







一、集群管理
系统要求
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
在线安装rmp包
yum install yum-utils
rpm --import https://repo.yandex.ru/clickhouse/CLICKHOUSE-KEY.GPG
yum-config-manager --add-repo https://repo.yandex.ru/clickhouse/rpm/stable/x86_64
yum install clickhouse-server clickhouse-client
离线安装rmp包
wget https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/clickhouse-common-static-19.17.9.60-2.x86_64.rpm
wget https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/clickhouse-server-19.17.9.60-2.noarch.rpm
wget https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/clickhouse-client-19.17.9.60-2.noarch.rpm
rpm -ivh clickhouse-common-static-19.17.9.60-2.x86_64.rpm
rpm -ivh clickhouse-server-19.17.9.60-2.noarch.rpm
rpm -ivh clickhouse-client-19.17.9.60-2.noarch.rpm
技术实现
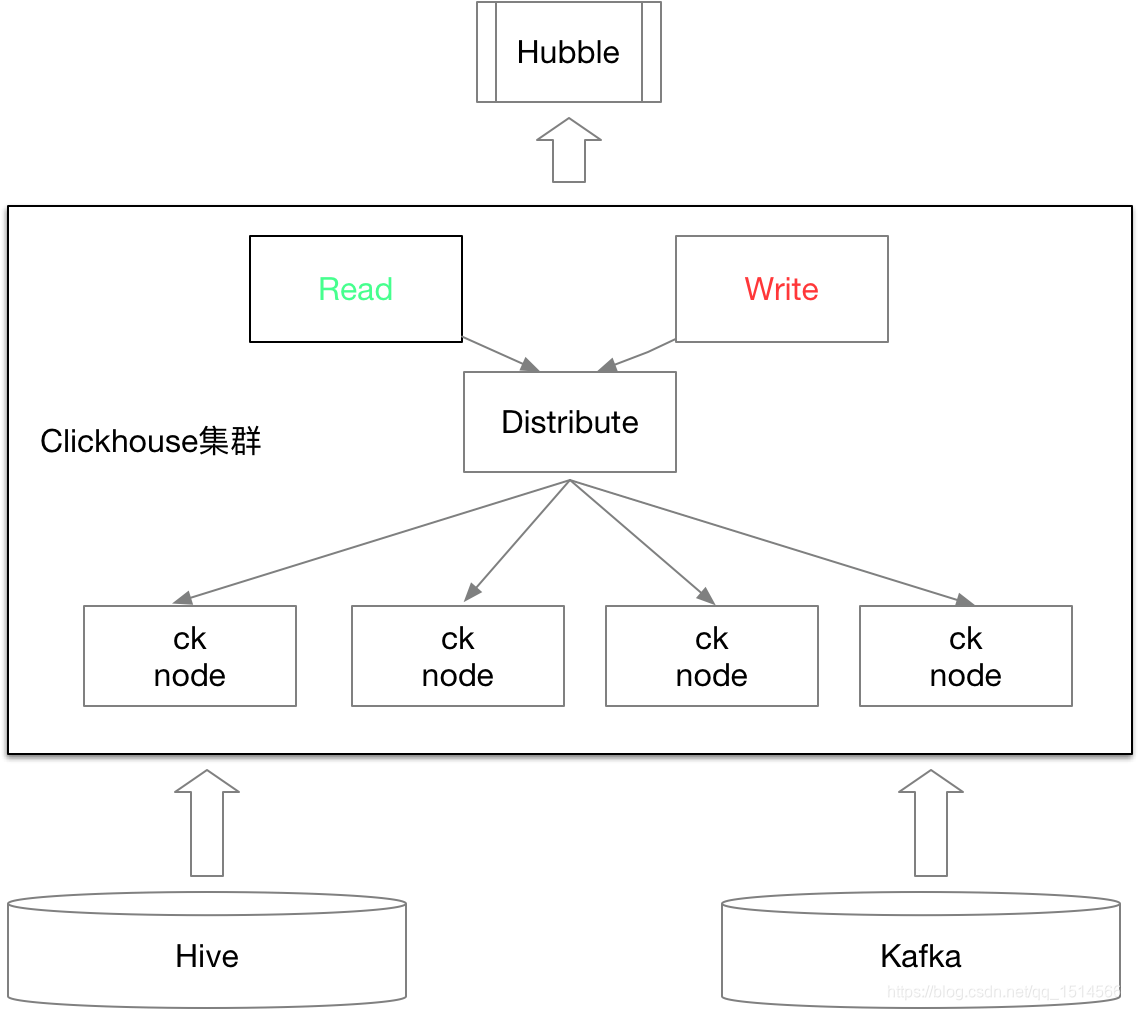
方案一(见下图)
(1)写入时,数据写入分布式表,通过分布式表写入各个本地表
(2)查询时,通过分布式表路由到各个本地表进行查询数据后,合并查询的数据返回给客户端
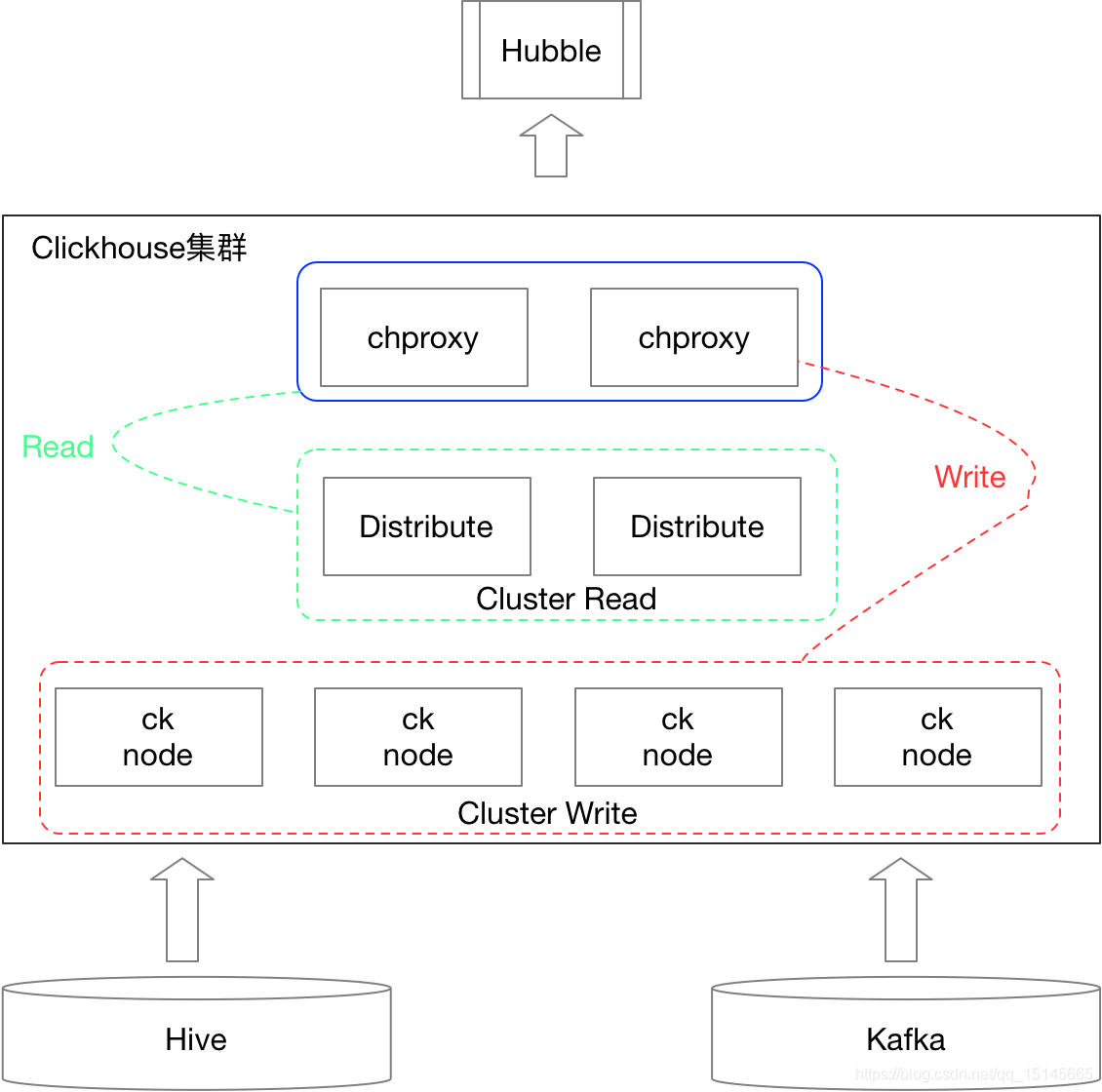
方案二(见下图)
(1)写入时,通过代理轮询写入到各个本地表中,实现数据负载均衡
(2)查询时,通过代理查询分布式表,分布式表路由到各个本地表进行查询数据后,合并查询的数据返回给代理
config.d配置目录
cd /etc/clickhouse-server/config.d
cluster配置config.d/server.xml
<remote_servers incl="clickhouse_remote_servers" >
<cluster_shard_false_replicated>
<shard>
<internal_replication>false</internal_replication>
<replica>
<host>bx00.test.com</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>false</internal_replication>
<replica>
<host>bx01.test.com</host>
<port>9000</port>
</replica>
</shard>
</cluster_shard_false_replicated>
<cluster_shard_true_replicated>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>bx00.test.com</host>
<port>9000</port>
</replica>
<replica>
<host>bx01.test.com</host>
<port>9000</port>
</replica>
</shard>
</cluster_shard_true_replicated>
</remote_servers>
zookeeper配置config.d/zookeeper.xml
<zookeeper incl="zookeeper-servers" optional="true" />
<zookeeper>
<node>
<host>bx01.test.com<</host>
<port>2181</port>
</node>
</zookeeper>
宏定义配置config.d/macros.xml,(replica保证唯一性)
<macros incl="macros" optional="true" />
<macros>
<cluster>cluster_shard_true_replicated</cluster>
<shard>00</shard>
<replica>bx01.test.com</replica>
</macros>
graphite配置config.d/graphite.xml
<graphite>
<host>bx01.test.com</host>
<port>2003</port>
