







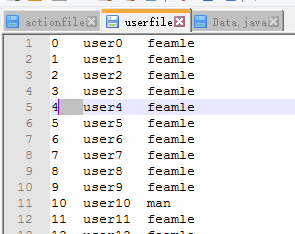
用户表:ID+name+sex
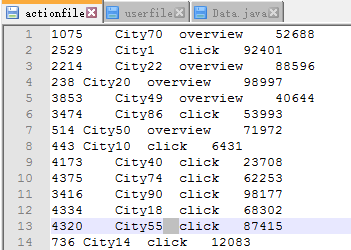
用户行为表:ID+City+action+notes
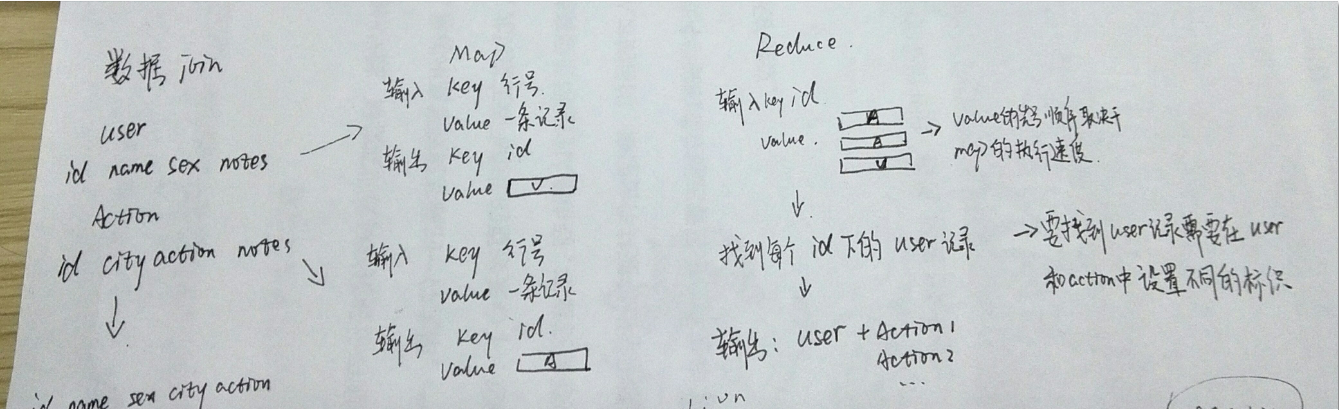
Join完成后的形式:ID+name+sex+city+action+notes
package com.qst.DateJoin;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.mapred.FileSplit;
public class Data {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, Text> {
private Text theKey = new Text();
private Text theValue = new Text();
/*Map方法:输入的key是行号,输入的value是每一行的数据
输出的数据key是两个文件共有的用户ID,输出的value是每个文件除ID以外的数据*/
public void map(LongWritable key, Text value, OutputCollector<Text, Text> output, Reporter reporter)
throws IOException {
//获取文件的路径
String filePath = ((FileSplit) reporter.getInputSplit()).getPath().toString();
//将每次传过来的Value按照\t分隔
String[] line = value.toString().split("\\t");
//判断Value是否为空
if (line == null || line.equals(""))
return;
//判断截取的字符串数组的长度,因为用户表每一行至少有三个属性,所以长度至少为3
if (line.length < 3)
return;
//根据文件名,判断Map中输入的Value属于user还是属于Action
if (filePath.contains("userfile")) {
//获取ID
String userid = line[0];
//将除ID以外的值拼接起来传递给Reduce
String userValue = line[1] + "\t" + line[2];
theKey.set(userid);
//在传递的Value中添加标识,以便在Reduce的时候分辨Value是来自用户表还是来自用户行为表
theValue.set("u:" + userValue);
output.collect(theKey, theValue);
} else if (filePath.contains("actionfile")) {
String userid = line[0];
String userValue = line[1] + "\t" + line[2] + "\t" + line[3] + "\t";
theKey.set(userid);
theValue.set("a:" + userValue);
output.collect(theKey, theValue);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterator<Text> values, OutputCollector<Text, Text> output, Reporter reporter)
throws IOException {
//因为传递过来的Value不止一个是Iterator形式的,所以分别创建链表来存储User的Value和Action的Value
List<String> userlist = new ArrayList<String>();
List<String> valuelist = new ArrayList<String>();
while (values.hasNext()) {
//遍历Value,因为Value是Text类型的,所以转换成字符串类型
String value = values.next().toString();
//通过在Map中添加的标识符来把Value分开,以便拼接
if (value.startsWith("u:")) {
String user = value.substring(2);
userlist.add(user);
} else if (value.startsWith("a:")) {
String val = value.substring(2);
valuelist.add(val);
}
}
//最后输出的形式是一个User和许多User的行为,所以遍历两个链表将数值拼接
int i, j;
for (i = 0; i < userlist.size(); i++) {
for (j = 0; j < valuelist.size(); j++) {
output.collect(key, new Text(userlist.get(i) + "\t" + valuelist.get(j)));
}
}
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(DataJoin.class);
conf.setJobName("Data Join");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}















 352
352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









