






监控指标介绍
服务器监控
CPU状态:cpu使用率、负载
内存状态:应用内存使用率、物理内存使用量
磁盘状态:分区大小、使用趋势
IO状态:IOPS、MBPS、每秒读写速率、await
网卡状态:网络出入流量Bps、pps、丢包率、TCP状态、网络连接
数据库监控:
慢sql
异常死锁
Druid连接池 等待线程数
案例介绍
应用内存飚高
案例1:通过数据库一次查询量太大(伴随慢sql), 一次加载到应用内存处理。
修复:数据库分页查询处理,增加limit
案例2:部署应用后观测到应用内存持续上涨,是否有风险
Java进程占用内存后,即使GC回收了,也不会立即降低,这是因为Java虚拟机的内存管理机制。
Java虚拟机采用的是分代垃圾回收策略,将内存分为年轻代和老年代。年轻代又分为Eden区和两个Survivor区S0、S1。
当Java程序运行时,对象会被分配在Eden区中。当Eden区满时,会触发一次MinorGC,将不再使用的对象回收掉,然后存活下来的对象会被移动到Survivor区S0中。
等Eden区再满了,就再触发一次Minor GC,Eden和S0中的存活对象又会被复制送入第二块survivor space S1(这个过程非常重要,因为这种复制算法保证了S1中来自S0和Eden两部分的存活对象占用连续的内存空间,避免了碎片化的发生,碎片化带来的风险是极大的,严重影响JAVA程序的性能)。S0和Eden被清空,然后下一轮S0与S1交换角色,如此循环往复。如果对象的复制次数达到16次,该对象就会被送到老年代中。
在这个过程中,如果某个对象在年轻代中存活的时间很长,就会被移动到老年代中。而老年代中的对象只有在Full GC时才会被回收。
因此,如果Java进程中的对象大部分都在老年代中,那么即使进行了多次Minor GC,也不会释放掉这些对象占用的内存,只有进行Full GC时才能释放。
如果 Full GC 的频率过高,就可能会导致系统性能下降,因为它会占用大量的 CPU 时间和内存资源。因此,需要对 Full GC 的频率进行监控和调优,以保证系统的正常运行。
频繁的full gc可能是由于以下原因导致的:
- 内存泄漏:如果应用程序存在内存泄漏,那么就会导致内存中的对象无法被垃圾回收器清理,最终导致内存溢出,触发full gc。
- 对象生命周期过长:如果应用程序中的对象生命周期过长,那么就会导致这些对象长时间占用内存,最终导致内存溢出,触发full gc。
- 堆内存设置不合理:如果堆内存设置过小,那么就会导致内存不足,触发full gc。如果堆内存设置过大,那么就会导致full gc的频率增加,因为垃圾回收器需要更长的时间来扫描整个堆内存。
- 大对象:如果应用程序中存在大对象,那么就会导致内存中的碎片增加,最终导致内存不足,触发full gc。
- 过多的对象创建:如果应用程序中频繁地创建对象,那么就会导致内存中的对象数量增加,最终导致内存不足,触发full gc。
JVM调优:
Java虚拟机中有Xmx和Xms参数, 分别用于设置Java虚拟机(JVM)的最大堆内存和初始堆内存大小(启动时分配的最小内存)。
-Xmx参数用于设置JVM的最大堆内存大小,格式为-Xmx[g|G|m|M|k|K],其中表示最大堆内存大小,单位可以是GB、MB或KB。
-Xms参数用于设置JVM的初始堆内存大小,格式为-Xms[g|G|m|M|k|K],其中表示初始堆内存大小,单位可以是GB、MB或KB。
通常情况下,Xmx和Xms参数应该设置为相同的值,以避免JVM在运行时不断地调整堆内存大小,从而影响应用程序的性能。同时,应该根据应用程序的内存需求和可用系统资源来合理地设置这两个参数。如果程序一直运行,那么Java进程的内存占用量会逐渐增加,但不会低于-Xms参数指定的值。因此,如果程序需要占用大量内存,可以适当增加-Xms参数的值,这样可以避免频繁的内存分配和回收,提高程序的性能。
案例3:应用日志存在了系统内存中,看到应用内存偏高
// 查看used内存
# free -g
total used free shared buff/cache available
Mem: 16 13 2 0 1 2
// 查看java应用的最大堆内存
# ps -ef |grep java |grep Xmx
... -Xmx8192m ...