<timeout>0.1</timeout>
<interval>1</interval>
<root_path>one_sec</root_path>
<metrics>true</metrics>
<events>true</events>
<events_cumulative>false</events_cumulative>
<asynchronous_metrics>false</asynchronous_metrics>
</graphite>
多磁盘配置config.d/storage.xml
<storage_configuration>
<disks>
<disk1> <!-- disk name -->
<path>/data1/clickhouse</path>
<keep_free_space_bytes>10737418240</keep_free_space_bytes> <!-- disk free space byte -->
</disk1>
<disk2>
<path>/data2/clickhouse</path>
<keep_free_space_bytes>10737418240</keep_free_space_bytes>
</disk2>
<disk3>
<path>/data3/clickhouse</path>
<keep_free_space_bytes>10737418240</keep_free_space_bytes>
</disk3>
<disk4>
<path>/data4/clickhouse</path>
<keep_free_space_bytes>10737418240</keep_free_space_bytes>
</disk4>
<disk5>
<path>/data5/clickhouse</path>
<keep_free_space_bytes>10737418240</keep_free_space_bytes>
</disk5>
<disk6>
<path>/data6/clickhouse</path>
<keep_free_space_bytes>10737418240</keep_free_space_bytes>
</disk6>
<disk7>
<path>/data7/clickhouse</path>
<keep_free_space_bytes>10737418240</keep_free_space_bytes>
</disk7>
<disk8>
<path>/data8/clickhouse</path>
<keep_free_space_bytes>10737418240</keep_free_space_bytes>
</disk8>
<disk9>
<path>/data9/clickhouse</path>
<keep_free_space_bytes>10737418240</keep_free_space_bytes>
</disk9>
<disk10>
<path>/data10/clickhouse</path>
<keep_free_space_bytes>10737418240</keep_free_space_bytes>
</disk10>
</disks>
<policies>
<round>
<volumes>
<hdd>
<disk>disk1</disk>
<disk>disk2</disk>
<disk>disk3</disk>
<disk>disk4</disk>
<disk>disk5</disk>
<disk>disk6</disk>
<disk>disk7</disk>
<disk>disk8</disk>
<disk>disk9</disk>
<disk>disk10</disk>
</hdd>
</volumes>
</round>
</policies>
</storage_configuration>
多磁盘创建目录及磁盘权限
mkdir -p /data1/clickhouse
mkdir -p /data2/clickhouse
mkdir -p /data3/clickhouse
mkdir -p /data4/clickhouse
mkdir -p /data5/clickhouse
mkdir -p /data6/clickhouse
mkdir -p /data7/clickhouse
mkdir -p /data8/clickhouse
mkdir -p /data9/clickhouse
mkdir -p /data10/clickhouse
chown -R clickhouse:clickhouse /data1/clickhouse
chown -R clickhouse:clickhouse /data2/clickhouse
chown -R clickhouse:clickhouse /data3/clickhouse
chown -R clickhouse:clickhouse /data4/clickhouse
chown -R clickhouse:clickhouse /data5/clickhouse
