










💗博主介绍:✌全网粉丝10W+,CSDN全栈领域优质创作者,博客之星、掘金/华为云/阿里云等平台优质作者。
👇🏻 精彩专栏 推荐订阅👇🏻
计算机毕业设计精品项目案例-200套
🌟文末获取源码+数据库+文档🌟
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以和学长沟通,希望帮助更多的人
一.前言
随着金融市场的日益复杂化和数据量的急剧增长,传统的投资分析方法已难以满足现代投资者的需求。在这一背景下,股票量化平台的设计与实现显得尤为重要。通过运用可视化分析的方式,该平台能够高效处理海量数据,发现隐藏在数据背后的投资机会,并为投资者提供科学、客观的投资决策支持。这解决了传统投资决策中主观性强、效率低下、难以适应市场快速变化等问题,为投资者提供了一种全新的投资方式,有助于提升投资效率、降低投资风险,并推动金融行业的创新发展。
本股票交易可视化平台系统采用B/S架构、开发语言使用Python语言,并采用Hadoop技术、Scrapy爬虫技术以及 Django框架进行开发,利用大数据和信息化的手段提升投资决策效率、降低人为干扰,并促进资源共享与合作。
二.技术环境
开发语言:Python
python框架:Django
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
爬虫框架:Scrapy
大数据框架:Hadoop
开发软件:Idea/Eclipse
前端框架:vue.js
三.功能设计
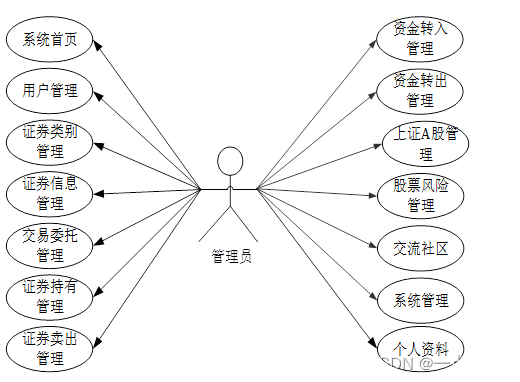
管理员端的功能主要是开放给系统的管理人员使用,管理员的用例图如下所示:
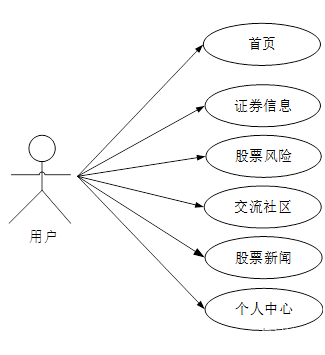
用户的功能主要是对个人账号和密码进行更新管理,对系统首页、证券信息、股票风险、交流社区、股票新闻、个人中心进行查询详情操作。用户用例图,如图所示。
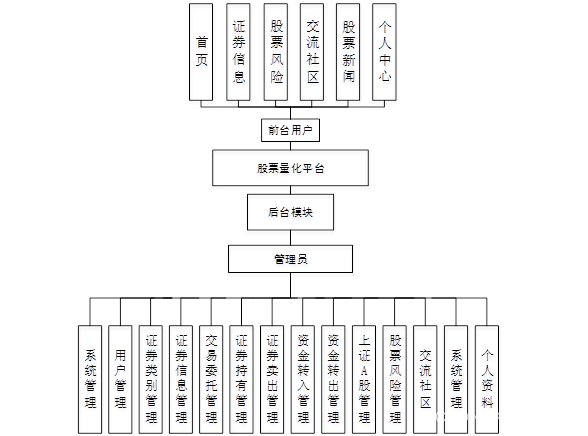
系统功能结构图是系统设计阶段,系统功能结构图只是这个阶段一个基础,整个系统的架构决定了系统的整体模式,是系统的根据。本系统的整个设计结构如图所示。
四.数据设计
概念模型的设计是为了抽象真实世界的信息,并对信息世界进行建模。它是数据库设计的强大工具。数据库概念模型设计可以通过E-R图描述现实世界的概念模型。系统的E-R图显示了系统中实体之间的链接。而且Mysql数据库是自我保护能力比较强的数据库,下图主要是对数据库实体的E-R图:

五.部分效果展示
前台用户功能实现效果
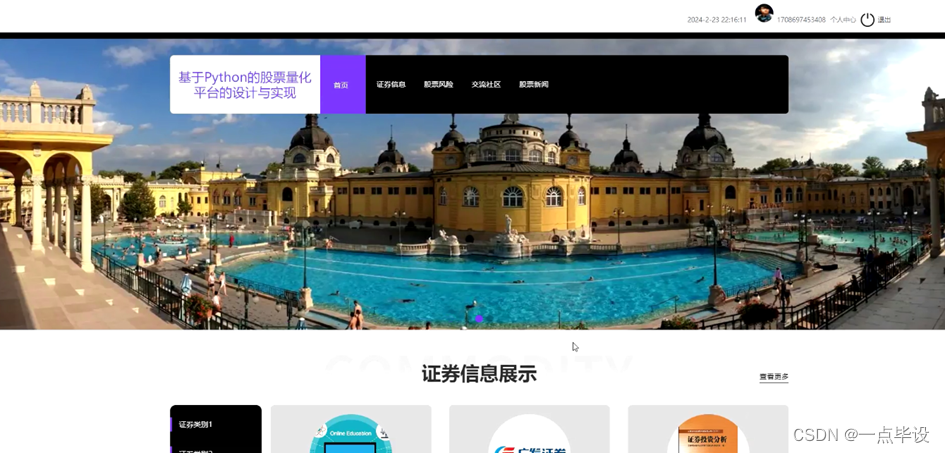
当游客打开系统的网址后,首先看到的就是首页界面。在这里,游客能够看到股票量化平台的导航条显示首页、证券信息、股票风险、交流社区、股票新闻、个人中心等,系统首页界面如图所示:
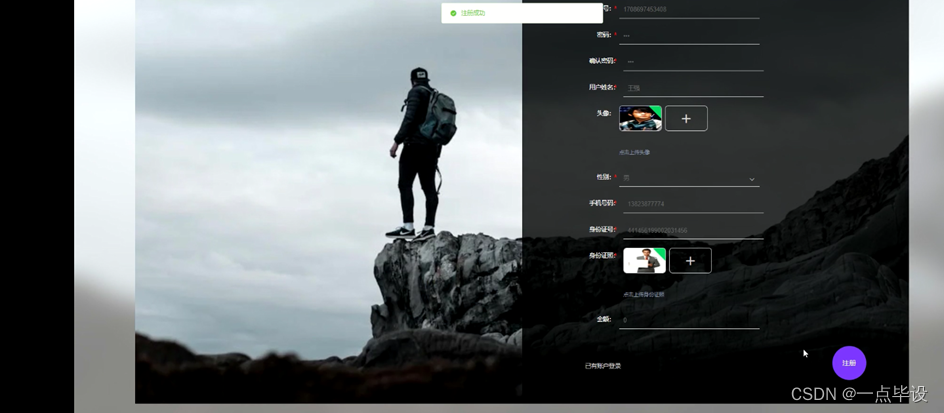
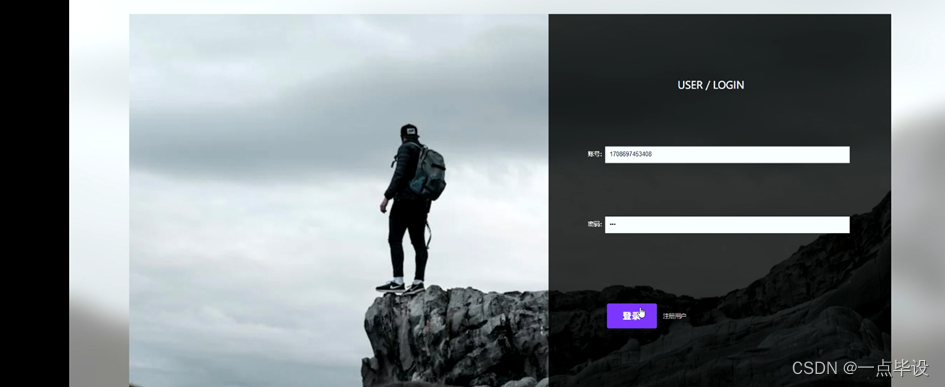
当用户进入系统进行相关操作前必须进行注册、登录,用户注册、用户登录界面如图所示:
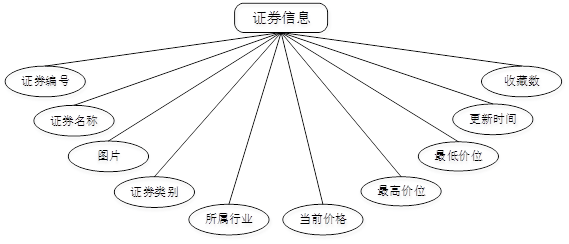
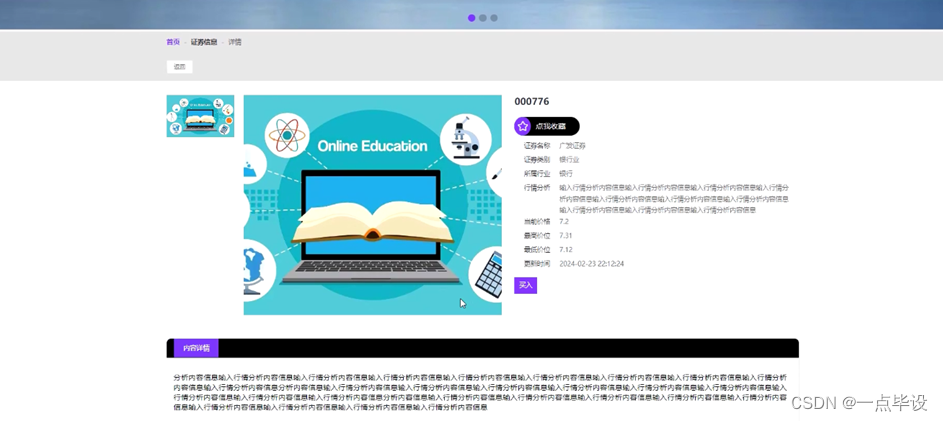
