










Excel 文件
Microsoft Excel 几乎无处不在,使用 Excel 既可以保存客户、库存和雇员数据,还可以跟踪运营、销售和财务活动。人们在商业活动中使用 Excel 的方式五花八门,难以计数。因为 Excel 是商业活动中不可或缺的工具,所以知道如何使用 Python 处理 Excel 数据可以使你将 Python 加入到数据处理工作流中,进而从其他人那里接收数据,并以他们习惯接受的方式分享数据处理结果。
与 Python 的 csv 模块不同,Python 中没有处理 Excel 文件(就是带有 .xls 和 .xlsx 扩展名的文件)的标准模块。需要 xlrd 和 xlwt 扩展包。xlrd 和 xlwt 扩展包使 Python 可以在任何操作系统上处理 Excel 文件,而且对 Excel 日期型数据的支持非常好。如果你安装了 Anaconda Python,那么就已经有了这两个扩展包,因为它们是与安装程序捆绑在一起的。如果你是从 Python.org 网站安装的 Python,那么还需要按照附录 A 中的指示下载并安装这两个扩展包。
简单解释一下术语:当提到“Excel 文件”时,和“Excel 工作簿”是一回事。Excel 工作簿包含一个或多个 Excel 工作表。
需要先创建一个 Excel 工作簿。
(1) 打开 Microsoft Excel。
(2) 在工作簿中添加 3 个独立的工作表,并分别命名为 january_2013、february_2013 和 march_2013。然后分别添加数据,如图 1、图 2 和图 3 所示。
(3) 将工作簿保存为 sales_2013.xlsx。

图 1:工作表 1:january_2013

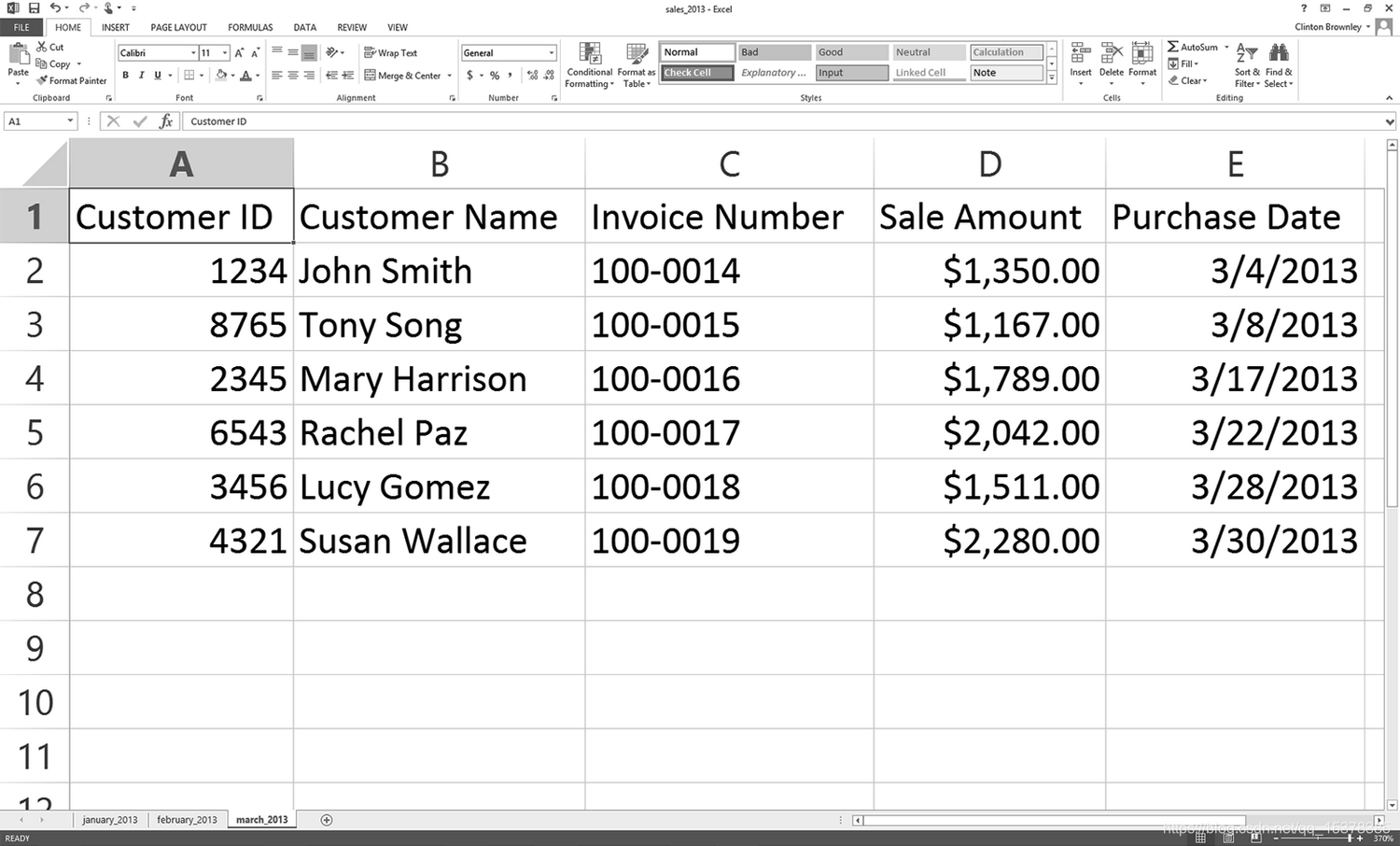
图 2:工作表 2:february_2013
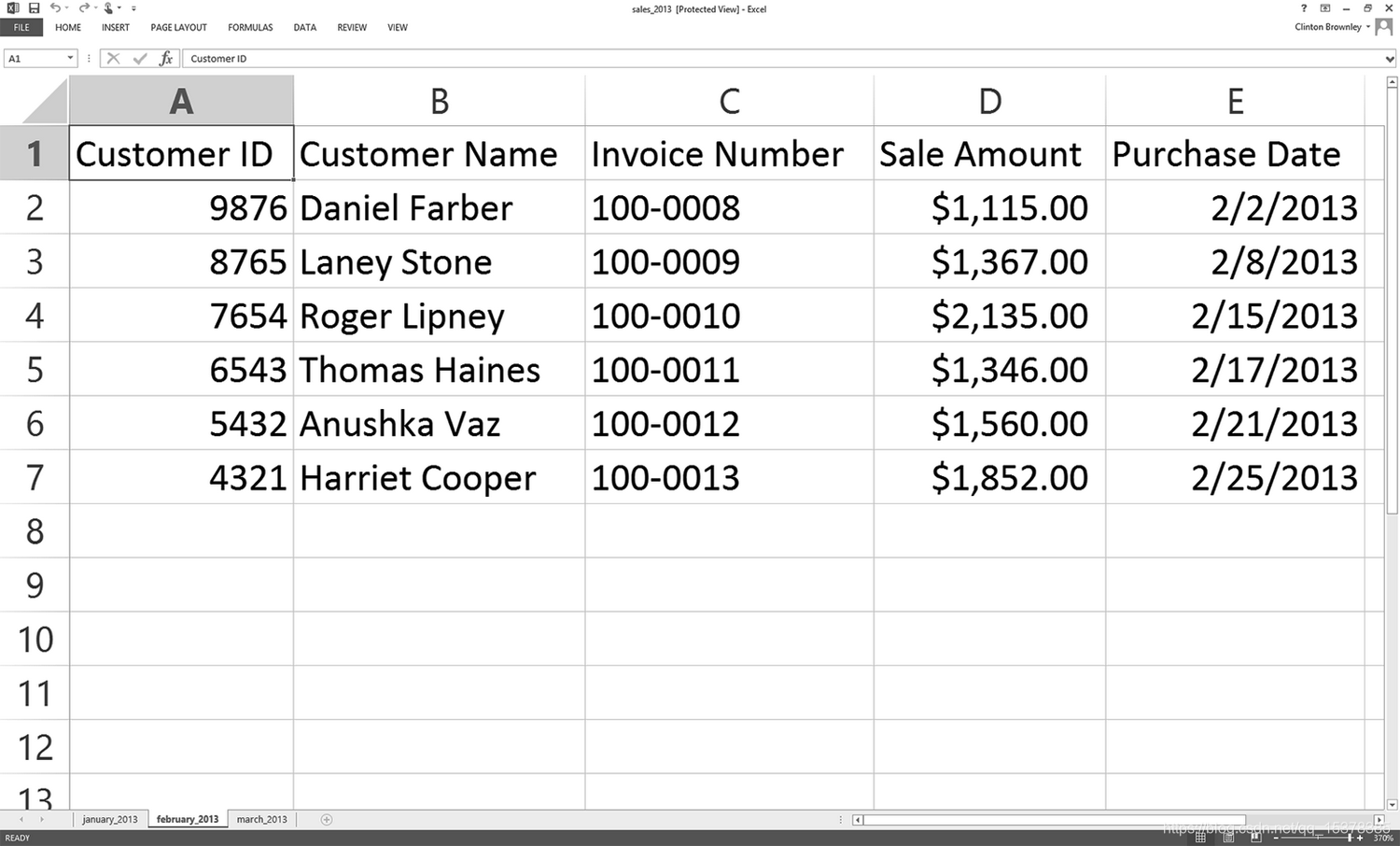
图 3:工作表 3:march_2013
1 内省Excel工作簿
既然我们已经有了一个包含 3 个工作表的 Excel 工作簿,那么就开始学习如何在 Python 中处理 Excel 工作簿吧。提示一下,要使用 xlrd 和 xlwt 扩展包,所以请确认你已经下载并安装了这些扩展包。