chown -R clickhouse:clickhouse /data6/clickhouse
chown -R clickhouse:clickhouse /data7/clickhouse
chown -R clickhouse:clickhouse /data8/clickhouse
chown -R clickhouse:clickhouse /data9/clickhouse
chown -R clickhouse:clickhouse /data10/clickhouse
日志配置config.d/logger.xml
<logger>
<!-- Possible levels: https://github.com/pocoproject/poco/blob/develop/Foundation/include/Poco/Logger.h#L105 -->
<level>trace</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>100M</size>
<count>10</count>
<!-- <console>1</console> --> <!-- Default behavior is autodetection (log to console if not daemon mode and is tty) -->
</logger>
kafka配置config.d/kafka.xml
<!-- Global configuration options for all tables of Kafka engine type -->
<kafka>
<debug>cgrp</debug>
<auto_offset_reset>smallest</auto_offset_reset>
</kafka>
<!-- Configuration specific for topic "logs" -->
<kafka_logs>
<retry_backoff_ms>250</retry_backoff_ms>
<fetch_min_bytes>100000</fetch_min_bytes>
</kafka_logs>
问题
1、扩容数据如何均衡(两种方案,默认使用第二种方案)?
(1)把依赖配置的cluster表全部创建临时表,把旧表的数据导入临时表中,然后重新命名临时表,这种方法比较暴力,如果有长期积累的大数据量表,会造成数据插入临时表耗时
(2)首先调整分片的权重,把新节点权重调大一些,写入的时候往新节点上面多写数据,待到数据均衡的时候,在次调整分片权重,让数据再次均衡写入。这种方法普遍使用,需要两次调整分片权重大小。
2、缩容如何数据均衡?
(1)移除该节点的写入,把该节点上面的数据迁移到别的节点上面,删除该节点上面的分片,批量修改配置
3、集群部署方式(两种方式,默认使用第一种方案)
(1)replication cluster
这个方式主要是每两台机器建立一个分片,一个分片有两个副本,如果做一次请求查询,集群的机器只有一半的机器做查询响应。如果对大数据量一次请求查询的话,整体集群机器的性能发挥不出来
(2)circular replication cluster
这个方式主要是每两台机器建立两个分片,一个分片有两个副本,如果做一次请求查询,集群的机器会全部做查询响应。如果对大数据量一次请求查询的话,整体集群机器的性能可以发挥出来,不过需要一台机器起两个ck服务,多并发的情况下,会导致CPU资源比较紧张
二、数据表管理
批量导入
创建数据库
CREATE DATABASE IF NOT EXISTS dw_video
创建本地表
CREATE TABLE dw_video.dw_wapvideoper_dim_hour_local (
`fday` Date,
`fdate` DateTime,
`system_version` String,
`system` String,
`app_version` String,
`mobile_manufacturer` String,
`mobile_model` String,
`country` String,
`province` String,
`city` String,
`isp` String,
`cdn_country` String,
`cdn_province` String,
`cdn_isp` String,
`network` String,
`video_cdn` String,
`business_type` String,
`protocal` String,
`error_code` String,
`domain` String,
`video_scale` String,
`is_free` String,
`file_size` String,
`header_size` String,
`video_type` String,
`video_cache_type` String,
`is_valid` String,
`play_total` Nullable(Int64),
