









- 数组字符串专题
- Map存储、遍历、并利用Comparator实现自定义排序(Map按值排序)
- 排序算法
- 字符串匹配算法
- 二分查找及变形题
- 全排列
- 递归和循环:斐波那契数列、跳台阶、矩形覆盖
- 求最长公共子串和最长公共子序列
- 求最长回文子串
- 字符串反转、句子逆序(StringBuffer/StringBuilder)
- 字符串转换成整数String to Interger
- 字符串替换空格
- 找出数组中只出现一次的数字
- 找出数组中出现次数超过一半的数字
- 找出旋转数组中的最小数字
- 计算二进制数中1的个数
- 计算数值的整数次方
- 链表反转
- 合并两个链表
- 链表中倒数第k个结点
- 链表从尾到头打印
- 用两个栈实现队列
- 判断栈的弹出序列
编程题
数组字符串专题
//整形数组的定义:
1、int[] arr=new int[5];
2、int[] arr=new int[]{0,1};
3、int[] arr={0,1};
str.charAt(0)=='A' //char型用 "==",单引号
str.equals("A")//string型用 "equals",双引号
str.charAt(i)-'0' //将某个char字符转换为int型
String.valueOf(Integer) //Integer to String
String.valueOf(Character) //Character to String
Integer.parseInt(String);//String to Integer
Integer.parseInt(str,16) //16进制数输出为10进制数
str.toCharArray(); //将字符串String转换为char数组
str.substring(1).matches("[0-9]+") //判断str子字符串从指定索引处的字符到字符串末尾,都为数字。
注:subString(2,9);// 截取下标为2到8位置的字符串,不包含后者!!!
//例:不能有相同长度超2的子串重复
for(int i=0;i<str.length()-2;i++){
if(str.substring(i+1).contains(str.substring(i,i+3))){
return false;
}
indexOf(str) //返回第一次出现的指定子字符串在此字符串中的索引。 例:在扑克牌中比较大小的应用:
public int count(String str) {
return "345678910JQKA2jokerJOKER".indexOf(str);
}
//遍历TreeSet:
for(Integer i:set){
System.out.prinltn(i);
}
//遍历HashMap:
for (Integer key : map.keySet()) {
System.out.println(key + " " + map.get(key));
}按值排序
Map存储、遍历,并利用Comparator实现自定义排序 (Map按值排序)
public int compare(Node n1, Node n2), 返回一个基本类型的整型
如果要按照升序排序,则n1 小于n2,返回-1(负数),相等返回0,n1大于n2返回1(正数)
如果要按照降序排序,则n1 小于n2,返回1(正数),相等返回0,n1大于n2返回-1(负数)
import java.util.*;
class Node{
int i; // 存储顺序
char key;
int value;
public Node(int i, char key, int value) {
this.i = i;
this.key = key;
this.value = value;
}
}
public class Main{
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
List<Node> list=new ArrayList<Node>();
String str=sc.nextLine();
Map<Character,Integer> map=new TreeMap<Character,Integer>();
//Map存储
for(int i=0;i<str.length();i++){
if(map.containsKey(str.charAt(i))){
map.put(str.charAt(i), map.get(str.charAt(i))+1);
}else
map.put(str.charAt(i), 1);
}
int i=0;
//Map遍历
for(char key:map.keySet()){
list.add(new Node(i,key,map.get(key)));
i++;
}
//利用Comparator按值排序
Collections.sort(list,new Comparator<Node>(){
public int compare(Node n1, Node n2) {
if (n1.value<n2.value) return 1;
else if(n1.value==n2.value) return 0;
else return -1;
}
});
for (int j = 0; j < list.size(); j++) {
System.out.println(list.get(j).key+" "+list.get(j).value);
}
}
}}
排序专题
排序大的分类可以分为两种:内排序和外排序。在排序过程中,全部记录存放在内存,则称为内排序,如果排序过程中需要使用外存,则称为外排序。下面讲的排序都是属于内排序。
内排序有可以分为以下几类:
(1)、插入排序:直接插入排序、二分法插入排序、希尔排序。
(2)、选择排序:简单选择排序、堆排序。
(3)、交换排序:冒泡排序、快速排序。
(4)、归并排序
(5)、基数排序
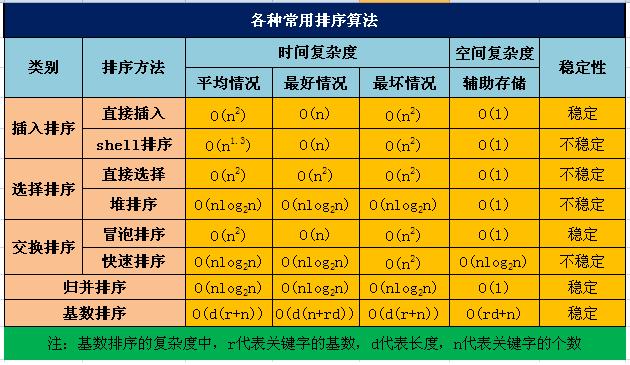
时间复杂度为O(n2)的排序算法:冒泡,选择,插入
时间复杂度为O(nlogn)的排序算法:归并,快排,堆排,希尔排序
时间复杂度为O(n)的排序算法:基数排序,计数排序
稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序。
冒泡排序
1、基本思想:在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒。即:每当两相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。
2、实例

3、java实现

4、分析
冒泡排序是一种稳定的排序方法。
•若文件初状为正序,则一趟起泡就可完成排序,排序码的比较次数为n-1,且没有记录移动,时间复杂度是O(n)
•若文件初态为逆序,则需要n-1趟起泡,每趟进行n-i次排序码的比较,且每次比较都移动三次,比较和移动次数均达到最大值∶O(n2)
•起泡排序平均时间复杂度为O(n2)
快速排序:
1、基本思想:选择一个基准元素,通常选择第一个元素或者最后一个元素,通过一趟扫描,将待排序列分成两部分,一部分比基准元素小,一部分大于等于基准元素,此时基准元素在其排好序后的正确位置,然后再用同样的方法递归地排序划分的两部分。
2、实例

