








1)需求
过滤输入的log日志中是否包含itstar
(1)包含itstar的网站输出到e:/itstar.log
(2)不包含itstar的网站输出到e:/other.log
2)输入数据

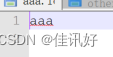
输出预期:

3)具体程序:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class b172 {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
args= new String[]{"D:\\test\\b17\\input\\a.txt","D:\\test\\b17\\output\\b172"};
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(b172.class);
job.setMapperClass(FilterMapper.class);
job.setReducerClass(FilterReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//要将自定义的输出格式组件设置到job中
job.setOutputFormatClass(FilterOutputFormat.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
/**
* 虽然自定义了outputformat,但是因为我们的outputformat继承自fileoutputformt
* 而fileoutputformat要输出一个_SUCCESS文件,所以在这还得指定一个输出目录
*/
FileSystem fs = FileSystem.get(conf);
Path path = new Path(args[1]);
if (fs.exists(path)){
fs.delete(path,true);
}
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
class FilterOutputFormat extends FileOutputFormat<Text, NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext Context) throws IOException, InterruptedException {
return new FiterRecordWriter(Context);
}
}
/**
* text,nullWritable
* reduce的输出类型
*/
class FiterRecordWriter extends RecordWriter<Text, NullWritable> {
FSDataOutputStream aaa = null;
FSDataOutputStream other = null;
public FiterRecordWriter(TaskAttemptContext job) throws IOException {
try (
//1 获取文件系统
FileSystem fs = FileSystem.get(job.getConfiguration())) {
//2 创建输出文件路径
Path aaaPath = new Path("D:\\test\\b17\\output\\b172\\aaa.log");
Path otherPath = new Path("D:\\test\\b17\\output\\b172\\other.log");
//3 创建输出流
aaa = fs.create(aaaPath);
other = fs.create(otherPath);
}
}
@Override
public void write(Text text, NullWritable nullWritable) throws IOException, InterruptedException {
//判断是否包含“aaa”,输出到不同文件
if (text.toString().contains("aaa")){
aaa.write(text.toString().getBytes());
}else {
other.write(text.toString().getBytes());
}
}
@Override
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
//关闭资源
if (aaa!=null){
aaa.close();
}
if (other != null) {
other.close();
}
}
}
class FilterMapper extends Mapper<LongWritable,Text,Text,NullWritable>{
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
//获取一行
// String line = value.toString();
//
// k.set(line);
//输出
context.write(value,NullWritable.get());
}
}
class FilterReducer extends Reducer<Text,NullWritable,Text,NullWritable>{
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
String k = key.toString();
k=k+"\r\n";
System.out.println(k.toString());
context.write(new Text(k),null);
}
}














 1341
1341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









