







 本文介绍了一项使用Python实现的网络爬虫项目,用于抓取全国招聘网站的岗位信息,包括职位、公司、薪资、工作经验等,并进行数据清洗、标准化和可视化,为求职者和招聘者提供决策支持。通过数据可视化展示了地区招聘需求、城市薪资对比、薪资与工作年限的关系等关键信息。
本文介绍了一项使用Python实现的网络爬虫项目,用于抓取全国招聘网站的岗位信息,包括职位、公司、薪资、工作经验等,并进行数据清洗、标准化和可视化,为求职者和招聘者提供决策支持。通过数据可视化展示了地区招聘需求、城市薪资对比、薪资与工作年限的关系等关键信息。
项目代码:https://gitee.com/lovelots/job-information-crawling-and-analysis
1、简介
本次项目设计采用Python网络爬虫爬取招聘网站全国范围内相关岗位的招聘信息,包含:职位、公司名称、公司地点、薪资、工作经验要求和学历要求等信息。通过Python提供丰富的内置模块和第三方库,对数据进行处理和可视化,从而让求职者获得相关岗位的分析数据,最终以Web的形式展示。本文研究的意义在于为招聘企业和求职者提供相关岗位数据分析的信息,指导他们更早地了解新变化和新要求,帮助求职者着手职业规划。
2、总体设计目标
整体项目设计是利用网络爬虫抓取招聘网站相关岗位的招聘信息,包括职位、公司名称、公司地点、薪资、工作经验要求、学历要求和公司福利等信息。将获取的数据进一步处理,包括对一些空值和异常数据进行清洗,以及对单位和格式不统一的数据规范化。再通过Python第三方库将处理好的数据可视化,最终利用前端技术将所有可视化图片合并成一个系统。所要呈现的功能目标包括以下几点:
Top1:清晰展示招聘相关岗位的企业集中在哪些地区或城市。
Top2:探寻主要城市在相关岗位上的薪资与其他地区存在多大的差异。
Top3:了解薪资与哪些因素潜在明显的关系。
Top4:调查相关岗位的招聘企业对应聘者有哪些方面的要求。
Top5:清楚的了解到相关岗位的招聘企业一些相关企业信息。
3、项目设计
本项目总体设计,采用Python语言,利用网络爬虫抓取招聘网站的招聘信息,调用Python内置模块和第三方库,对获取的数据进行处理和可视化,最终将可视化的结果利用Web技术合并成一个整体。首先,在爬虫阶段,通过导入urllib.request模块对发送方信息头部进行包装,设置header,以模仿浏览器访问网页;然后又利用re模块中findall()方法遍历匹配,以获取字符串中所有匹配的字符串,并返回一个列表。在处理数据过程中,导入pandas数据处理模块,调用该模块中read_excel()方法读取Excel表格中的数据,再调用DataFrame()方法将数据创建成二维表格的形式,然后利用列表中dropna()方法和drop()方法清理数据,并且观察数据,将不一致的数据进一步统一。最后的数据可视化同样调用pandas模块中read_excel()方法和DataFrame()方法获取想要的数据,并通过导入pyecharts图表模块完成Geo图、词云、漏斗图、饼图、折线图、柱状图等图的绘制。在编写代码过程中,需使用try…except…结构进行异常处理。
3.1、数据获取
获取招聘网站相关岗位的招聘信息是利用网络爬虫技术进行抓取,并将返回的招聘信息采用Excel表格进行存取。通常情况下,用户想要申请访问网页是通过输入URL地址,然后浏览器将URL地址解析成IP地址,以致利用网络将其传送到服务端,并向服务器发起浏览请求。当服务器允许的情况下,返回给浏览器网页内容,最后浏览器将数据反馈给用户。然而,网络爬虫就是模仿用户行为,对招聘网站相关岗位的招聘信息进行抓取。如下图3-1 访问网页过程所示。