3、java实现

4、分析
快速排序是不稳定的排序。
快速排序的时间复杂度为O(nlogn)。
当n较大时使用快排比较好,当序列基本有序时用快排反而不好。
如何不用递归实现快排
(1)一次划分以后,left、mid-1、mid+1、right四个元素入栈。
(2)用栈保存每一个待排子序列的首尾元素,下一次while循环时取出这个范围,对这段子序列进行partition操作。
public void QuitSort(int[] arr,int l,int r){
Stack<Integer> st=new Stack<Integer>();
if(l<r){
int q=partition(A,l,r);
if(l<q-1) {
st.push(l);
st.push(q-1);
}
if(q+1<r) {
st.push(q+1);
st.push(l);
}
while(!st.isEmpty){
int right=st.peek; //获取栈顶元素
st.pop();
int left=st.peek;
st.pop();
q= partition(A,left,right);
if(left<q-1) {
st.push(left);
st.push(q-1);
}
if(q+1<right) {
st.push(q+1);
st.push(right);
}
}
}
}
快排的优化
如果数组已经部分有序时,固定位置的分割就是一个非常不好的分割。因为每次划分只能使已排序序列减少,最坏情况时间复杂度为O(n^2)。
(1)优化1:三数取中。
使用左端、右端和中心位置上的三个元素的中值作为枢纽元 ;
首先,它使得最坏情况发生的几率减小了。 其次,未改进的快速排序算法为了防止比较时数组越界,在最后要设置一个哨点。如果在分区排序时,中间的这个元素(也即中轴)是与最右边数过来第二个元素进行交换的话,那么就可以省略与这一哨点值的比较。
(2)优化2:当待排序序列的长度分割到一定大小后,使用插入排序。
原因:对于很小和部分有序的数组,快排不如插排好。当待排序序列的长度分割到一定大小后,继续分割的效率比插入排序要差,此时可以使用插排而不是快排
(3)优化3:一次分割结束后,可以把与Key相等的元素聚在一起,下次分割就不用再对key相等的元素分割。
概括:这里效率最好的快排组合 是:三数取中+插排+聚集相等元素,它和STL中的Sort函数效率差不多
简单选择排序
1、基本思想:在要排序的一组数中,选出最小的一个数与第一个位置的数交换;然后在剩下的数当中再找最小的与第二个位置的数交换,如此循环到倒数第二个数和最后一个数比较为止。
2、实例

3、java实现

4、分析
简单选择排序是不稳定的排序。
时间复杂度:T(n)=O(n2)。
堆排序
1、基本思想:
堆排序是一种树形选择排序,是对直接选择排序的有效改进。
堆的定义下:具有n个元素的序列 (h1,h2,…,hn),当且仅当满足(hi>=h2i,hi>=2i+1)或(hi<=h2i,hi<=2i+1) (i=1,2,…,n/2)时称之为堆。在这里只讨论满足前者条件的堆。由堆的定义可以看出,堆顶元素(即第一个元素)必为最大项(大顶堆)。完全二 叉树可以很直观地表示堆的结构。堆顶为根,其它为左子树、右子树。
思想:初始时把要排序的数的序列看作是一棵顺序存储的二叉树,调整它们的存储序,使之成为一个 堆,这时堆的根节点的数最大。然后将根节点与堆的最后一个节点交换。然后对前面(n-1)个数重新调整使之成为堆。依此类推,直到只有两个节点的堆,并对 它们作交换,最后得到有n个节点的有序序列。从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆的渗透函数,二是反复调用渗透函数实现排序的函数。
2、实例
初始序列:46,79,56,38,40,84
建堆:
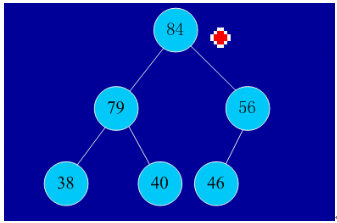
交换,从堆中踢出最大数

依次类推:最后堆中剩余的最后两个结点交换,踢出一个,排序完成。
3、java实现
堆排序:
(1)创建大根堆
(2)将堆顶元素与数组最后一个元素交换
(3)堆大小减1,继续调整大根堆,交换,重复以上步骤
public void heapSort(int[] data) {
for (int i = 0; i < data.length; i++) {
createMaxdHeap(data, data.length - 1 - i);
swap(data, 0, data.length - 1 - i);
}
}
public static void createMaxdHeap(int[] data, int lastIndex) {
for (int i = (lastIndex - 1) / 2; i >= 0; i--) { // 从最后一个父节点开始
int k = i;
while (2 * k + 1 <= lastIndex) {
int biggerIndex = 2 * k + 1; // biggerIndex记录较大节点的值,先赋值为当左子节点
if (biggerIndex < lastIndex) { // 若右子节点存在(否则应该相等)
if (data[biggerIndex] < data[biggerIndex + 1]) {
// 若右子节点值比左子节点值大,则biggerIndex记录的是右子节点的值
biggerIndex++;
}
}
if (data[k] < data[biggerIndex]) {
// 若当前节点值比子节点最大值小,则交换2者得值,交换后将biggerIndex值赋值给k
swap(data, k, biggerIndex);
k = biggerIndex;
} else {
break;
}
}
}
}
public static void swap(int[] data, int i, int j) {
if (i == j) {
return;
}
int tmp= data[i];
data[i] = data[j];
data[j] = tmp;
}
4、分析
堆排序也是一种不稳定的排序算法。
堆排序优于简单选择排序的原因:
直接选择排序中,为了从R[1..n]中选出关键字最小的记录,必须进行n-1次比较,然后在R[2..n]中选出关键字最小的记录,又需要做n-2次比较。事实上,后面的n-2次比较中,有许多比较可能在前面的n-1次比较中已经做过,但由于前一趟排序时未保留这些比较结果,所以后一趟排序时又重复执行了这些比较操作。
堆排序可通过树形结构保存部分比较结果,可减少比较次数。
堆排序的最坏时间复杂度为O(nlogn)。堆序的平均性能较接近于最坏性能。由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。
直接插入排序
1、基本思想:每步将一个待排序的记录,按其顺序码大小插入到前面已经排序的字序列的合适位置(从后向前找到合适位置后),直到全部插入排序完为止。
2、实例
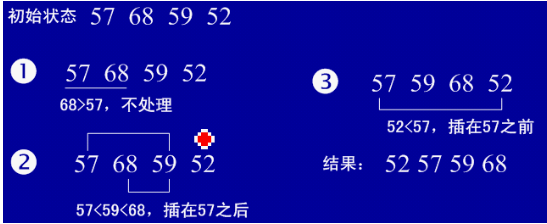
3、java实现

