







hadoop jar streaming提交多个模块python文件。
1.python工程结构:
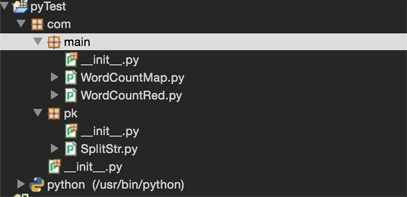
python包分为com/main,com/pk
2.python代码
工具模块 SplitStr.py
#! /usr/bin/env python
#coding=utf-8
'''
Created on 2017年4月18日
@author: lzw
'''
class SplitString(object):
'''
分割字符串
'''
def split_blank(self,msg):
result = msg.split(" ")
return result
mapper WordCountMap.py
#! /usr/bin/env python
#coding=utf-8
'''
Created on 2017年4月18日
@author: lzw
'''
import sys
from com.pk.SplitStr import SplitString
sp = SplitString()
for line in sys.stdin :
line = line.strip()
lSplit = sp.split_blank(line)
for word in lSplit :
print word + "\t" + "1"
#! /usr/bin/env python
#coding=utf-8
'''
Created on 2017年4月18日
@author: lzw
'''
import sys
wordct = {}
for line in sys.stdin :
line = line.strip()
sp = line.split("\t")
if wordct.has_key(sp[0]) :
wordct[sp[0]] = wordct[sp[0]] + 1
else :
wordct[sp[0]] = 1
for item in wordct.items() :
print item[0],item[1]3.处理文件text.txt
You can specify any executable as the mapper and/or the reducer.
The executables do not need to pre-exist on the machines in the cluster; however,
if they don't, you will need to use "-file" option to tell the framework to pack
your executable files as a part of job submission. For example:
For a4. 运行shell脚本
#! /bin/bash
EXEC_PATH=$(dirname "$0")
JAR_PACKAGE=/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-streaming.jar
IN_PATH=/home/lzw/testmodule/input/*
OUT_PATH=/home/lzw/testmodule/output
MAP_FILE=${EXEC_PATH}/com/main/WordCountMap.py
RED_FILE=${EXEC_PATH}/com/main/WordCountRed.py
FILE=${EXEC_PATH}/com
$HPHOME/bin/hadoop jar $JAR_PACKAGE \
-D mapred.job.name=myjob \
-D stream.map.input.ignoreKey=true \
-D map.output.key.field.separator=, \
-D num.key.fields.for.partition=1 \
-D stream.map.output.field.separator='\t' \
-numReduceTasks 3 \
-input $IN_PATH \
-output $OUT_PATH \
-mapper $MAP_FILE \
-reducer $RED_FILE \
-file $FILE \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner
假设运行路径为/home/test/testmodule,在当前目录创建com目录,在com目录下创建main和pk目录,在每个目录创建空__init__.py,将WordCountMap.py和WordCountRed.py提交到main目录下,将SplitStr.py提交到pk目录下。将shell脚本在/home/test/testmodule,上传text.txt到hadoop文件系统目录/home/lzw/testmodule/input/目录下。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