在进行网络爬虫之前,为了应对招聘网站中的反爬机制,需要对header头部信息进行设置,模拟浏览器访问网站;并且调用xlwt库中的Workbook()方法完成Excel表格的建立,使用write()方法将表头信息填写完整,完成Excel表格的初始化。
接着采用网络爬虫,需先获得招聘网站相关岗位招聘信息网页的URL,利用招聘网站主页地址和通过urllib.parse模块中quote()方法对想抓取岗位的字符串进行编码,以及爬取的页码进行拼接,最终获取想要的网页地址。然后,根据聘网站相关岗位招聘信息网页的URL调用urllib.request模块中urlopen()方法获得网页内容,并利用read()方法获取urlopen()方法所返回的数据。读取的数据是二进制流的形式,如果想让用户读懂网页程序,就需调用urllib.request模块中decode()方法,将二进制流数据进一步进行转化。然后采用re库中compile()方法生成一个正则表达式对象,调用findall()方法利用这一则正则表达式对转换完成的HTML中的字符串进行模式匹配,将符合要求的字符串利用write()方法写入Excel表格当中。其中,每当抓取一条数据完之后,都需调用time模块中的sleep()方法执行停留步骤,避免爬取海量数据时被误判为攻击,IP遭到封禁。
正常情况下,采用for循环获取属性值的text文本,并将其添加到列表中;而遇到文本text为空的属性值时,就需将NaN属性值添加进列表中,从而使得列表长度一致,以应对分析网页时出现的空值现象。这样,当爬取完信息,并输入数据框时,就不会出现长度不一的错误。
3.2、数据处理
在获取海量原始数据中,许多存在不完整、不一致以及异常等问题,这些问题严重影响爬取后的数据进一步提取及应用。因此在进行数据可视化之前,要先对所获取的数据进行处理。爬取招聘网站相关岗位的招聘信息中主要存在所填写的公司位置地级市不统一、空值、异常数据、薪资单位不同的情况,空值主要呈现在薪资、公司规模和公司福利上,异常数据集中在学历上。如下图3-2 未经处理的Excel表格数据所示。

从获取招聘网站相关岗位的Excel表格数据可以观察到许多数据还需进一步处理。在针对数据空值这类问题,首先调用pandas库中的read_excel()方法读取Excel表格中的数据,再利用DataFrame()方法将读取的数据转换成二维表格的形式,然后利用dropna()方法删除所有包含NaN的数据。
对于所填写公司位置地级市不统一这类问题,可从Excel表格中观察到公司地点这列数据主要分为两种情况;一种是只填写了市级地点;另一种是填写市级加上县级地点,中间以“-”分隔符分开。所以想要将数据统一,可以使用split()方法将市级地点和县级地点分开,并将市级地点将原有数据进行替换。还有个别公司填写的公司地址为省份形式,通过使用drop()方法将其整行数据剔除。并且发现异常的数据集中在学历上,而且异常数据都是在学历上出现该公司的招聘人数,处理方法是将各公司学历要求导入列表中,通过for循环找出异常数据,并调用drop()方法将其删除。
然而面对薪资单位不同这类问题,其解决办法是将各公司薪资导入列表中,如果列表存在“千/月”就提起其数字除以10,就变成了“万/月”的单位;如果存在“万/年”的就提起数字除以12,就变成了“万/月”的单位,在提取数字过程中,我们使用re库中findall()方法进行遍历匹配;在Excel表格数据存在一小部分薪资为“元/天”和“元/小时”的情形,由于这种情况很少,所以使用drop()方法将其删除。最后调用to_excel()方法将其数据保存为另一表格中,处理完的数据如下图3-3 已处理Excel表格数据所示。

通过观察已处理Excel表格数据,可以发现招聘网站相关岗位数据中公司地点地级市一致,薪资单位都以“万/月”为单位,再无空值和异常数据,初步完成数据的处理。
3.3、数据可视化
如果只是爬取数据而不去可视化处理,那么可以说数据的价值根本没有发挥其作用,所以数据可视化处理能使数据更加直观表现出来,更有利于数据分析。在进行数据可视化之前,还需对数据进一步处理,由于读入的数据是以类似于一维数组类型的Series数据结构,需将数据一个一个转换成列表的形式,便于数据进一步处理。
由于爬取招聘网站相关岗位的招聘信息时,是将整家公司的公司福利一起抓取下来,而且每家企业都有好几种公司福利,并观察到爬取数据中每种公司福利都以空格隔开,需要调用split()方法将各种公司福利进行分离。然而,薪资部分的数据呈现“最低薪资-最高薪资”的形式,利用re库中findall()方法,根据正则表达式,将数据分离,取最低薪资作为薪资数据。
其中,大部分数据还需进行统计,比如,在绘制Geo图时,需要对公司地点中各城市出现的频率进行统计;在绘制学历占比时,需要统计各公司对于学历要求情况;同理,工作经验、公司福利、公司性质都需要这要的处理。统计过程主要是自定义方法,利用count()方法对各类招聘信息数据列表进行计算,最后返回字典类型的数据。然而,在绘制薪资与学历和工作经验关系图时,统计数据是先建立空数据字典,键值是根据不同学历和工作经验进行建立,数值采用列表方式,依据各类学历要求的薪资进行划分,再调用numpy库中mean()方法对划分好的薪资数据进行求平均操作。
在获取绘图所需数据后,需导入pyecharts.charts模块的Funnel、Pie、Geo、WordCloud、Line、Bar子模块对漏斗图、饼图、Geo图、词云、折线图、柱状图进行绘制,其中通过add()方法导入数据,并通过set_global_opts()方法进行数据处理图标、图例等参数进行设置,绘制后的各类图通过调用render()方法将数据存入HTML文件中。
最终的数据分析结果是以前端展示,所需要的Web页面还是相对简单,主要是以侧边功能选项和中间数据可视化结果显示构成。侧边功能选项利用列表形式,在每个li标签中嵌套a标签。而中间数据可视化结果模块采用iframe标签将可视化后的HTML文件嵌入到当前网页中。其中各类标签使用的各种样式是引用别人分装好的css。
4、部分数据可视化结果展示
4.1、各地区招聘需求分布