用户点击证券信息:在证券信息页面的搜索栏输入证券编号、证券名称、证券类别,进行查询,可以查看证券编号、证券名称、图片、证券类别、所属行业、当前价格、最高价位、最低价位、更新时间、收藏数等内容,也可以点击买入或者收藏等操作,如图所示:
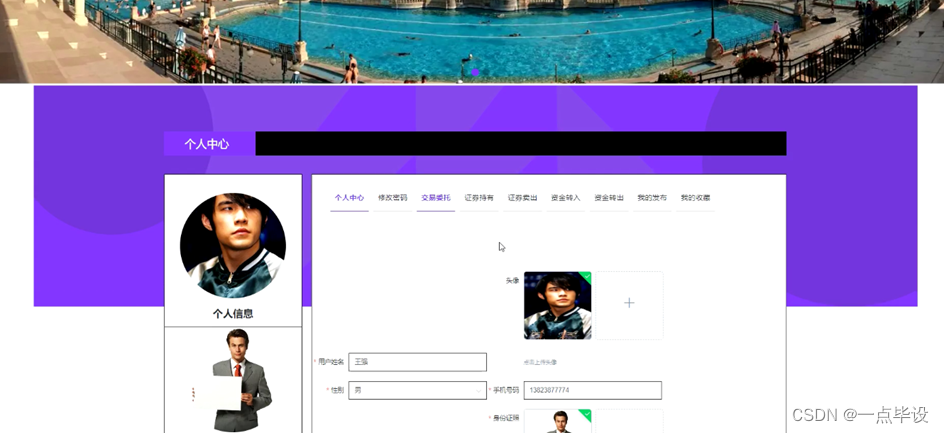
用户点击个人中心,在个人中心页面可以修改个人信息,还可以对修改密码、交易委托、证券持有、证券卖出、资金转入、资金转出、我的发布、我的收藏等进行操作,如图所示:
后台管理员功能实现效果
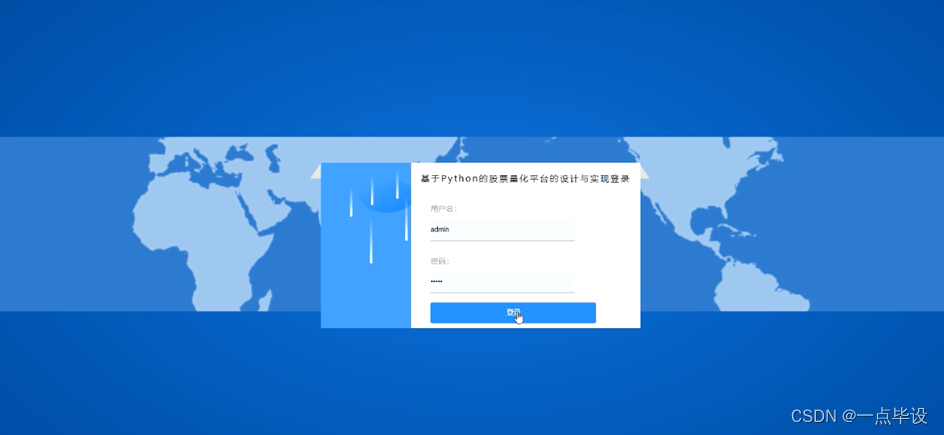
在登录界面中需要使用el-input标签实现输入框供管理员输入用户名和密码,需要使用name标签表示不同的信息。在登录界面中还需要包括角色的按钮,使用el-radio表示按钮,管理员可以点击按钮从而选择不同的角色,如图所示。
管理员登录进入股票量化平台可以查看系统首页、用户管理、证券类别管理、证券信息管理、交易委托管理、证券持有管理、证券卖出管理、资金转入管理、资金转出管理、上证A股管理、股票风险管理、交流社区、系统管理、个人资料等功能,进行详细操作。
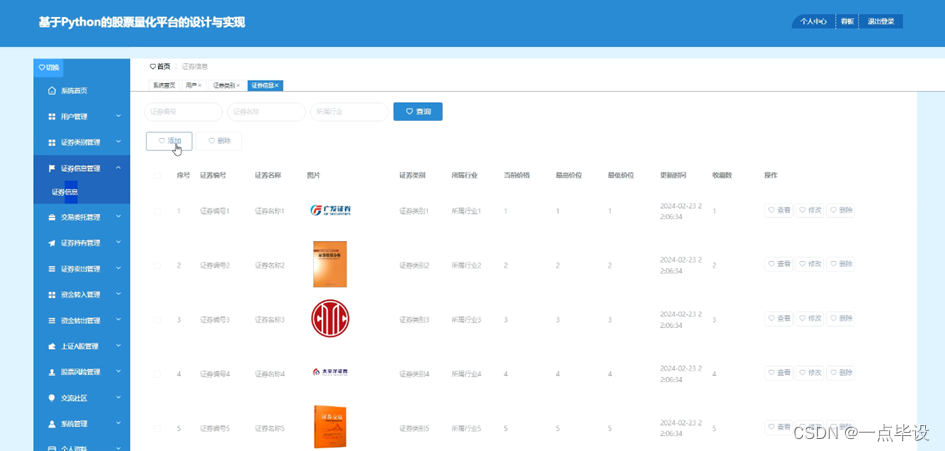
管理员点击证券信息管理;在证券信息管理页面输入证券编号、证券名称、图片、证券类别、所属行业、当前价格、最高价位、最低价位、更新时间、收藏数,还可以点击添加或删除等操作;如图所示。
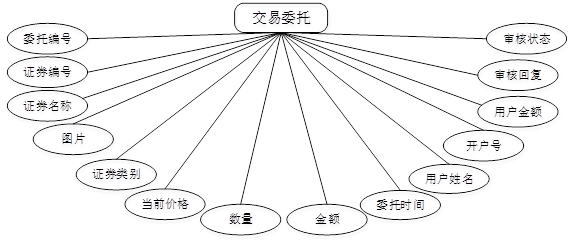
管理员点击交易委托管理;在交易委托管理页面输入委托编号、证券编号、证券名称、图片、证券类别、当前价格、数量、金额、委托时间、用户姓名、开户号、用户金额、审核回复、审核状态,还可以点击删除等操作;如图所示。

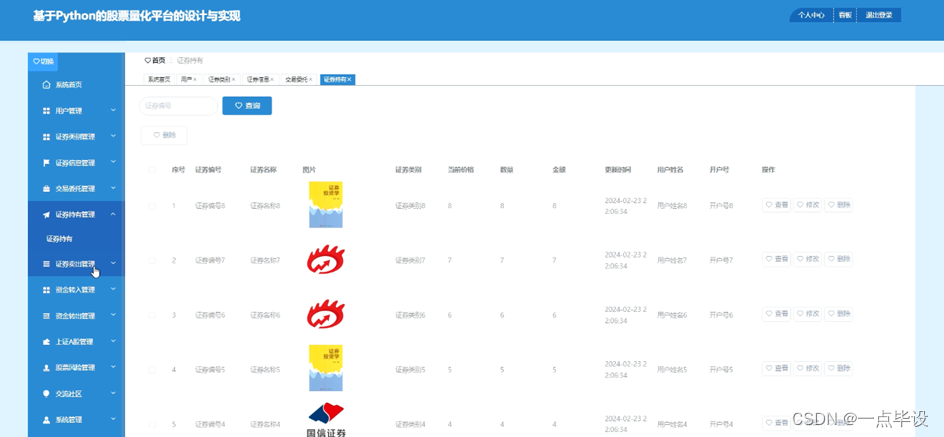
管理员点击证券持有管理;在证券持有管理页面包括证券编号、证券名称、图片、证券类别、当前价格、数量、金额、更新时间、用户姓名、开户号,还可以点击添加或删除等操作;如图所示。
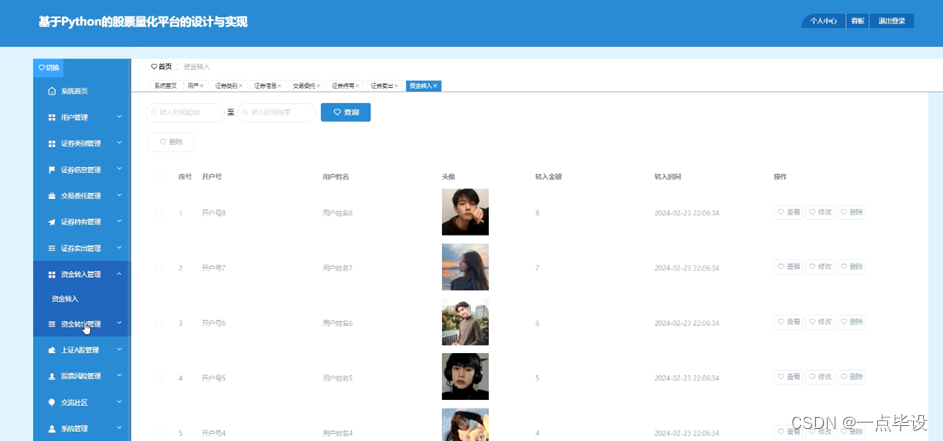
管理员点击资金转入管理;在资金转入管理页面包括开户号、用户姓名、头像、转入金额、转入时间,还可以点击添加或删除等操作;如图所示。
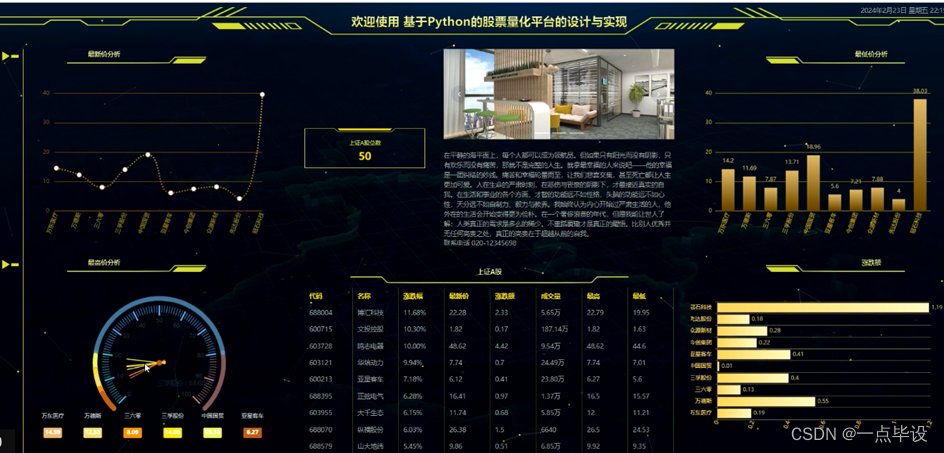
数据可视化分析大屏展示实现效果
股票交易可视化平台基本情况展示,如图所示。
六.部分功能代码
# # -*- coding: utf-8 -*-
# 数据爬取文件
import scrapy
import pymysql
import pymssql
from ..items import ShangzhenItem
import time
from datetime import datetime,timedelta
import datetime as formattime
import re
import random
import platform
import json
import os
import urllib
from urllib.parse import urlparse
import requests
import emoji
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from selenium.webdriver import ChromeOptions, ActionChains
