









💗博主介绍:✌全网粉丝15W+,CSDN全栈领域优质创作者,博客之星、掘金/华为云/阿里云等平台优质作者,计算机毕设实战导师。目前专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌
💗主要服务内容:免费功能设计、选题定题、开题报告、任务书、程序开发、论文编写和辅导、论文降重、程序讲解、答辩辅导等,欢迎咨询~
👇🏻 精彩专栏 推荐订阅👇🏻
计算机毕业设计精品项目案例(持续更新)
🌟文末获取源码+数据库+文档🌟
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以和学长沟通,希望帮助更多的人
一.前言
科学技术日新月异,人们的生活都发生了翻天覆地的变化,王者荣耀电竞战队的数据分析当然也不例外。过去的信息管理都使用传统的方式实行,既花费了时间,又浪费了精力。在信息如此发达的今天,我们可以通过网络这个媒介,快速的查找自己想要的信息,更加全方面的了解自己的网站信息。而且人们也可以突破传统信息管理的僵硬模式,制定属于自己的个性化的管理方案。基于现代人们的需求,设计并开发了一款王者荣耀电竞战队的数据分析系统。
本篇文章使用Python与MYSQL技术搭建了一个王者荣耀电竞战队的数据分析系统。对用户提出的功能进行合理分析,然后搭建开发平台以及配置计算机软硬件;通过对数据流图以及系统结构的设计,创建相应的数据库;进行详细的设计,实现主要功能。最后测试网站,并分析测试结果,完善系统,得出系统使用说明书,方便日后的维护以及更新。
作为用户,本系统可以在线搜索,查看并且网站信息;也可以在线互动交流。作为系统的管理员,可以及时的更新数据,也可以随时随地的处理网站信息。便捷的操作界面以及全新的功能会让人们耳目一新。
二.技术环境
开发语言:Python
python框架:django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
爬虫框架:Scrapy
大数据框架:Hadoop
开发软件:PyCharm/vs code
前端框架:vue.js
三.功能设计
在本王者荣耀电竞战队的数据分析系统开发过程中,我们选择了Python作为后端开发语言,通过echarts技术展示可视化大屏,将数据进行展示在看板上。此外,我们还采用了Python开发的Scrapy爬虫技术,用于高效地收集网络数据。并采用了Django框架。Django框架提供了快速开发的可能,同时保证了代码的清晰和高效。在数据存储和操作方面,我们选择了MySQL数据库。前端开发部分,我们使用了HTML、CSS、JavaScript以及流行的前端框架Vue.js,这使得界面设计和用户交互变得更加直观和便捷。在开发工具方面,我们选用了PyCharm和Navicat。其中PyCharm是一款优秀的Python集成开发环境,功能强大且使用方便;而Navicat作为数据库管理工具,拥有友好的用户界面和强大的SQL处理能力,从而大大提高了我们的开发效率。系统管理员主要包含比赛信息管理、系统管理、我的资料等功能。

四.数据设计
系统需要数据库存储系统中的信息,MySQL数据库能够处理系统的信息,当考研信息爬虫与分析需要数据的时候,MySQL数据库能够取得数据交给服务端处理。MySQL数据库能够使用可视化软件操作,管理员可以在可视化软件对数据库的信息管理。
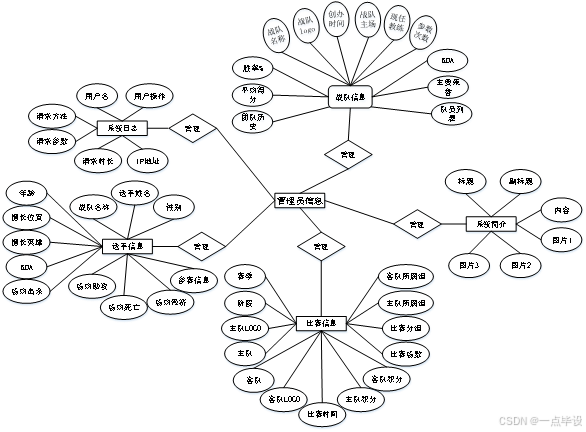
系统数据层设计包括了E-R设计,系统数据实体的设计依赖于E-R的分析和设计,通过E-R能够得到数据库表的设计,E-R能够描述系统所涉及到的实体,还能够描述系统中不同实体的联系和关系。系统总体E-R图如下所示:
五.部分效果展示
在登录流程中,用户首先在Vue前端界面输入用户名和密码。这些信息通过HTTP请求发送到Python后端。后端接收请求,通过与MySQL数据库交互验证用户凭证。如果认证成功,后端会返回给前端,允许用户访问系统。这个过程涵盖了从用户输入到系统验证和响应的全过程。系统登录页面如图所示。
管理员进入主页面,主要功能包括对首页、比赛信息管理、系统管理、我的资料等进行操作。管理员主页面如图所示:
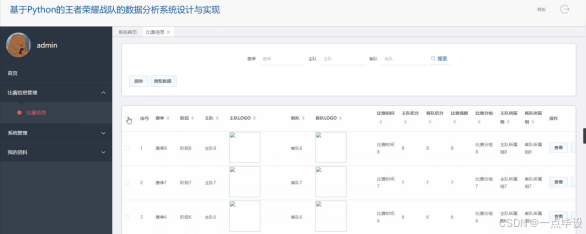
比赛信息管理功能实现是在Django后端部分,您需要创建一个新的应用,然后在该应用下创建一个模型(models.py)来定义比赛信息的数据结构,使用Django的ORM来处理与MySQL数据库的交互,包括比赛信息的搜索、删除或爬取数据等操作。接着,在views.py中编写视图逻辑来处理前端请求,使用Django的URL路由(urls.py)将请求映射到相应的视图函数。对于数据的验证和序列化,可以使用Django的表单或序列化器来实现。在前端Vue.js部分,将创建相应的Vue组件,在这些组件中使用axios或其他HTTP库与Django后端的API进行交互,实现比赛信息的查看、编辑或删除等功能。状态管理可以通过Vuex来维护,比如在store目录下定义比赛信息模块的状态、突变、动作和获取器。如图所示:
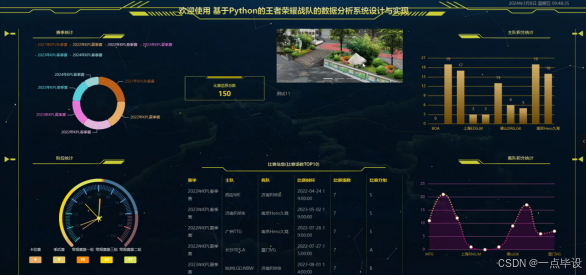
管理员进行爬取数据后,点击主页面右上角的看板,可以查看到系统简介、比赛信息总数、赛季统计、阶段统计、主队积分统计、客队积分统计、比赛信息等实时的分析图进行可视化管理;如图所示:
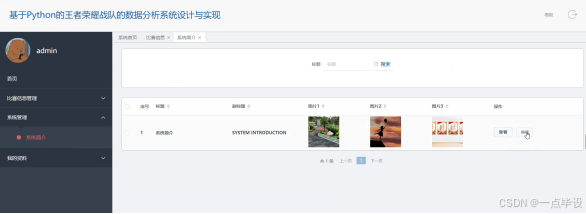