`download_size_total` Nullable(Int64),
`download_size_ff_total` Nullable(Int64),
`firstframe_success_total` Nullable(Int64),
`base_stall_play_total` Nullable(Int64),
`stall_total` Nullable(Int64),
`stall_play_total` Nullable(Int64),
`stall_pd500ms_total` Nullable(Int64),
`stall_sd500ms_total` Nullable(Int64),
`play_duration_total` Nullable(Int64),
`firstframe_duration_total` Nullable(Int64),
`firstframe_success_duration_total` Nullable(Int64),
`base_stall_duration_total` Nullable(Int64),
`stall_duration_total` Nullable(Int64),
`firstframe_psr1_total` Nullable(Int64),
`firstframe_ccl1_total` Nullable(Int64),
`firstframe_cancel_total` Nullable(Int64),
`firstframe_error_total` Nullable(Int64),
`quit_status_cancel_total` Nullable(Int64),
`quit_status_error_total` Nullable(Int64),
`quit_status_complete_total` Nullable(Int64)
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{cluster}-{shard}/dw_wapvideoper_dim_hour_local', '{replica}')
PARTITION BY fday
PRIMARY KEY fdate
ORDER BY (fdate, system_version, system, app_version, mobile_manufacturer, mobile_model, country, province, city, isp, cdn_country, cdn_province, cdn_isp, network, video_cdn, business_type, protocal, error_code, domain, video_scale, is_free, file_size, header_size, video_type, video_cache_type, is_valid)
TTL fdate + INTERVAL 30 DAY
SETTINGS index_granularity = 8192,
storage_policy = 'round'
创建复制表
CREATE TABLE dw_video.dw_wapvideoper_dim_hour AS dw_video.dw_wapvideoper_dim_hour_local ENGINE = Distributed(cluster_shard_true_replicated, dw_video, dw_wapvideoper_dim_hour_local, rand())
jdbc导入数据
public class ClickhouseImportApplication {
private static final Logger LOGGER = LoggerFactory.getLogger(ClickhouseImportApplication.class);
public static void main(String[] args) {
SparkSession session = null;
try {
SparkConf conf = new SparkConf();
conf.setAppName("test");
session = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate();
String sql =
StringUtils.join(
IOUtils.readLines(
ClickhouseImportApplication.class.getClassLoader()
.getResourceAsStream("dw_wapvideoper_dim_hour.sql"),
CharEncoding.UTF_8)
.stream()
.map(String::trim)
.iterator(),
" ");
LOGGER.info("execute sql: {}", sql);
Map<String, String> jdbcOptions = new HashMap<>();