4、分析
直接插入排序是稳定的排序。关于各种算法的稳定性分析可以参考http://www.cnblogs.com/Braveliu/archive/2013/01/15/2861201.html
文件初态不同时,直接插入排序所耗费的时间有很大差异。若文件初态为正序,则每个待插入的记录只需要比较一次就能够找到合适的位置插入,故算法的时间复杂度为O(n),这时最好的情况。若初态为反序,则第i个待插入记录需要比较i+1次才能找到合适位置插入,故时间复杂度为O(n2),这时最坏的情况。
直接插入排序的平均时间复杂度为O(n2)。
二分法插入排序(按二分法找到合适位置插入)
1、基本思想:二分法插入排序的思想和直接插入一样,只是找合适的插入位置的方式不同,这里是按二分法找到合适的位置,可以减少比较的次数。
2、实例
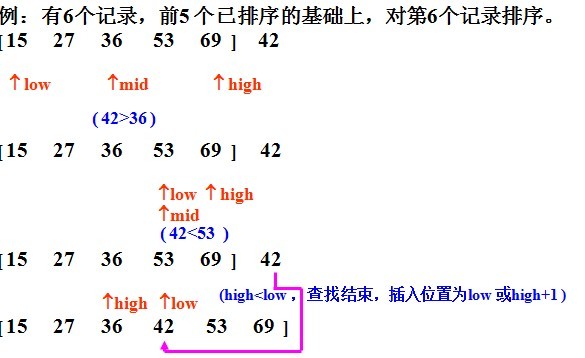
3、java实现

4、分析
当然,二分法插入排序也是稳定的。
二分插入排序的比较次数与待排序记录的初始状态无关,仅依赖于记录的个数。当n较大时,比直接插入排序的最大比较次数少得多,但大于直接插入排序的最小比较次数。算法的移动次数与直接插入排序算法的相同,最坏的情况为n2/2,最好的情况为n,平均移动次数为O(n2)。
希尔排序
1、基本思想:先取一个小于n的整数d1作为第一个增量,所有距离为d1的倍数的记录进行直接插入排序;然后,取第二个增量d2< d1重复上述的分组和排序,直至所取的增量dt=1 (dt< dt-l< …< d2< d1),即所有记录放在同一组中进行直接插入排序为止。该方法实质上是一种分组插入方法。
2、实例

3、java实现

4、分析
我们知道一次插入排序是稳定的,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以希尔排序是不稳定的。
希尔排序的时间性能优于直接插入排序,原因如下:
(1)当文件初态基本有序时直接插入排序所需的比较和移动次数均较少。
(2)当n值较小时,n和n2的差别也较小,即直接插入排序的最好时间复杂度O(n)和最坏时间复杂度0(n2)差别不大。
(3)在希尔排序开始时增量较大,分组较多,每组的记录数目少,故各组内直接插入较快,后来增量di逐渐缩小,分组数逐渐减少,而各组的记录数目逐渐增多,但由于已经按di-1作为距离排过序,使文件较接近于有序状态,所以新的一趟排序过程也较快。
因此,希尔排序在效率上较直接插人排序有较大的改进。
希尔排序的平均时间复杂度为O(nlogn)。
归并排序
1、基本思想:归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
2、实例