你可能已经知道,Excel 文件与 CSV 文件至少在两个重要方面有所不同。首先,与 CSV 文件不同,Excel 文件不是纯文本文件,所以你不能在文本编辑器中打开它并查看数据。为了验证这一点,可以点击刚才创建的 Excel 工作簿并按鼠标右键,然后用一个文本编辑器(比如 Notepad 或者 TextWrangler)打开它。你会看到一堆乱码,而不是正常字符。
其次,与 CSV 文件不同,一个 Excel 工作簿被设计成包含多个工作表,所以你需要知道在不用手动打开工作簿的前提下,如何通过工作簿内省(也就是内部检查)获取其中所有工作表的信息。通过内省一个工作簿,你可以在实际开始处理工作簿中的数据之前,检查工作表的数目和每个工作表中的数据类型和数据量。
内省 Excel 文件有助于确定文件中的数据确实是你需要的,并对数据一致性和完整性做一个初步检查。也就是说,弄清楚输入文件的数量,以及每个文件中的行数和列数,可以使你对数据处理工作的工作量和文件内容的一致性有个大致的概念。
在知道了如何内省工作簿中的工作表之后,下面开始分析单个工作表,然后处理多个工作表和多个工作簿。
要确定工作簿中工作表的数量、名称和每个工作表中行列的数量,在文本编辑器中输入下列代码,然后将文件保存为 excel_introspect_workbook.py:
1 #!/usr/bin/env python3