jdbcOptions.put("dbtable", "dw_video.dw_wapvideoper_dim_hour");
jdbcOptions.put("driver", "ru.yandex.clickhouse.ClickHouseDriver");
jdbcOptions.put("url", "jdbc:clickhouse://bx01.test.com:8123");
jdbcOptions.put("batchSize", "100000");
jdbcOptions.put("isolationLevel", "NONE");
session.sql(sql).write().mode("append")
.options(jdbcOptions)
.format("jdbc")
.save();
} catch (Exception e) {
LOGGER.error(ExceptionUtils.getFullStackTrace(e));
} finally {
if (Objects.nonNull(session)) {
session.close();
}
}
}
}
分布式表查询
select count(1) from dw_video.dw_wapvideoper_dim_hour
实时导入
创建消费引擎
CREATE TABLE test_consumer (
fdate Int64,
upload_total Float64,
succ_total Float64,
upload_succ_total Float64,
upload_error_total Float64,
upload_cancel_total Float64,
client_total_speed Float64,
client_total_speed_err Float64,
client_total_duration Float64,
network String,
country String,
province String,
isp String,
video_size_group String,
total_speed_group String,
error_code String
) ENGINE = Kafka SETTINGS kafka_broker_list = 'first.kafka.titan.test.com:9092,second.kafka.titan.test.com:9092,third.kafka.titan.test.com:9092,fourth.kafka.titan.test.com:9092',
kafka_topic_list = 'test',
kafka_group_name = 'clickhouse-test',
kafka_format = 'JSONEachRow',
kafka_num_consumers = 4;
创建本地表
CREATE TABLE test_local (
fday Date,
fdate DateTime,
upload_total Float64,
succ_total Float64,
upload_succ_total Float64,
upload_error_total Float64,
upload_cancel_total Float64,
client_total_speed Float64,
client_total_speed_err Float64,
client_total_duration Float64,
network String,
country String,
province String,
isp String,
video_size_group String,
total_speed_group String,
error_code String
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{cluster}-{shard}/test_local', '{replica}')
PARTITION BY fday
PRIMARY KEY fdate
ORDER BY (fdate, network,country,province,isp,video_size_group,total_speed_group,error_code)
TTL fdate + INTERVAL 30 DAY
SETTINGS index_granularity = 8192,
storage_policy = 'round'
创建分布式表
CREATE TABLE test_all AS test_local ENGINE = Distributed(cluster_shard_true_replicated, default, test_local, rand())
创建物化视图,该视图会将在后台转换消费引擎中的数据并将其放入之前创建的分布式表中
