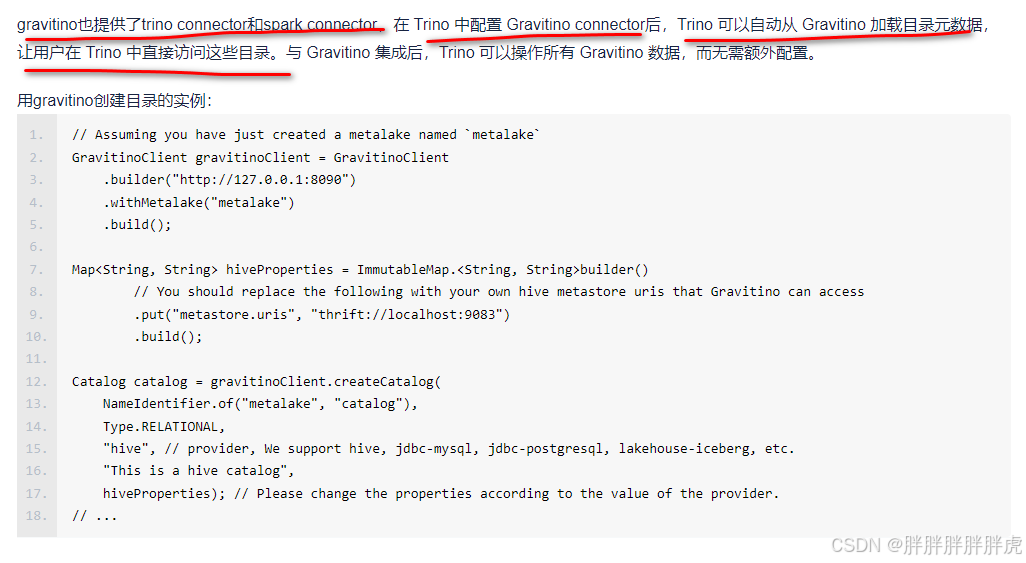
gravitino trino 与 spark connector

















 1608
1608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