2 import sys
3 from xlrd import open_workbook
4 input_file = sys.argv[1]
5 workbook = open_workbook(input_file)
6 print('Number of worksheets:', workbook.nsheets)
7 for worksheet in workbook.sheets():
8 print("Worksheet name:", worksheet.name, "\tRows:",\
9 worksheet.nrows, "\tColumns:", worksheet.ncols)
图 4、图 5 和图 6 分别展示了 Anaconda Spyder、Notepad++(Windows)和 TextWrangler(macOS)中的脚本。
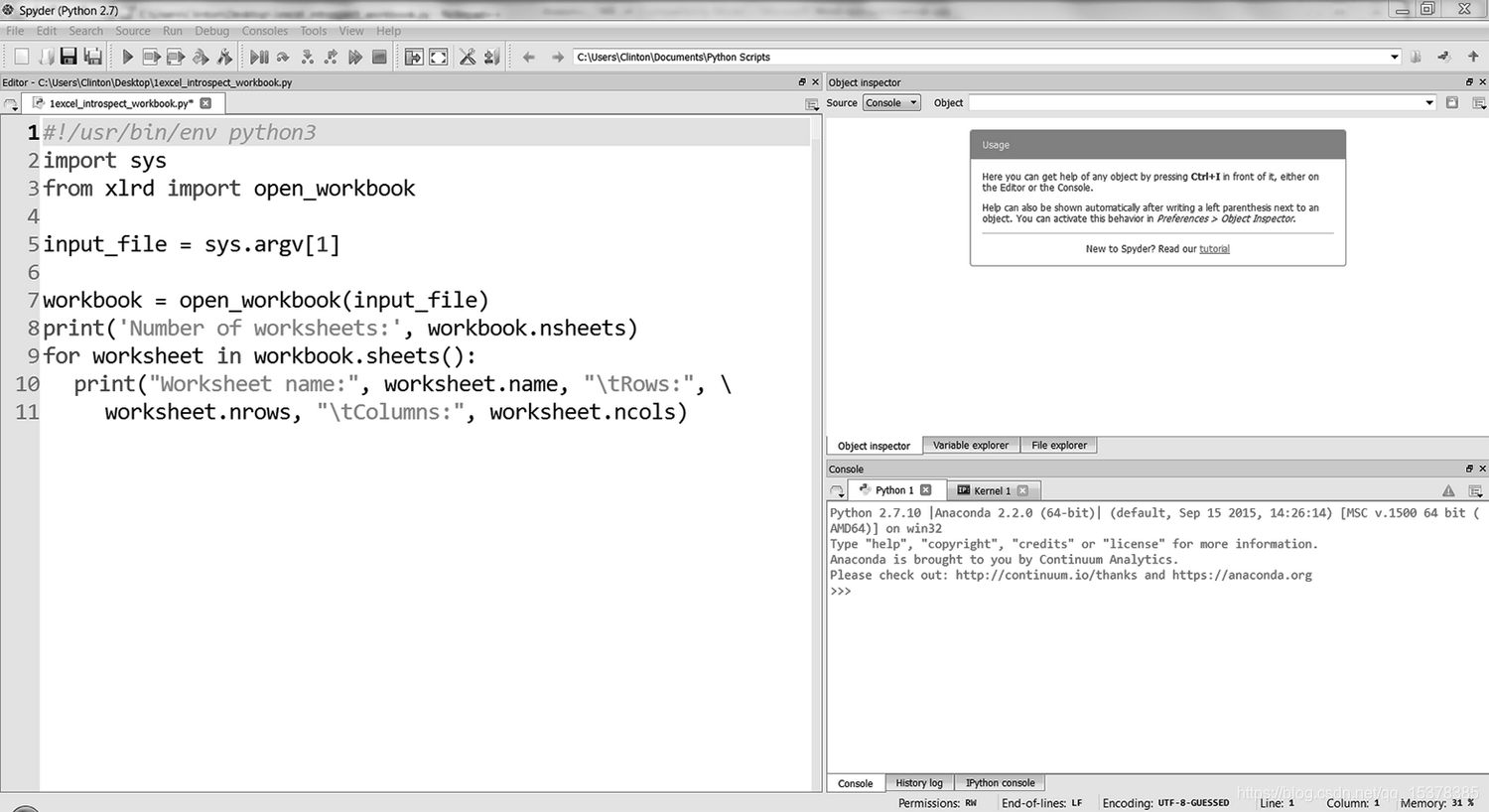
图 4:Anaconda Spyder 中的 Python 脚本 excel_introspect_workbook.py

图 5:Notepad++(Windows)中的 Python 脚本 excel_introspect_workbook.py