3、java实现

4、分析
归并排序是稳定的排序方法。
归并排序的时间复杂度为O(nlogn)。
速度仅次于快速排序,为稳定排序算法,一般用于对总体无序,但是各子项相对有序的数列。
基数排序
1、基本思想:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
2、实例
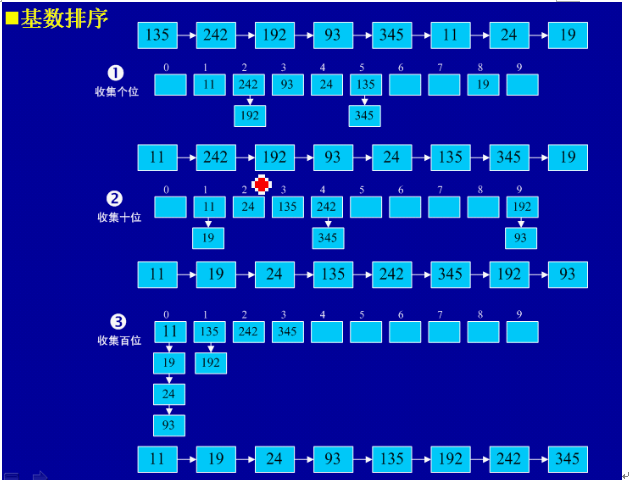
3、java实现
package com.sort;
2
3 import java.util.ArrayList;
4 import java.util.List;
5 //稳定
6 public class 基数排序 {
7 public static void main(String[] args) {
8 int[] a={49,38,65,97,176,213,227,49,78,34,12,164,11,18,1};
9 System.out.println("排序之前:");
10 for (int i = 0; i < a.length; i++) {
11 System.out.print(a[i]+" ");
12 }
13 //基数排序
14 sort(a);
15 System.out.println();
16 System.out.println("排序之后:");
17 for (int i = 0; i < a.length; i++) {
18 System.out.print(a[i]+" ");
19 }
20 }
21
22 private static void sort(int[] array) {
23 //找到最大数,确定要排序几趟
24 int max = 0;
25 for (int i = 0; i < array.length; i++) {
26 if(max<array[i]){
27 max = array[i];
28 }
29 }
30 //判断位数
31 int times = 0;
32 while(max>0){
33 max = max/10;
34 times++;
35 }
36 //建立十个队列
37 List<ArrayList> queue = new ArrayList<ArrayList>();
38 for (int i = 0; i < 10; i++) {
39 ArrayList queue1 = new ArrayList();
40 queue.add(queue1);
41 }
42 //进行times次分配和收集
43 for (int i = 0; i < times; i++) {
44 //分配
45 for (int j = 0; j < array.length; j++) {
46 int x = array[j]%(int)Math.pow(10, i+1)/(int)Math.pow(10, i);
47 ArrayList queue2 = queue.get(x);
48 queue2.add(array[j]);
49 queue.set(x,queue2);
50 }
51 //收集
52 int count = 0;
53 for (int j = 0; j < 10; j++) {
54 while(queue.get(j).size()>0){
55 ArrayList<Integer> queue3 = queue.get(j);
56 array[count] = queue3.get(0);
57 queue3.remove(0);
58 count++;
59 }
60 }
61 }
62 }
63 }4、分析
基数排序是稳定的排序算法。
基数排序的时间复杂度为O(d(n+r)),d为位数,r为基数。
总结
一、稳定性:
稳定:冒泡排序、插入排序、归并排序和基数排序
不稳定:选择排序、快速排序、希尔排序、堆排序
二、平均时间复杂度
O(n^2):冒泡排序,简单选择排序,直接插入排序。
在数据规模较小时(9W内),直接插入排序,简单选择排序差不多。当数据较大时,冒泡排序算法的时间代价最高。性能为O(n^2)的算法基本上是相邻元素进行比较,基本上都是稳定的。
O(nlogn):快速排序,归并排序,希尔排序,堆排序。
O(n):基数排序,计数排序。
三、排序算法的选择
1.数据规模较小
(1)待排序列基本序的情况下,可以选择直接插入排序;
(2)对稳定性不作要求宜用简单选择排序,对稳定性有要求宜用插入或冒泡
2.数据规模不是很大
(1)完全可以用内存空间,序列杂乱无序,对稳定性没有要求,快速排序,此时要付出log(N)的额外空间。
(2)序列本身可能有序,对稳定性有要求,空间允许下,宜用归并排序
3.数据规模很大
(1)对稳定性有求,则可考虑归并排序。
(2)对稳定性没要求,宜用堆排序
4.序列初始基本有序(正序),宜用直接插入,冒泡
字符串匹配算法
方法一: BF或暴力搜索 算法。时间复杂度O(MN)
public int strStr(String str11, String str22) {
String str1=str11; //str1用来保存长字符串
String str2=str22;
if(str11.length()<str22.length()){
str1=str22;
str2=str11;
}
int i=0;
int j=0;
for (; i < str1.length() && j < str2.length();) {
if (str1.charAt(i) == str2.charAt(j)) {
i++;j++;
} else {
i = i-j + 1; j = 0;
}
}
if( j == str2.length()) return i - j;
else return -1;
}
方法二: KMP算法 时间复杂度O(M+N)
KMP算法对于朴素匹配算法的改进是引入了一个跳转表next[],利用模式串自身的特点,尽可能多的移动模式串。
所以最重要的就是 next 数组的求解。 “前缀”用最后一个字符以外的全部组合表示;”后缀”用除了第一个字符以外的全部字符组合。”前缀”和”后缀”的最长的共有元素的长度就是”部分匹配值”。
移动位数 = 已匹配的字符数 - 对应的部分匹配值
方法三: Horspool后缀搜索算法。
(最坏情况下的时间复杂度是O(mn),但平均情况下它的时间复杂度是O(n))
模式串从右向左进行比较,若不匹配,则模式串从不匹配的那个字符开始从右向左寻找是否有该匹配串中不匹配的字符。若有,则移动到相应位置对齐;若没有,则移动一个模式串的长度,继续匹配。
方法四:BM算法
模式串从右向左进行比较,若不匹配,看匹配的那部分字符串是不是在模式串本身中还有重复,有重复的话,对齐。如果没有重复的,就看已经匹配好的那串字符串有没有一部分在前面出现,总之,就是取移动距离最大的进行移动。
二分查找
前提:递增数列
//非递归版本:
public int BinarySearch(int[] arr,int num){
int l=0;
int r=arr.length-1;