4.2、主要城市薪资
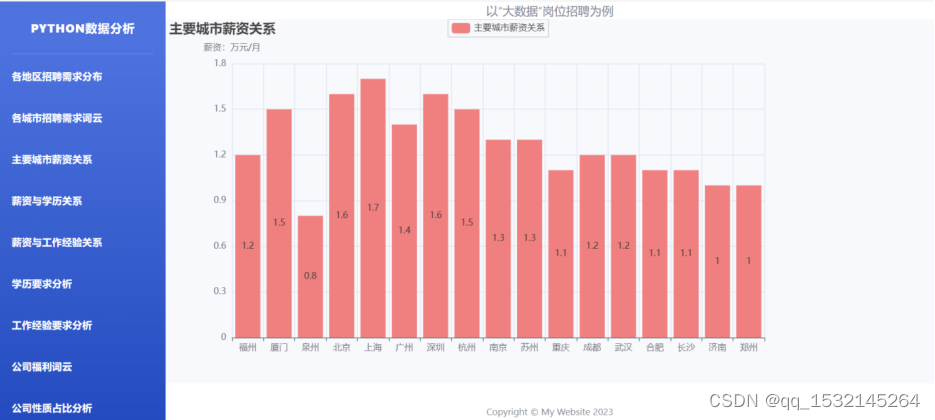
4.3、薪资与工作经验关系
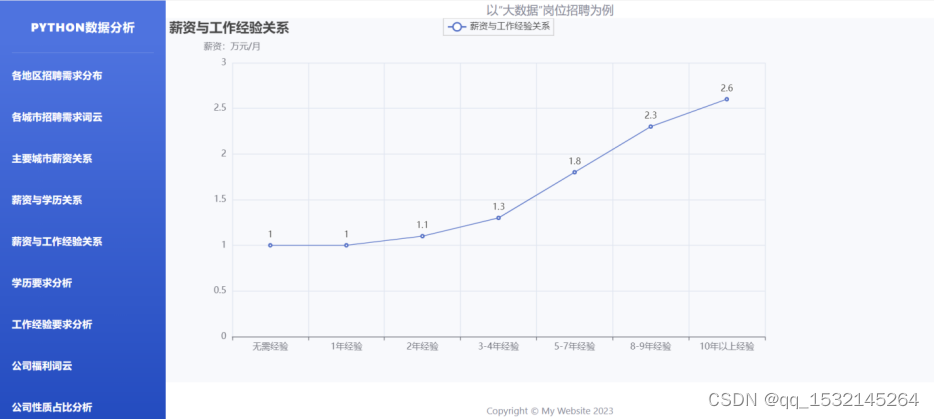
4.4、学历要求饼图
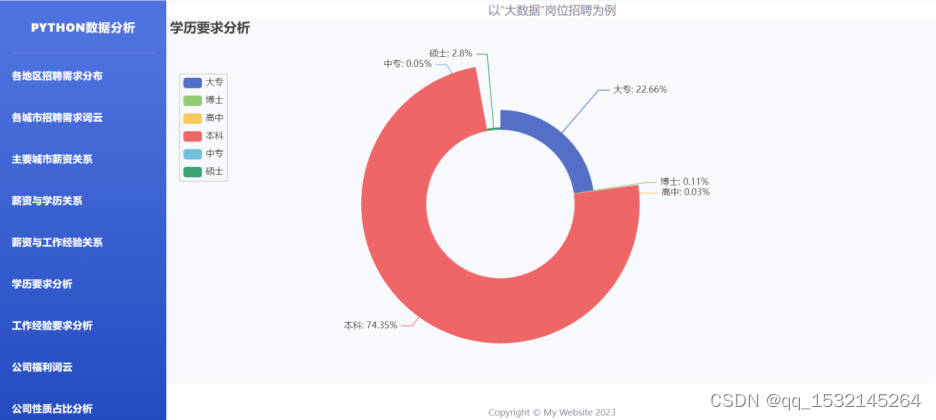
4.5、公司福利词云

具体代码在文章顶部gitee网址


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