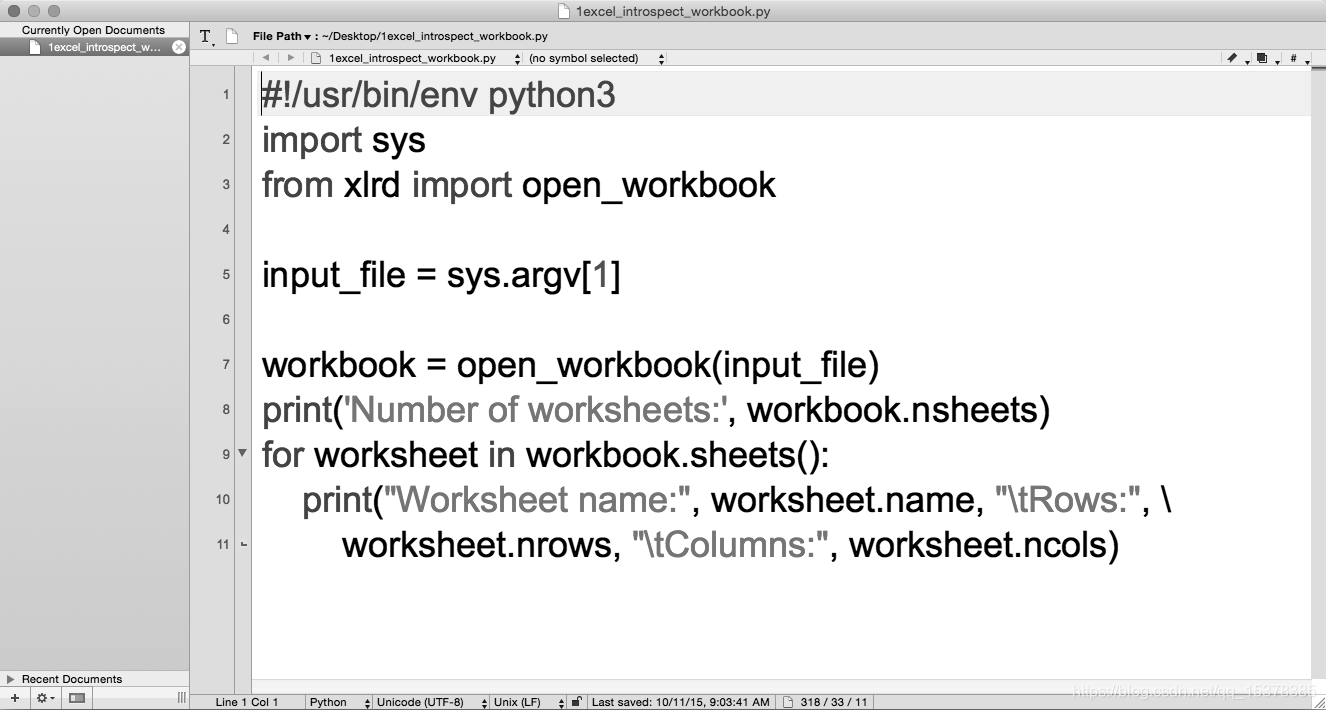
图 6:TextWrangler(macOS)中的 Python 脚本 excel_introspect_workbook.py
第 3 行代码导入 xlrd 模块的 open_workbook 函数来读取和分析 Excel 文件。
第 7 行代码使用 open_workbook 函数打开一个 Excel 输入文件,并赋给一个名为 workbook 的对象。workbook 对象中包含了工作簿中所有可用的信息,所以可以使用这个对象从工作簿中得到单独的工作表。
第 8 行代码打印出工作簿中工作表的数量。
第 9 行代码是一个 for 循环语句,在工作簿中的所有工作表之间迭代。workbook 对象的 sheets 方法可以识别出工作簿中所有的工作表。
第 10 行代码在屏幕上打印出每个工作表的名称和每个工作表中行与列的数量。print 语句使用 worksheet 对象的 name 属性来确定每个工作表的名称。同样,它使用 nrows 和 ncols 属性来分别确定每个工作表中行与列的数量。