while(l<=r){ //!!!!!!!!!!!!!!!!!!
int mid=(l+r)/2;
if(num==arr[mid]) return mid;
else if(num>arr[mid]) l=mid+1;
else r=mid-1;
}
return -1;
}
注:如果有重复数字,返回第一个位置:
if(num==arr[mid]) {
if(mid>0 && arr[mid]==arr[mid-1]) mid--;
return mid;
}
//递归版本
public int BinarySearch(int[] arr,int num,int l,int r){
while(l<=r){ //!!!!!!!!!!!!!!!!!!
int mid=(l+r)/2;
if(num==arr[mid]) return mid;
else if(num>arr[mid]) return BinarySearch(arr,num,mid+1,r);
else return BinarySearch(arr,num,l,mid-1);
}
return -1;
}变形题1:
题目描述:
有一个排过序的数组,包含n个整数,但是这个数组向左进行了一定长度的移位,例如,原数组为[1,2,3,4,5,6],向左移位5个位置即变成了[6,1,2,3,4,5],现在对于移位后的数组,需要查找某个元素的位置。请设计一个复杂度为log级别的算法完成这个任务。
给定一个int数组A,为移位后的数组,同时给定数组大小n和需要查找的元素的值x,请返回x的位置(位置从零开始)。保证数组中元素互异。
测试样例:
[6,1,2,3,4,5],6,6
返回:0
类似: 找出旋转数组中的最小数字
import java.util.*;
public class Finder {
public int findElement(int[] A, int n, int x) {
int l=0;
int r=n-1;
while(l<=r){
int mid=(l+r)/2;
if(x==A[mid]) return mid;
else if(x>A[mid]) {
if(x>A[r] && A[mid]<A[l]) r=mid-1;
else l=mid+1;
}
else{
if(x<A[l]&& A[mid]>A[r]) l=mid+1;
else r=mid-1;
}
}
return -1;
}
}变形题2:
有一个排过序的字符串数组,但是其中有插入了一些空字符串,请设计一个算法,找出给定字符串的位置。算法的查找部分的复杂度应该为log级别。
给定一个string数组str,同时给定数组大小n和需要查找的string x,请返回该串的位置(位置从零开始)。
测试样例:
[“a”,”b”,”“,”c”,”“,”d”],6,”c”
返回:3
解答:这是一道二分查找 的变形题目。唯一的关注点就是当str[mid].equals(“”)时的处理,此时仅通过str[mid].equals(“”)是无法判断目标是在mid的左边还是右边。所以,我们遍历mid左边的元素找到第一个不是空字符串的元素。
如果mid左边的所有元素都是空字符串,则去掉令l=mid+1;否则,二分查找。
import java.util.*;
public class Finder {
public int findString(String[] str, int n, String x) {
int l=0;
int r=n-1;
while(l<=r){
int mid=(l+r)/2;
if(str[mid].equals("")){
int index=mid;
while(index>=l && str[index]=="") index--;
if(index<l) l=mid+1;
else if(str[index]==x) return mid;
else if(str[index].compareTo(x)>0) r=mid-1;
else l=mid+1;
}else{
if(str[mid].equals(x)) return mid;
else if(str[mid].compareTo(x)<0) l=mid+1;
else r=mid-1;
}
}
return -1;
}
}全排列
import java.util.*;
public class Main {
static ArrayList<String> alist=new ArrayList<String>();
public static void quanpailie(char[] str, int i) {
if (i == str.length-1) {
alist.add(String.valueOf(str));
} else {
for (int j = i; j < str.length; j++) {
// if(j!=i && str[j]==str[i]) continue; //有重复字符时,跳过
char temp = str[j]; // 交换数组第一个元素与后续的元素
str[j] = str[i];
str[i] = temp;
quanpailie(str, i + 1); // 后续元素递归全排列
temp = str[j];
str[j] = str[i];
str[i] = temp;
}
}
}
public static void main(String[] args){
Scanner sc=new Scanner(System.in);
while(sc.hasNext()){
String str=sc.nextLine();
quanpailie(str.toCharArray(), 0);
Collections.sort(alist); //排序
for(String s:alist){
System.out.println(s);
}
}
}
}递归和循环
1,斐波那契数列
对于f(n) = f(n-1)+f(n-2),f(0)=0,f(1)=1 , 第一眼看就是递归啊:
if(n<=0) return 0;
if(n==1) return 1;
else return Fibonacci(n-1)+Fibonacci(n-2);然而并没有什么用,测试用例里肯定准备着一个超大的n来让Stack Overflow,为什么会溢出?因为重复计算,而且重复的情况还很严重,举个小点的例子,n=4,看看程序怎么跑的:
Fibonacci(4) = Fibonacci(3) + Fibonacci(2)
= Fibonacci(2) + Fibonacci(1) + Fibonacci(1) + Fibonacci(0)
= Fibonacci(1) + Fibonacci(0) + Fibonacci(1) + Fibonacci(1) + Fibonacci(0);由于我们的代码并没有记录Fibonacci(1)和Fibonacci(0)的结果,对于程序来说它每次递归都是未知的,因此光是n=4时f(1)就重复计算了3次之多。
思路: 用循环,最好不要用递归。跟简单的方法是从下往上计算,事件负责度为O(n).

