







数据结构与算法-排序(一)
排序算法有很多种,此处仅介绍五种最经典通用的排序算法:冒泡排序、插入排序、选择排序、归并排序、快速排序。篇幅有限,本篇仅介绍前三种。
| 最好时间复杂度 | 最坏时间复杂度 | 平均时间复杂度 | 稳定排序 | 原地排序 | |
|---|---|---|---|---|---|
| 冒泡排序 | O(n) | O(n^2) | O(n^2) | 是 | 是 |
| 插入排序 | O(n) | O(n^2) | O(n^2) | 是 | 是 |
| 选择排序 | O(n^2) | O(n^2) | O(n^2) | 否 | 是 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | 是 | 否 |
| 快速排序 | O(nlogn) | O(n^2) | O(nlogn) | 否 | 是 |
一、分析
既然排序算法有很多种,那么为了比较不同算法之间区别评价优劣,便需要从算法的时间消耗,空间消耗与稳定性三方面入手。
1.1 时间消耗
可以通过时间复杂度来分析算法的时间消耗,最好、最坏和平均时间复杂度都不可缺。同时,还要获知最好、最坏时间复杂度对应要排序的初始数据集的特点。因为数据的有序度不同,例如有的接近有序,有的完全无序,这对于排序的执行时间自然是有影响的,知道排序算法在不同数据下的性能表现有助相互对比分析。
另外,当计算时间复杂度时,默认n值很大,此时会忽略它的系数、低阶和常数,但当n比较小时便不可忽略。因此,在对同一阶时间复杂度的排序算法性能进行对比时,系数、低阶和常数便要考虑进来。
在排序过程中,会频繁进行比较与元素移动操作,在对排序算法进行效率分析时也应当考虑在内。
1.2 空间消耗
空间消耗可以通过空间复杂度来衡量。其中,对于空间复杂度为O(1)的排序算法,称为原地排序算法。
1.3 稳定性
除了时间复杂度与空间复杂度外,排序算法还有一个重要的分析指标,即稳定性,意思是如果待排序序列中存在数值相等的元素,排序结束后相等元素之间原有的顺序保持不变。举例来说,有一组序列 8, 5, 6, 9, 6, 4, 其中存在值相等的元素6,为便于区分,将前一个6记为6a,后一个6记为6b,即 8, 5, 6a, 9, 6b, 4 , 若排序后两个6顺序没变,即 4, 5, 6a, 6b, 8, 9, 则称这种排序算法是稳定的排序算法,否则称为不稳定的排序算法。