from scrapy.http import TextResponse
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
class ShangzhenSpider(scrapy.Spider):
name = 'shangzhenSpider'
spiderUrl = 'https://quote.eastmoney.com/center/gridlist.html#sh_a_board'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
realtime = False
def __init__(self,realtime=False,*args, **kwargs):
super().__init__(*args, **kwargs)
self.realtime = realtime=='true'
def start_requests(self):
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'm0819850_shangzhen') == 1:
cursor.close()
connect.close()
self.temp_data()
return
option = ChromeOptions()
# 启动 Chrome 浏览器并设置代理
option.add_experimental_option('excludeSwitches', ['enable-automation']) # 开启实验性功能
driver = webdriver.Chrome(options=option)
script = '''
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
'''
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": script})
# 添加代理设置到ChromeOptions
driver.get(self.spiderUrl)
driver.implicitly_wait(5) # 等待10秒,可以根据需要调整
# 执行JavaScript代码以渲染页面
driver.execute_script("window.onload")
startPage = 1
for page in range(1, 10):
if page != 1: # 首页不用模拟点击
element = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, "//a[@class='next paginate_button']")))
# 模拟点击操作
element.click()
# 等待JavaScript渲染完成
selectFlag = ".//a[contains(@class, 'paginate_button current') and contains(@data-index, '%s')]" % (page)
print("selectFlag:", selectFlag)
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.XPATH, selectFlag)))
driver.implicitly_wait(2)