2,类似问题:跳台阶
一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法。

扩展: 题目描述
一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
在n阶台阶,一次有1、2、…n阶的跳的方式时,总得跳法为:
| 0 ,(n=0 )
f(n) = | 1 ,(n=1 )
| 2*f(n-1),(n>=2)
3,相关题目:矩阵覆盖
我们可以用2x1的小矩形横着或者竖着去覆盖更大的矩形。请问用n个2x1的小矩形无重叠地覆盖一个2xn的大矩形,总共有多少种方法?
第一个竖着放,剩下的f(n-1)种;
第一个横着放,剩下的f(n-2)种;

最长公共子串和最长公共子序列
举个例子:
str1=”123ABCD456” str2 = “ABE12345D”
最长公共子串是:123,输出为3
最长公共子序列是:12345,输出为5
这两个都可以用动态规划,只是状态转移方程有点区别
最长公共子串是:
dp[i][j] – 表示以str1[i]和str2[j]为结尾的最长公共子串
当str1[i] == str2[j]时,dp[i][j] = dp[i-1][j-1] + 1;
否则,dp[i][j] = 0;
最优解为max(dp[i][j]),其中0<= i< len1, 0<=j < len2;
最长公共子序列是:
dp[i][j] – 表示子串str1[0…i]和子串str[0…j]的最长公共子序列
当str1[i] == str2[j]时,dp[i][j] = dp[i-1][j-1] + 1;
否则,dp[i][j] = max(dp[i-1][j], dp[i][j-1]);
最优解为dp[len1-1][len2-1];
so,代码如下:
//求最长公共子串
import java.util.Scanner;
public class Main{
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner sc = new Scanner(System.in);
String str1 = "";
String str2 = "";
while(sc.hasNext()){
str1 = sc.next();
str2 = sc.next();
System.out.println(getCommonStrLength(str1, str2));
}
}
public static int getCommonStrLength(String str1, String str2){
int len1 = str1.length();
int len2 = str2.length();
int[][] dp = new int[len1+1][len2+1];
for(int i=0;i<=len1;i++){
for(int j=0;j<=len2;j++){
dp[i][j] = 0;
}
}
for(int i=1;i<=len1;i++){
for(int j=1;j<=len2;j++){
if(str1.charAt(i-1) == str2.charAt(j-1)){
dp[i][j] = dp[i-1][j-1] + 1;
}else{
dp[i][j] = 0; //区别在这儿
}
}
}
int max = 0;
for(int i=0;i<=len1;i++){
for(int j=0;j<=len2;j++){
if(max < dp[i][j])
max = dp[i][j];
}
}
return max;
}
}//求最长公共子序列
import java.util.Scanner;
public class Main{
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner sc = new Scanner(System.in);
String str1 = "";
String str2 = "";
while(sc.hasNext()){
str1 = sc.next();
str2 = sc.next();
System.out.println(getCommonStrLength(str1, str2));
}
}
public static int getCommonStrLength(String str1, String str2){
int len1 = str1.length();
int len2 = str2.length();
int[][] dp = new int[len1+1][len2+1];
for(int i=0;i<=len1;i++){
for(int j=0;j<=len2;j++){
dp[i][j] = 0;
}
}
for(int i=1;i<=len1;i++){
for(int j=1;j<=len2;j++){
if(str1.charAt(i-1) == str2.charAt(j-1)){
dp[i][j] = dp[i-1][j-1] + 1;
}else{
dp[i][j] = Math.max(dp[i-1][j], dp[i][j-1]); //区别在这儿
}
}
}
return dp[len1][len2];
}
}求最长回文子串
方法一:先把字符串逆序,然后求变成求解两个字符串的最长公共字符串的问题
方法二:判断子串是不是回文,是回文的话看看长度是不是比最大的长度maxlength大。
import java.util.*;
public class Main{
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while(sc.hasNext()){
String str = sc.nextLine();
int max=0;
for(int i=0;i<str.length();i++){
for(int j=i+1;j<str.length();j++){
StringBuffer sb=new StringBuffer(str.substring(i, j+1));
if( j+(j-i+1)<=str.length()){
if( str.substring(j, j+(j-i+1)).equals(sb.reverse().toString()) ){
String result=str.substring(i, j+(j-i+1));
if(result.length()>max){
max=result.length();
}
}
}
}
}
System.out.println(max);
}
}
}1 字符串反转
输入例子: abcd
输出例子: dcba
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String str = sc.nextLine();
//(1)常规方法
for(int i=str.length()-1;i>=0;i--){
System.out.print(str.charAt(i));
}
//(2)调用StringBuffer的reverse().toString()方法
StringBuffer sb=new StringBuffer(str);
System.out.print(sb.reverse().toString());