// 查看相差了5G,最终发现有日志生成在run目录下
# df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 16G 5G 11G 45% /run
tmpfs是一种基于内存的文件系统,它将一部分系统内存作为文件系统的存储空间,可以用来存储临时文件和缓存数据等。
在Linux系统中,tmpfs默认挂载在/run目录下,因此如果应用程序在/run目录下生成了大量的日志文件,那么这些文件的大小就会被计算在tmpfs的使用量中。
由于tmpfs是基于内存的文件系统,因此它的使用量也会被计算在系统的内存使用量中,从而导致应用程序的内存使用率看起来比实际情况要高。
修改方案:
1,修改日志路径
2,限制日志大小:如以下是常见的/etc/systemd/journald.conf配置选项及其示例说明:
将journal日志文件存储在特定目录下:
Storage=auto
SystemMaxUse=50M
SystemKeepFree=100M
SystemMaxFileSize=10M
这个示例将journal日志文件存储在默认的/var/log/journal目录下,并限制了系统磁盘上journal文件占用空间不超过50MB,至少保留100MB的可用空间。同时还限制单个journal文件大小不超过10MB。
cpu飚高
案例1:parallelStream导致cpu飙升
修复:使用字典树代替parallelStream,通过线程池进行管理
另外,可以在方法上增加 @Transactional(propagation = Propagation.NOT_SUPPORTED) 作用是将当前方法设置为不支持事务,即当前方法不会参与到任何事务中,这种设置通常用于一些只读操作或者不需要事务支持的操作。例如在查询操作中,如果使用事务会占用更多的系统资源,而且可能会导致锁定表或行,影响系统的并发性能。因此,将查询操作设置为不支持事务可以提高系统的并发性能和响应速度。
5xx报错
案例1:升级JDK17不同操作系统 SecureRandom 引发的线程阻塞
问题现象:
java -jar 启动jar包,tomcat启动过慢出现假死现象,表现为程序长时间无法向下运行。
问题根因:
Linux主机默写操作系统熵值不足导致线程阻塞问题。
在某些情况下,升级到JDK 17后,使用SecureRandom可能会遇到线程阻塞的问题。这是因为JDK 17中对SecureRandom的实现做了改变,默认使用了更为强大的算法,可能会导致在某些特定的操作系统或硬件配置上性能下降,进而影响到应用程序的性能。
jre的安全随机数会使用linux的随机数生成器(在linux上实际上使用的是/dev/random或者/dev/urandom)来生成安全随机数,即提供永不为空的随机字节数据流。默认会使用阻塞算法获取随机数,如果熵值不够则会导致长时间无法获取随机数,导致线程阻塞。
可以通过cat /proc/sys/kernel/random/entropy_avail查看当前熵池大小
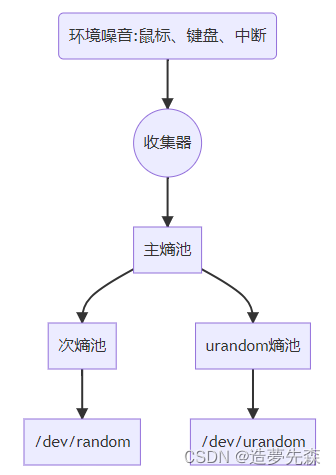
参考:https://blog.csdn.net/Numb_ZL/article/details/127272004
解决方案:
需要开启haveged服务:haveged服务提供了一个易用的、不可预测的随机数生成器,生成的随机数用于补充系统熵池,可解决某些情况下系统熵过低的问题,以提高系统性能。 如果haveged服务没有开启,需要完全依赖操作系统生成强伪随机数的进程从/dev/random取值时,会因为取不到足够的值而陷入等待,直至取到新的随机字节后才返回。
1 检查haveged状态:service haveged status
2 启动haveged:service haveged start
3 自启动配置:systemctl enable haveged.service
案例2:网络丢包偶然导致socket一直无法结束,应用druid连接数据库无法自愈。
问题根因:
在网络不稳定或者网络延迟较高的情况下,如果不设置超时时间,可能会导致请求长时间挂起(表现为druid创建数据库连接线程一直阻塞在socketRead),进一步可能引起程序崩溃或者数据丢失。
解决方法:
- 设置连接超时时间(connectTimeout):这是指在尝试连接时等待连接的最长时间。
- 设置socket读取超时时间(socketTimeout):这是指从socket读取数据时的超时时间。
spring.datasource.url=jdbc:mysql://localhost:3306/mydatabase?connectTimeout=60000&socketTimeout=60000
小技巧:可以使用tc命令中的"netem"模块来设置端口丢包率。以下是一个示例命令:
// 在eth0端口上添加一个队列规则,使用netem模块来模拟10%的丢包率
sudo tc qdisc add dev eth0 root netem loss 10%
Spring Boot 高并发解决方案通常涉及以下几个方面:
代码优化:减少在请求处理中的计算和数据库操作。
服务器配置优化:提高服务器资源,如增加CPU核心数、增加内存容量、优化文件描述符限制等。
使用缓存:合理使用缓存可以减少对数据库的访问。
异步处理:对于耗时的操作,可以使用异步处理来避免阻塞请求处理。
负载均衡:通过负载均衡可以分散请求到不同的服务器实例上。
限流和熔断:有效控制并发量,防止系统被超载,并在服务不可用时进行自我保护。常见的限流场景:
(1)线程池管理,控制任务处理的线程数
(2)对单数据库同时处理的任务量进行限制
(3)根据任务负载,对单机处理的任务数、并发的大任务数、整个集群负载最高的一批任务进行限制
(4)接口调用频率根据用户token进行限流
SSL证书文件校验工具:https://www.chinassl.net/ssltools/decoder-ssl.html
YAML、YML在线编辑(校验)器:https://www.bejson.com/validators/yaml_editor/
URL在线编码解码工具:http://www.jsons.cn/urlencode/















 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