# 定位到需要滚动的元素,例如页面的某个元素
scroll_element = driver.find_element(By.XPATH, selectFlag) # 替换为实际的元素ID
# 创建ActionChains对象
actions = ActionChains(driver)
# 模拟往下滑动
actions.move_to_element(scroll_element).perform()
if page < startPage:
continue
time.sleep(1)
htmlContent = driver.page_source
yield scrapy.Request(url=self.spiderUrl, meta={"htmlContent": htmlContent}, callback=self.parse,
dont_filter=True)
driver.close()
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'm0819850_shangzhen') == 1:
cursor.close()
connect.close()
self.temp_data()
return
textResponse = TextResponse(url="", body=response.meta['htmlContent'].encode(), encoding='utf-8')
list = textResponse.css('table.table_wrapper-table tbody tr')
for item in list:
fields = ShangzhenItem()
if '(.*?)' in '''td:nth-child(2) a::text''':
try:
fields["szcode"] = str( re.findall(r'''td:nth-child(2) a::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["szcode"] = str( self.remove_html(item.css('''td:nth-child(2) a::text''').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(3) a::text''':
try:
fields["name"] = str( re.findall(r'''td:nth-child(3) a::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["name"] = str( self.remove_html(item.css('''td:nth-child(3) a::text''').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(5) span::text''':
try:
fields["newprice"] = float( re.findall(r'''td:nth-child(5) span::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["newprice"] = float( self.remove_html(item.css('td:nth-child(5) span::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(6) span::text''':