//(3)入栈出栈
Stack<Character> st=new Stack<Character>();
for(int i=0;i<str.length();i++)
st.push(str.charAt(i));
for(int i=0;i<str.length();i++){
System.out.print(st.pop());
}
sc.close();
}
}二,句子逆序:
输入例子: I am a boy
输出例子: boy a am I
字符串转换成整数
String to Interger
情况如下:
1,字符串为空,返回0
2,忽略字符串前缀空格,若全是空格,返回0
3,忽略前缀空格后若为“+”、“-”,继续往后读,若是数字开始处理,若不是返回0
4,处理数字的过程中,若之后为非数字就停止转换,返回当前值
5,上述过程中,若转换出的值超过int范围就返回int的最大值或最小值
package zlk;
public class Solution {
public int myAtoi(String str) {
if (str.length() == 0) return 0; //空字串返回0
int i = 0;
while ( i<str.length()-1 && str.charAt(i) == ' ')
i++;
if (str.charAt(i) == '\0') //忽略前缀空格,全为空格返回0
return 0;
//处理+、-号
int signal = 1;
if (str.charAt(i) == '+') i++;
else if (str.charAt(i) == '-'){
signal = -1;
i++;
}
//转换整数
int result = 0;
for (; i < str.length();i++) {
if (str.charAt(i) >= '0' && str.charAt(i) <= '9') {
result = result * 10 + signal*(str.charAt(i)-'0');// 字符-'0'转换为int型!
//机测版溢出处理 Integer.MAX_VALUE:2147483647 ;Integer.MIN_VALUE:-2147483648
if(result>Integer.MAX_VALUE/10 ||(result==Integer.MAX_VALUE/10 && str.charAt(9)>7))
return Integer.MAX_VALUE;
else if(result<Integer.MIN_VALUE/10 || (result==Integer.MIN_VALUE/10 && str.charAt(9)>8))
return Integer.MIN_VALUE;
/*
//记忆版溢出处理
if(signal==1 && result>Integer.MAX_VALUE) return Integer.MAX_VALUE;
if(signal==-1 && result<Integer.MIN_VALUE) return Integer.MIN_VALUE;
*/
}
else if(result==0) return 0;
}
return result;
}
public static void main(String[] args) {
Solution m=new Solution();
System.out.println(m.myAtoi("-2147483649 "));
}
}字符串替换空格
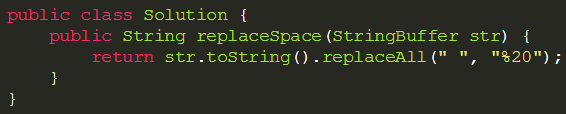
题目描述:
请实现一个函数,将一个字符串中的空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
方法一:正则表达式 ,运行效率低,不推荐
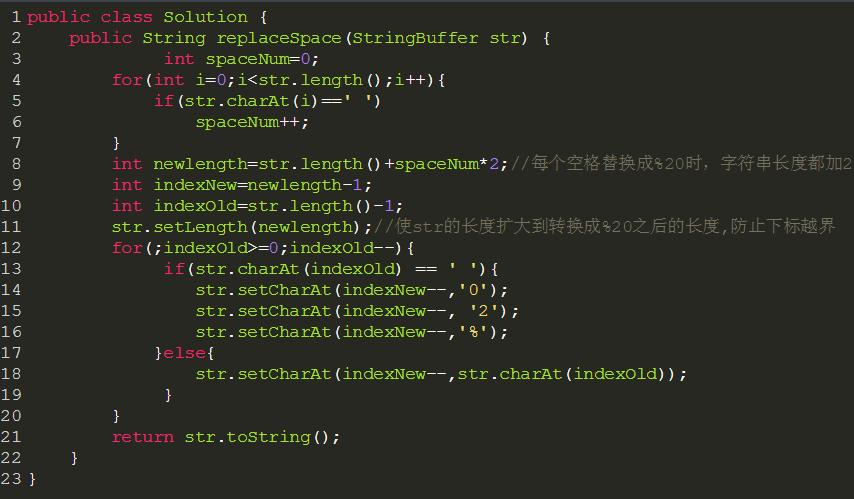
方法二:时间复杂度为O(n)的解法,搞定offer就靠它了
问题1:如果空间不够,替换字符串,需要在原来的字符串上做替换,不能新开辟一个字符串做替换;
问题2:在当前字符串替换,怎么替换才更有效率(不考虑java里现有的replace方法)。
从前往后替换,后面的字符要不断往后移动,要多次移动,所以效率低下,O(n2)
从后往前,先计算需要多少空间,然后从后往前移动,则每个字符只为移动一次,这样效率更高,O(n)。
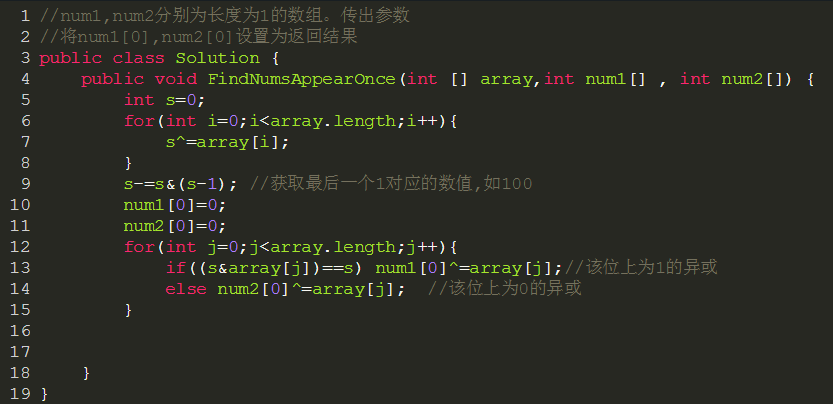
找出数组中只出现一次的数字
题目描述:
一个整型数组里除了两个数字之外,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。
此题考察的是异或运算的特点:即两个相同的数异或结果为0。
此题用了两次异或运算特点:
(1)第一次使用异或运算,得到了两个只出现一次的数相异或的结果。
(2)因为两个只出现一次的数肯定不同,即他们的异或结果一定不为0,一定有一个位上有1。另外一个此位上没有1,我们可以根据此位上是否有1,将整个数组重新划分成两部分,一部分此位上一定有1,另一部分此位上一定没有1,然后分别对每部分求异或,分别得到两部分只出现一次的数。
找出数组中出现次数超过一半的数字
解法一:
每次去掉两个不同的数,则出现次数超过一半的数在剩余数组中仍然超过一半。 故从第一个数开始,计数为1.后一个数依次与前一个数比较,若相同计数加一,不同减一。当计数为0时将其设置为下一个数,计数为1继续重复操作。
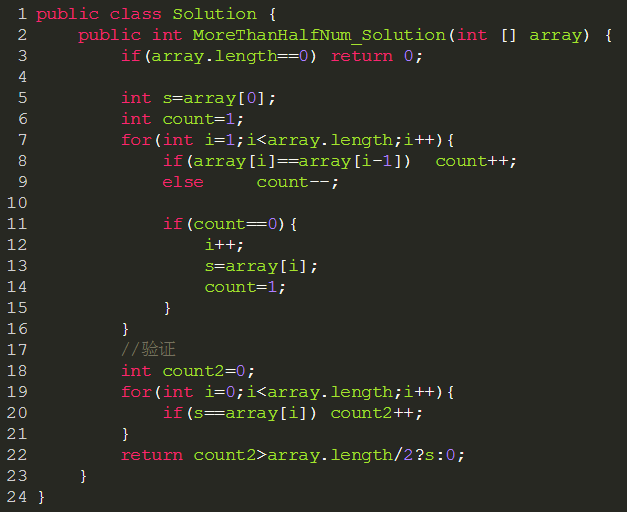
解法二:
若数组中有一个数字出现的次数超过数组长度的一半,排序后中间的数必为该超过一半的数。
故可利用快排中的Partition()方法找出中间值,并验证。
public class Main {
public int Partition(int[] arr,int l,int r){
int key=arr[l];
while(l<r){
while(l<r && arr[r]>=key) r--;
arr[l]=arr[r];
while(l<r && arr[l]<=key) l++;
arr[r]=arr[l];
}
arr[l]=key;
return l;
}
public int MoreThanHalfNum_Solution(int [] array) {
if(array.length==0) return 0;
int l=array[0];
int r=array.length-1;
int q=Partition(array,l,r);
int mid=array.length/2;
while(q!=mid){
if(q>mid) q=Partition(array,l,q-1);
else q=Partition(array,q+1,r);
}
//验证
int count=0;
for(int i=0;i<array.length;i++){
if(array[q]==array[i]) count++;
}
return count>array.length/2?array[q]:0;
}
public static void main(String[] args) {
int[] arr={1,7,7,1};
