










无监督机器学习
何用无监督学习技术来识别数据集中的模式和结构。
无监督学习是用于探索性分析的一系列很有价值的技术。它们能够挖掘出隐藏在数据集中的模式和结构,获取有用的信息或为进一步分析提供指导。拥有一套可靠的无监督学习工具集至关重要,你可以应用它们将陌生或复杂的数据集分解为可用信息。
我们将先从主成分分析(principal component analysis,PCA)这个基本的数据操作技术开始,并结合一系列的降维应用。接着探讨一项应用广泛且简单易用的无监督学习技术——k均值聚类。随后会讨论一种能将复杂数据集映射到二维的拓扑聚类方法——Kohenen提出的自组织映射(self-organizing map,SOM)。
会用一些篇幅来探讨如何有效应用这些技术将高维数据集整合为易于处理的形式。我们将使用UCI手写数字数据集来展示每种算法的技术应用。在探讨和应用每种技术的过程中,我们将回顾一些实际应用和方法论的问题,尤其是如何校准和验证每种技术,以及哪些性能评测方法是有效的。综上,我们将按顺序讨论以下主题:
- 主成分分析
- k均值聚类
- 自组织映射
主成分分析
为了有效处理高维数据集,我们必须有一套技术能将维度降至可处理的水平。降维的优势包括:可以在二维空间中对多维数据进行可视化、用最少的特征描述数据集所包含的信息,以及在某些情况下识别模型向量的共线性。
在机器学习的背景下,所谓的共线性是指模型特征共有的接近线性的关系。这些特征一般用处不大,原因很明显,相关特征不大可能比它们独立时提供更多的信息量。而且,共线特征可能会突出局部极小值或给出其他错误的线索。
当今应用最广泛的降维技术可能就是主成分分析了。将在多处使用主成分分析,因此最好先回顾一下该技术、理解其背后的理论,并编写能够有效应用主成分分析的Python代码。
主成分分析入门
主成分分析是一种强大的分解方法,它能够将变量极多的数据集分解为一系列正交向量。取足够多的正交向量,就能够解释数据集中近乎全部的方差了。从本质上来说,集合中的这些正交向量就是数据集的精简版描述。主成分分析用途广泛,很值得我们花时间学习。
这里稍微提醒一下,当分解后的向量维度小于原始数据集的变量个数时,往往会损失一些原始数据集中的信息。若向量数目足够多,这种损失通常很小,但如果将变量极多的数据集分解成很少的向量,那么就会损失“惨重”。因此,在应用主成分分析时,必须考虑对数据集有效建模所需要的向量数目。
主成分分析通过逐一辨别数据集中方差最大的方向(主成分)来提取向量,步骤如下所示:
(1) 找出数据集的中心点;
(2) 计算数据的协方差矩阵;
(3) 计算协方差矩阵的特征向量;
(4) 将特征向量标准正交化;
(5) 计算每个特征向量表示的方差比例。
我们来简要介绍一下这些概念。
- 协方差:
多维数据的方差,两个或多个变量之间的方差。一维或一个变量的方差可由一个值来描述,两个变量之间的方差需要用一个2×2的矩阵来描述,三个变量之间的方差需要用一个3×3的矩阵来描述,以此类推。因此,主成分分析的第一步就是计算协方差矩阵。
