






在之前学习了基本的python知识以后,我决定编写自己的第一个python程序。
参考内容有:极客学院 课程:python 单线程爬虫
可汗学院公开课 全部
根据以上两个内容为基础,编写一个爬取网站源代码的python程序,
中间一步步来,终极目标是实现 RSS 那样的新闻聚合功能。这个想法我已经想了快半个月了,可是一直迟迟没有实现,正好趁这个机会。准备开始像一个正式的程序员一样,写自己的博客,发布自己的程序。
首先,准备好开发工具 Python 和 PyScripter 集成开发环境。
然后是准备 Python的第三方库 Requestes 的下载安装,
Requests 官方网页上写着
Requests:HTTP for humans
作用是替代Python的urllib2模块

这是用urllib2实现的一个简单的爬虫,作用是爬取github页面的一些内容
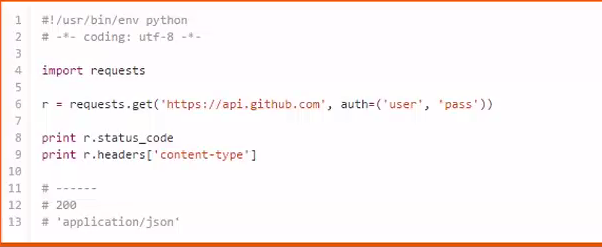
而用requests只要4行就能够实现
如何安装requests 只要一行代码 windows : pip install requests
linux : sudo pip install requests
还有就是 Python 第三方库的安装技巧,为了避免撞墙
极客学院教师推荐 www.lfd.uci.edu/~gohlke/pythonlibs/ 这个网站几乎有所有的python第三方库文件
下载好以后解压复制粘贴放入lib文件夹下面。
使用requests 获取网页源代码
下面是源代码
#-*-coding:utf8-*-
import requests
html = requests.get('http://open.163.com/movie/2011/3/0/C/M8O9BOGDE_M8OEFC20C.html')
print html.text















 1832
1832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