System.out.print(new Main().MoreThanHalfNum_Solution(arr));
}
}找出数组中最小的k个数
解法一:复杂度O(n),只有当我们可以修改数组时可用。
利用快排中的partition方法找到q值,使其等于k即可,前k个数为最小
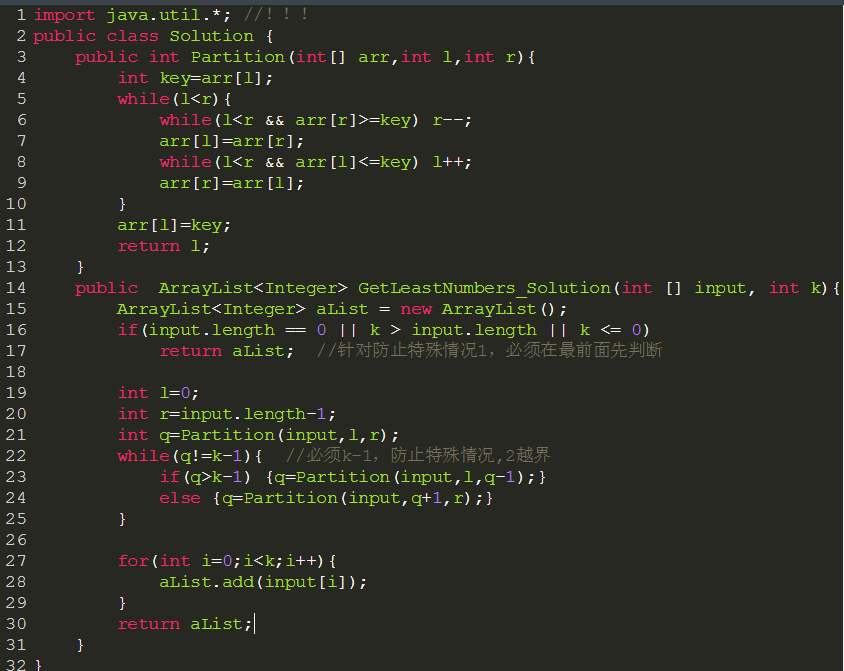
解法二:复杂度O(nlogk),特别适合处理海量数据。
创建大小为k的容器,依次读取放入,若满了则将插入的数与容器中最大的数比较,若比它小则替换。
找出旋转数组中的最小数字
题目描述
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。
输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。
例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个旋转,该数组的最小值为1。
NOTE:给出的所有元素都大于0,若数组大小为0,请返回0。
思路:旋转之后的数组实际上可以划分成两个有序的子数组:前面子数组的大小都大于后面子数组中的元素 注意到实际上最小的元素就是两个子数组的分界线。本题目给出的数组一定程度上是排序的,因此我们试着用二分法实现O(logn)的查找。
1.包含两个有序序列
2.最小数一定位于第二个序列的开头
3.前序列的值都>=后序列的值
计算二进制数中1的个数
题目描述
输入一个整数,输出该数二进制表示中1的个数。其中负数用补码表示。
最佳答案及分析:
举个例子:一个二进制数1100,减一得到的结果是1011.我们发现减1的结果是把最右边的一个1开始的所有位都取反了。这个时候如果我们再把原来的整数和减去1之后的结果做与运算,从原来整数最右边一个1那一位开始所有位都会变成0。如1100&1011=1000.也就是说:
把一个整数减去1,再和原整数做与运算,会把该整数最右边一个1变成0.那么一个整数的二进制有多少个1,就可以进行多少次这样的操作。
计算数值的整数次方
传统公式求解时间复杂度O(n),不建议
public class Solution {
public double Power(double base, int exponent) {
double result=1;
for(int i=0;i<Math.abs(exponent);i++){
result*=base;
}
if(exponent<0){
result=1/result;
}
return result;
}
}递归,全面而高效的解法,时间复杂度O(logn):
n为偶数时,a^n=a^(n/2) * a^(n/2);
n为奇数时,a^n=(a^(n-1)/2)(a^(n-1)/2))*a =(a^(n/2)(a^(n/2))*a
链表反转
public class Solution {
public ListNode ReverseList(ListNode list){
if(list==null) return null;
ListNode pre=null;
ListNode next=null;
while(list!=null){
next=list.next;
list.next=pre;
pre=list;
list=next;
}
return pre;
}
合并两个链表
//递归方式:
public class Solution {
public ListNode Merge(ListNode list1, ListNode list2) {
if(list1 == null) return list2;
if(list2 == null) return list1;
ListNode list=null;
if(list1.val<=list2.value){
list=list1;
list.next=Merge(list1.next,list2);
}
else if(list1.val>list2.value){
list=list2;
list.next=Merge(list1,list2.next);
}
return list;
}
}
//非递归方式:
public class Solution {
public ListNode Merge(ListNode list1, ListNode list2) {
if(list1 == null||list2==null) return list1==null? list2:list1;
ListNode head=null;
if(list1.val<=list2.val){
head=list1;
list1=list1.next;
}else{
head=list2;
list2=list2.next;
}
ListNode tmp=head;
while(list1!=null&&list2!=null){
if(list1.val<=list2.val){
tmp.next=list1;
list1=list1.next;
}else{
tmp.next=list2;
list2=list2.next;
}
tmp=tmp.next;
}
tmp.next= list1==null?list2:list1;
return head;
}
}链表中倒数第k个结点
题目描述
输入一个链表,输出该链表中倒数第k个结点。
假设整个链表有n个节点,那么倒数第k个节点就是从头结点开始往后走n-k+1步。那么有两步:1,遍历链表求得n值;2,遍历链表找到低n-k+1个结点。如何一次遍历实现呢?
时间复杂度O(n),一次遍历即可:
我们可以定义两个指针p,pre。 p指针先跑,并且记录节点数,当p指针跑了k-1个节点后,pre指针开始跑, 当p指针跑到最后时,pre所指指针就是倒数第k个节点
链表从尾到头打印
题目描述:
输入一个链表,从尾到头打印链表每个节点的值。
输入描述: 输入为链表的表头
输出描述: 输出为需要打印的“新链表”的表头
方法一:借助堆栈的“后进先出”实现
方法二:借助递归实现(递归的本质还是使用了堆栈结构)
用两个栈实现队列
题目描述:
用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型。
思路:有两个栈,栈1和栈2.当入栈的时候,我们将它全放进栈1中,当需要出栈的时候,我们将栈1出栈到栈2中,然后再将栈2依次出栈.
但是在交换元素的时候需要判断两个栈的元素情况: “进队列时”,队列中是还还有元素,若有,说明栈2中的元素不为空,此时就先将栈2的元素倒回到栈1 中,保持在“进队列状态”。 “出队列时”,将栈1的元素全部弹到栈2中,保持在“出队列状态”。 所以要做的判断是,进时,栈2是否为空,不为空,则栈2元素倒回到栈1,出时,将栈1元素全部弹到栈2中,直到栈1为空。
判断栈的弹出序列
题目描述:
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。(注意:这两个序列的长度是相等的)
思路:
借助一个辅助的栈,先循环将pushA中的元素入栈,遍历的过程中检索popA可以pop的元素,如果栈不为空且栈顶元素等于弹出序列的元素则弹出。 如果循环结束后栈还不空,则说明该序列不是pop序列。















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