CREATE MATERIALIZED VIEW test_events TO test_all AS SELECT toDate(fdate/1000, 'Asia/Shanghai') AS fday, toDateTime(fdate/1000, 'Asia/Shanghai') AS fdate, upload_total, succ_total, upload_succ_total, upload_error_total, upload_cancel_total, client_total_speed, client_total_speed_err, client_total_duration,network,country,province,isp,video_size_group,total_speed_group,error_code FROM test_consumer;
分布式表查询
select count(1) from test_all
表操作
删除本地表及分布式表
drop table dw_video.dw_wapvideoper_dim_hour
drop table dw_video.dw_wapvideoper_dim_hour_local
修改表的数据过期时间
ALTER TABLE dw_video.dw_wapvideoper_dim_hour_local
MODIFY TTL fdate + INTERVAL 30 DAY
增加表字段, 增加字段只会更改表结构,而不会对数据执行任何操作,如果数据读取时添加的字段缺少数据,则用默认值(如果有默认值,则执行默认表达式,如果没有默认值则数字类型使用0或者字符串类型使用"")
ALTER TABLE dw_video.dw_wapvideoper_dim_hour ADD COLUMN china_city String AFTER city
ALTER TABLE dw_video.dw_wapvideoper_dim_hour_local ADD COLUMN china_city String AFTER city, MODIFY ORDER BY (fdate, city, china_city)
删除表字段
ALTER TABLE dw_video.dw_wapvideoper_dim_hour DROP COLUMN china_city
ALTER TABLE dw_video.dw_wapvideoper_dim_hour_local DROP COLUMN china_city, MODIFY ORDER BY (fdate, city)
更新字段类型及字段名,ck无法修改字段的名称,ck更改字段类型就是应用toType函数转换值类型
ALTER TABLE dw_video.dw_wapvideoper_dim_hour_local MODIFY COLUMN china_city Int64
字段名无法通过alter command修改,可以通过创建临时表,将现在数据导入临时表,最后将临时表重新命名的方法去修改字段
三、数据管理
删除数据,只能针对本地表进行删除
ALTER TABLE dw_video.dw_wapvideoper_dim_hour_local DELETE WHERE isp = 'other'
ALTER TABLE dw_video.dw_wapvideoper_dim_hour_local DELETE WHERE fdate >= '2020-01-12 00:00:00' AND fdate <= '2012-01-12 12:00:00'
分区操作
下线分区
alter table user_center_local detach partition 20200123;
删除分区
alter table user_center_local drop partition 20200123;
恢复分区
alter table user_center_local attach partition 20200123;
备份分区
alter table user_center_local freeze partition 20200123;
删除完分区做恢复分区操作
(1)对分区进行备份 alter table user_center_local freeze partition 20200123;
(2)对分区进行删除 alter table user_center_local drop partition 20200123;
(3)复制备份的数据到该表detached目录下 cp -rp /data1/clickhouse/shadow/1/data/realtime/user_center_local/20200123_652455_652455_0 /data1/clickhouse/data/realtime/user_center_local/detached/
(4)恢复分区 alter table user_center_local attach partition 20200123;
四、性能测试
配置说明
机器配置:2台机器cpu 20核,内存 128G,磁盘 5T
数据量:26亿条