try:
fields["zdprice"] = str( re.findall(r'''td:nth-child(6) span::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["zdprice"] = str( self.remove_html(item.css('''td:nth-child(6) span::text''').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(7) span::text''':
try:
fields["zdpercent"] = float( re.findall(r'''td:nth-child(7) span::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["zdpercent"] = float( self.remove_html(item.css('td:nth-child(7) span::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(8)::text''':
try:
fields["volume"] = str( re.findall(r'''td:nth-child(8)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["volume"] = str( self.remove_html(item.css('''td:nth-child(8)::text''').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(9)::text''':
try:
fields["turnover"] = str( re.findall(r'''td:nth-child(9)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["turnover"] = str( self.remove_html(item.css('''td:nth-child(9)::text''').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(14)::text''':
try:
fields["yesend"] = float( re.findall(r'''td:nth-child(14)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["yesend"] = float( self.remove_html(item.css('td:nth-child(14)::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(13) span::text''':
try:
fields["nowstart"] = float( re.findall(r'''td:nth-child(13) span::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["nowstart"] = float( self.remove_html(item.css('td:nth-child(13) span::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(11) span::text''':
try:
fields["heightest"] = float( re.findall(r'''td:nth-child(11) span::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["heightest"] = float( self.remove_html(item.css('td:nth-child(11) span::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(12) span::text''':
try:
fields["lowest"] = float( re.findall(r'''td:nth-child(12) span::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["lowest"] = float( self.remove_html(item.css('td:nth-child(12) span::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(15) span::text''':
try:
fields["compare"] = float( re.findall(r'''td:nth-child(15)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["compare"] = float( self.remove_html(item.css('td:nth-child(15)::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(16) span::text''':
try:
fields["hsl"] = str( re.findall(r'''td:nth-child(16)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["hsl"] = str( self.remove_html(item.css('''td:nth-child(16)::text''').extract_first()))
except:
pass
yield fields
# 数据清洗
def pandas_filter(self):
engine = create_engine('mysql+pymysql://root:123456@localhost/spiderm0819850?charset=UTF8MB4')
df = pd.read_sql('select * from shangzhen limit 50', con = engine)
# 重复数据过滤
df.duplicated()
df.drop_duplicates()
#空数据过滤
df.isnull()
df.dropna()
# 填充空数据
df.fillna(value = '暂无')
# 异常值过滤
# 滤出 大于800 和 小于 100 的
a = np.random.randint(0, 1000, size = 200)