如果你在 Spyder IDE 中创建了这个文件,按下列步骤运行脚本。
(1) 在 IDE 左上角点击 Run 下拉菜单。
(2) 选择“Configure”。
(3) 当 Run Settings 窗口打开后,选择“Command line options”复选框,然后输入“sales_2013.xlsx”(参见图 3-7)。
(4) 确定“Working directory”是你保存脚本和 Excel 文件的目录。
(5) 点击 Run。
当点击了 Run 按钮(或者是 Run Settings 窗口中的 Run 按钮,或者是 IDE 左上角绿色的 Run 按钮)之后,你会看到输出显示在 IDE 右下角的 Python 控制台窗格上。图 7 显示了 Run 下拉菜单、Run Setting 窗口中的关键设置和红框内的输出。

图 7:在 Anaconda Spyder 中设置命令行参数
当然,你可以在命令行窗口或终端窗口中运行脚本。要完成这个操作,根据不同的操作系统,使用如下命令。
Windows 操作系统
python 1excel_introspect_workbook.py sales_2013.xlsx
macOS 操作系统
chmod +x 1excel_introspect_workbook.py
./1excel_introspect_workbook.py sales_2013.xlsx
你可以看到输出被打印到屏幕上,如图 8(Windows)或图 9(macOS)所示。
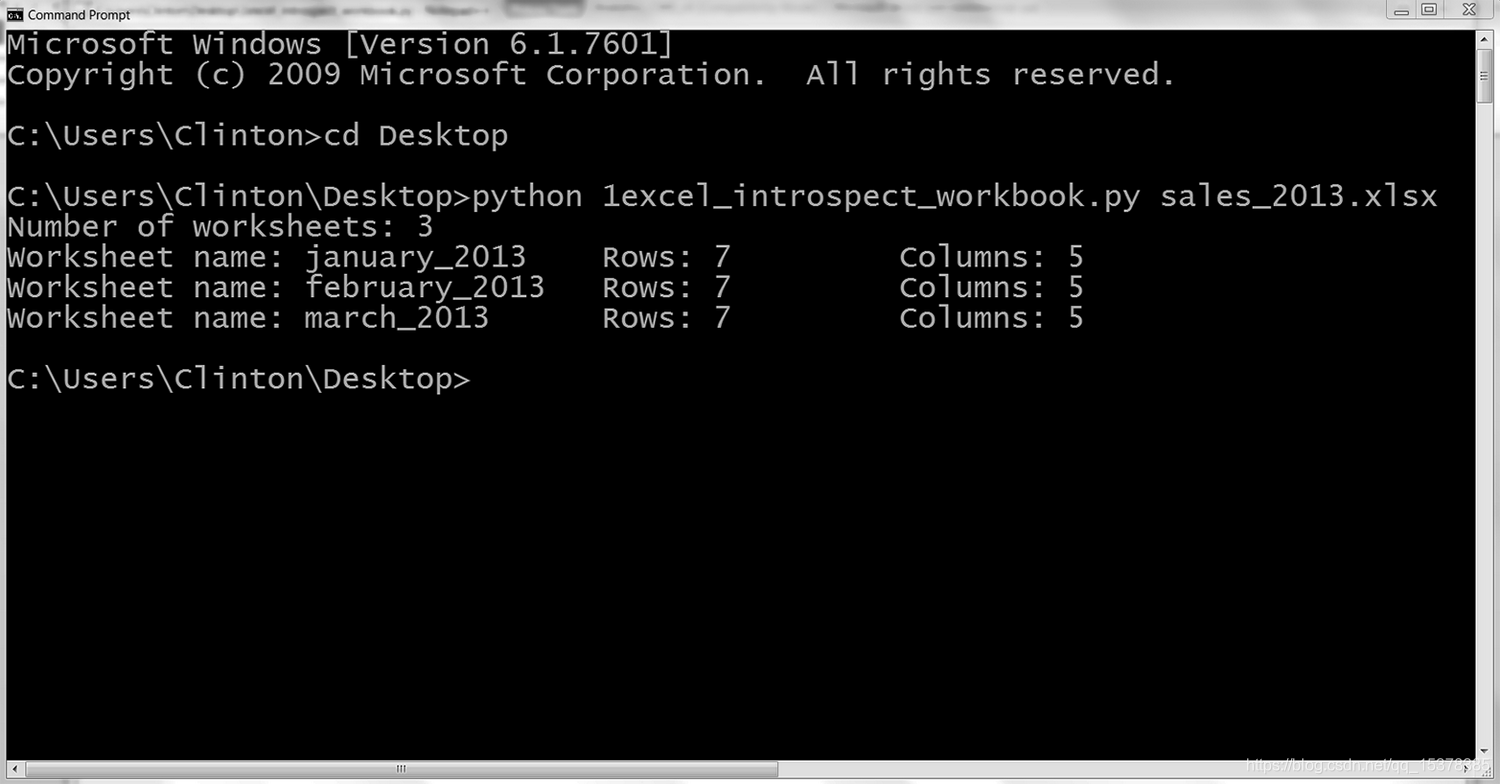
图 3-8:命令行窗口(Windows)中的 Python 脚本输出
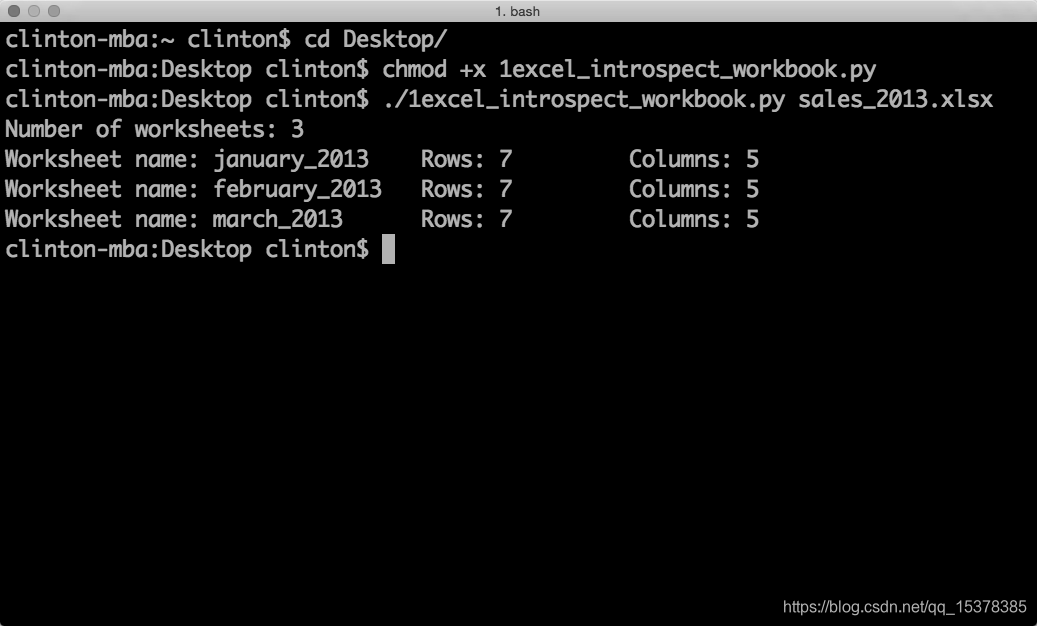
图 9:终端窗口(macOS)中的 Python 脚本输出
第一行输出表示 Excel 输入文件 sale 2013.xlsx 中包含 3 个工作表。下面三行说明了 3 个工作表分别名为 january_2013、february_2013 和 march_2013。它们还说明了每个工作表中包含 7 行(包括标题行)和 5 列。
掌握了如何使用 Python 来内省 Excel 工作簿之后,就可以开始学习如何以不同的方法来解析单个工作表了。
















 521
521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