需要注意的是,在某些业务场景中,稳定性是很重要的。例如,有一组学生信息序列,每个学生的信息包括学生学号与成绩。要求将学生成绩进行排序,对于成绩相同的学生按学号进行排序。当然,可以先对成绩进行排序,然后再针对相同成绩的学生进行学号排序,但这样的实现比较复杂。简单的,可以先对学号进行排序,再对成绩进行排序。若排序算法是稳定的,第二次的排序结束后相同成绩的学生已经是有序的。
二、简单排序算法简介
2.1 冒泡排序
不断遍历待排序序列,依次比较相邻元素大小,看是否满足大小关系要求。若不满足,则互换位置。如下图第一次遍历过程,首先,8与5比较,8比5大,互换位置,接着,8与6比较,互换,8与9比较,不变,9与6比较,互换,9与4比较,互换,第一次遍历结束,9归位。
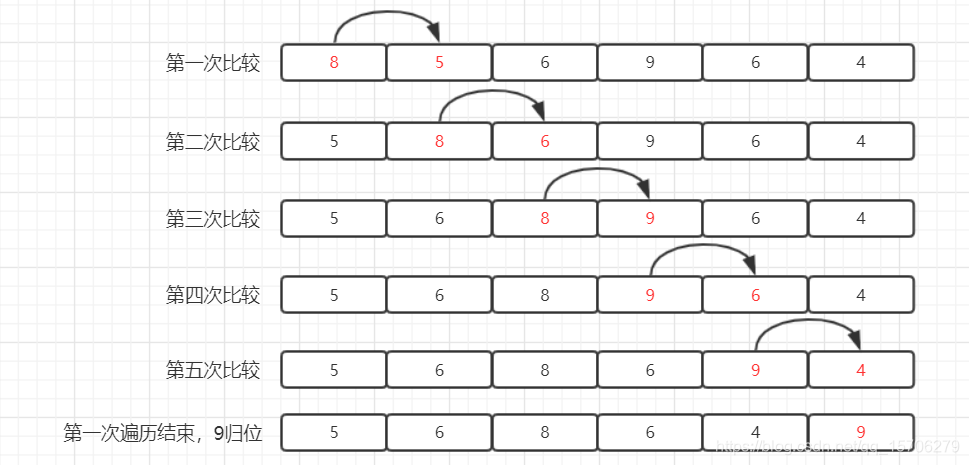
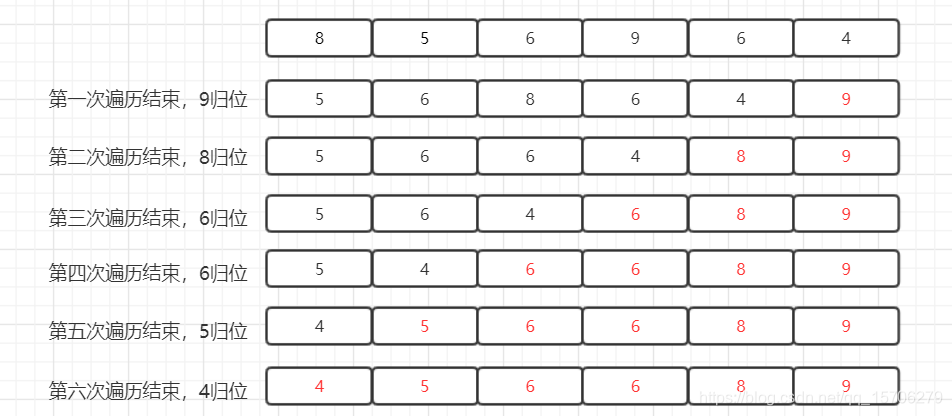
可以发现,在一次遍历结束时,算法会将未排序(黑色数字表示)中的最大值移至未排序区间的末尾,接着将该元素并入已排序(红色数字表示)区域。一次冒泡会让至少一个元素移动到它应该在的位置,重复 n 次,就完成了 n 个数据的排序工作。
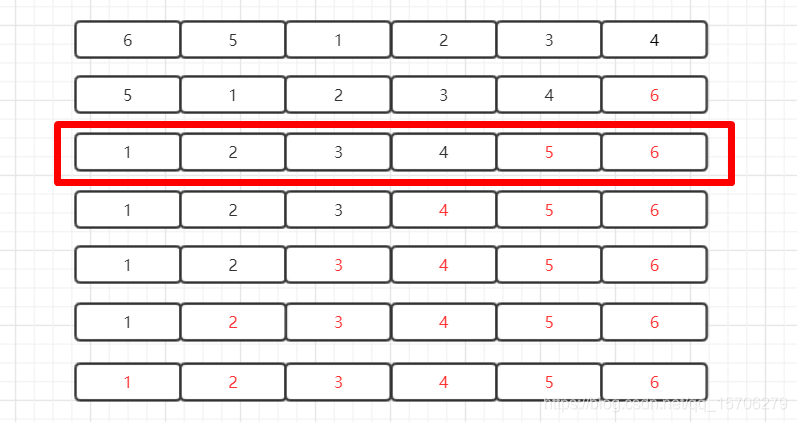
但是,当考察最好情况下(即待排序序列已经完全有序)算法表现时,会发现算法的效率不尽如人意。如下图所示,当第二次遍历结束时,序列已经实现有序,但算法本身却没有察觉,仍然继续遍历直至n次结束。事实上,如果在第三次遍历时,会发现此次遍历没有进行数据交换,说明序列本身已经实现有序,后续操作不必执行。要达到这一目的,只需引入一个标记位即可。
代码简单示例如下:
public void bubbleSort(int[] a, int n){
if(n <= 1) return;
for(int i = 0; i < n; i++){
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