cond = (a<=800) & (a>=100)
a[cond]
# 过滤正态分布的异常值
b = np.random.randn(100000)
# 3σ过滤异常值,σ即是标准差
cond = np.abs(b) > 3 * 1
b[cond]
# 正态分布数据
df2 = pd.DataFrame(data = np.random.randn(10000,3))
# 3σ过滤异常值,σ即是标准差
cond = (df2 > 3*df2.std()).any(axis = 1)
# 不满⾜条件的⾏索引
index = df2[cond].index
# 根据⾏索引,进⾏数据删除
df2.drop(labels=index,axis = 0)
# 去除多余html标签
def remove_html(self, html):
if html == None:
return ''
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html).strip()
# 数据库连接
def db_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
# 数据缓存源
def temp_data(self):
connect = self.db_connect()
cursor = connect.cursor()
sql = '''
insert into `shangzhen`(
id
,szcode
,name
,newprice
,zdprice
,zdpercent
,volume
,turnover
,yesend
,nowstart
,heightest
,lowest
,compare
,hsl
)
select
id
,szcode
,name
,newprice
,zdprice
,zdpercent
,volume
,turnover
,yesend
,nowstart
,heightest
,lowest
,compare
,hsl
from `m0819850_shangzhen`
where(not exists (select
id
,szcode
,name
,newprice
,zdprice
,zdpercent
,volume
,turnover
,yesend
,nowstart
,heightest
,lowest
,compare
,hsl
from `shangzhen` where
`shangzhen`.id=`m0819850_shangzhen`.id
))
order by rand()
limit 50;
'''
cursor.execute(sql)
connect.commit()
connect.close()
源码及文档获取
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏👇🏻
最新计算机毕业设计选题篇-选题推荐
小程序毕业设计精品项目案例-200套
Java毕业设计精品项目案例-200套
Python毕业设计精品项目案例-200套
大数据毕业设计精品项目案例-200套
💟💟如果大家有任何疑虑或者需要定制开发、毕设帮助,欢迎在下方位置详细交流。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