- 特征向量:
一种针对数据集或线性变换的向量。具体来说,这种向量的方向在转换前后不会发生变化。为便于理解,假设你的两手之间有一根直的橡皮筋,你伸展橡皮筋,直到它绷紧为止。特征向量正是伸展前和伸展过程中不会发生方向变化的向量,也就是本例中直接穿过橡皮筋中心从一只手到另一只手的向量。
- 正交化:
寻找两个相互正交(成直角)的向量的过程。在n维数据空间中,正交化的过程就是选取一系列向量,然后转化为一系列正交向量。
- 标准正交化:
对积进行标准化的正交化过程。
- 特征值:
(大致相当于特征向量的长度)用于计算由每个特征向量表示的方差比例,该比例由每个特征向量的特征值除以所有特征向量的特征值之和得到。
总的来说,协方差矩阵用于计算特征向量,标准正交过程则是根据特征向量得出正交的、标准化向量。特征值最大的特征向量是第一个主成分,其他成分的特征值都相对较小。这样一来,主成分分析算法就能够将数据集转化为用新的低维坐标系来表示。
应用主成分分析
概略地回顾了主成分分析算法后,接下来我们将其应用于一个重要的Python数据集,即UCI手写数字数据集(digits),它是作为scikit-learn的一部分发布的。
该数据集包含了来自44位作者的1797个手写数字。对这些作者的手写数字的笔压和位置信息使用8×8的点阵,经过两次重复采样后,得到了图1-1中的映射。
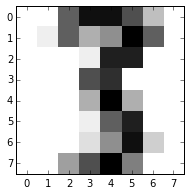
图 1-1
这些映射可以转化为维度为64的特征向量,从而作为分析输入项。对于含有64个特征的输入数据集,我们往往会立即想到使用诸如主成分分析的技术,从而将变量减少到可处理的数量。目前来看,我们无法用可视化探索来有效地分析数据集。
先对digits数据集应用主成分分析技术,代码如下所示:
i
mport numpy as np
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import scale
from sklearn.lda import LDA
import matplotlib.cm as cm
digits = load_digits()
data = digits.data
n_samples, n_features = data.shape
n_digits = len(np.unique(digits.target))
labels = digits.target
这段代码完成了以下工作。
首先,它加载了一系列必要的库,包括numpy库、scikit-learn库和用于绘图的matplotlib库。其中scikit-learn库主要包括digits数据集、主成分分析算法和数据标准化函数等一系列相关数据、算法和函数。
接着,开始准备digits数据集。步骤如下所示。
首先,在构造有用的变量前加载数据集。
创建data变量用于表示数据集,并根据digits数据集中的目标向量计算出因变量的类别数(因为数字取值范围为0~9,所以n_digits = 10)并存为变量,以供后续分析使用。