clickhouse两种cluster模式
(1)1shard2replica internal_replication=true
(2)2shard1replica internal_replication=false
(3)第一种cluster模式两台机器建立一个分片,写入时,会从其中一个replica写入,通过zk复制机制复制数据,查询时,分布式表从其中一个replica查询。可以实现高可用模式,两台机器一台宕机,不影响查询数据,但是只有一台机器做查询响应。第二种cluster方式两台机器建立两个分片,写入时,会写入两个分片的replica,查询时,分布式表从两个分片的replica查询。可以实现高性能模式,两台机器同时查询,但是一台宕机,无法查询数据。
count性能测试(clickhous默认使用物理核数,机器的默认物理核数是10核)
测试sql: select count() from realtime.user_center where fdate >= '2020-01-19 00:00:00' and fdate <= '2020-01-19 23:59:59'
(1)1shard2replica 查询响应时间大约2.8s
(2)2shard1replica 查询响应时间大约1.4s
group by性能测试(clickhous默认使用物理核数,机器的默认物理核数是10核)
测试sql: select * from (
select object_id,
sum(play_total) as play_total,
sum(valid_play_total) AS valid_play_total,
sum(complete_total) AS complete_total,
sum(fans_play_total) AS fans_play_total
--uniqExact(author_id) author_id, uniqExact(object_id) object_id
from realtime.user_center_local
where object_id like '1034%'
AND fdate >= '2020-01-19 00:00:00'
AND fdate <= '2020-01-19 23:59:59'
group by object_id
) a order by play_total desc
limit 100
(1)1shard2replica 查询响应时间大约52s
(2)2shard1replica 查询响应时间大约33s
(3)由于clickhouse默认使用机器的是物理核数,通过查询CPU使用情况看,在2shard1replica模式下,每台机器cpu使用了50%。clickhouse可以通过配置max_threads来调整查询使用的cpu资源,我们设置max_threads=20,每台机器cpu使用了100%,查询响应时间大约19s
总结
(1)在count方面和group by方面,查询速度很快,消耗内存较大,消耗cpu资源较大,不适合并发较高的业务场景
(2)提供一个clickhouse性能测试文档参考https://www.percona.com/blog/2017/02/13/clickhouse-new-opensource-columnar-database/
五、常见疑惑
replication 四种类型
(1)Non-replicated tables, internal_replication=false
写入到分布式表中的数据被写入到两个本地表中,如果在写入期间没有问题,则两个本地表上的数据保持同步。我们称之为“穷人的复制”,因为复制在网络出现问题的情况下容易发生分歧,没有一个简单的方法来确定哪一个是正确的复制
(2)Non-replicated tables, internal_replication=true
写入到分布式表中的数据只被写入到其中一个本地表中,但没有任何机制可以将它转移到另一个表中。因此,在不同主机上的本地表看到了不同的数据,查询分布式表时会出现非预期的数据。显然,这是配置clickHouse集群的一种不正确的方法
(3)Replicated tables, internal_replication=false
写入到分布式表中的数据被写入到两个本地表中,但同时复制表的机制保证重复数据会被删除。数据会从写入的第一个节点复制到其它的节点。其它节点拿到数据后如果发现数据重复,数据会被丢弃。这种情况下,虽然复制保持同步,没有错误发生。但由于不断的重复复制流,会导致写入性能明显的下降。所以这种配置实际应该是避免的,应该使用配置internal_replication为true
(4)Replicated tables, internal_replication=true
写入到分布式表中的数据被写入到其中一个本地表中,但通过复制机制传输到另一个节点上的表中。因此两个本地表上的数据保持同步。这是推荐的配置















 1350
1350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