将target向量存为变量,并命名为labels,以便后续使用。
以上变量构造均是为了简化后续分析。
准备好数据集后,对主成分分析算法进行初始化并将其应用于数据集。
pca = PCA(n_components=10)
data_r = pca.fit(data).transform(data)
print('explained variance ratio (first two components): %s' %
str(pca.explained_variance_ratio_))
print('sum of explained variance (first two components): %s' %
str(sum(pca.explained_variance_ratio_)))
以上代码会输出由前10个主成分解释的方差,按解释能力由高到低排序。
本例中的10个主成分共同解释了0.589的总方差。这结果不算太差,毕竟我们将64个变量减少到10个主成分,但也的的确确反映出了主成分分析带来的潜在损失。然而,关键问题是,精简后的变量集能否便于后续的分析或分类,也就是说,降维向量保留的方差信息是否会影响分类预测效果。
用pca处理digits数据集,并将输出结果保存到新变量data_r中后,可以对输出进行可视化。为此,首先需要构建colors向量来给类上色,然后便可以绘制散点图:
X = np.arange(10)
ys = [i+x+(i*x)**2 for i in range(10)]
plt.figure()
colors = cm.rainbow(np.linspace(0, 1, len(ys)))
for c, i target_name in zip(colors, [1,2,3,4,5,6,7,8,9,10], labels):
plt.scatter(data_r[labels == I, 0], data_r[labels == I, 1],
c=c, alpha = 0.4)
plt.legend()
plt.title('Scatterplot of Points plotted in first \n'
'10 Principal Components')
plt.show()
得到的散点图如图1-2所示。
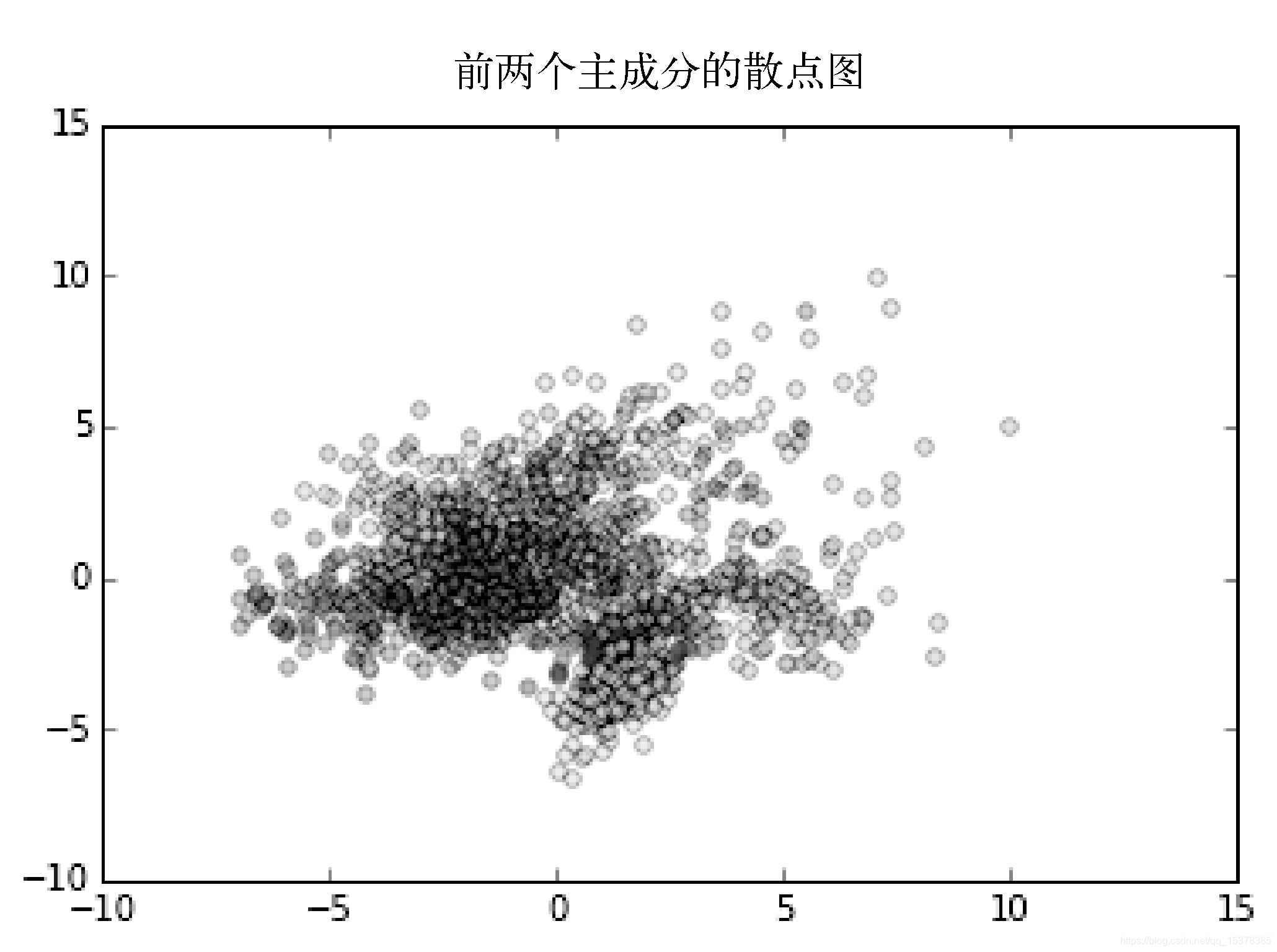
图 1-2
这幅图告诉我们,虽然前两个主成分之间有一些间隔,但很难用本数据集来高度精确地区分。然而,很多类的内部的确出现了一些聚合现象,我们可以通过聚类分析获取一些有用信息。照此方法,我们可以利用主成分分析初步了解数据集的结构,然后再进一步分析。
接下来,应用k均值聚类算法来继续探索聚类结果。
推荐参考学习书籍:Python高级机器学习



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