系统管理功能实现是在Django后端部分,您需要创建一个新的应用,然后在该应用下创建一个模型(models.py)来定义系统简介的数据结构,使用Django的ORM来处理与MySQL数据库的交互,包括系统简介的搜索操作。接着,在views.py中编写视图逻辑来处理前端请求,使用Django的URL路由(urls.py)将请求映射到相应的视图函数。对于数据的验证和序列化,可以使用Django的表单或序列化器来实现。在前端Vue.js部分,将创建相应的Vue组件,在这些组件中使用axios或其他HTTP库与Django后端的API进行交互,实现系统简介的查看或编辑功能。状态管理可以通过Vuex来维护,比如在store目录下定义系统管理模块的状态、突变、动作和获取器。如图所示:
六.部分功能代码
import scrapy
import pymysql
import pymssql
from ..items import xiangmuItem
import time
import re
import random
import platform
import json
import os
from urllib.parse import urlparse
import requests
import emoji
class xiangmuSpider(scrapy.Spider):
name = 'xiangmuSpider'
spiderUrl = 'https://url网址'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if plat == 'windows_bak':
pass
elif plat == 'linux' or plat == 'windows':
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'xiangmu') == 1:
cursor.close()
connect.close()
self.temp_data()
return
list = response.css('ul.subject-list li.subject-item')
for item in list:
fields = xiangmuItem()
fields["laiyuan"] = self.remove_html(item.css('div.pic a.nbg::attr(href)').extract_first())
if fields["laiyuan"].startswith('//'):
fields["laiyuan"] = self.protocol + ':' + fields["laiyuan"]
elif fields["laiyuan"].startswith('/'):
fields["laiyuan"] = self.protocol + '://' + self.hostname + fields["laiyuan"]
fields["fengmian"] = self.remove_html(item.css('div.pic a.nbg img::attr(src)').extract_first())
fields["xiaoshuoming"] = self.remove_html(item.css('div.info h2 a::attr(title)').extract_first())
detailUrlRule = item.css('div.pic a.nbg::attr(href)').extract_first()
if self.protocol in detailUrlRule:
pass
elif detailUrlRule.startswith('//'):
detailUrlRule = self.protocol + ':' + detailUrlRule
else:
detailUrlRule = self.protocol + '://' + self.hostname + detailUrlRule
fields["laiyuan"] = detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, callback=self.detail_parse)
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
try:
if '(.*?)' in '''div#info span a::text''':
fields["zuozhe"] = re.findall(r'''div#info span a::text''', response.text, re.S)[0].strip()
else:
if 'zuozhe' != 'xiangqing' and 'zuozhe' != 'detail' and 'zuozhe' != 'pinglun' and 'zuozhe' != 'zuofa':
fields["zuozhe"] = self.remove_html(response.css('''div#info span a::text''').extract_first())
else:
fields["zuozhe"] = emoji.demojize(response.css('''div#info span a::text''').extract_first())
except:
pass
# 去除多余html标签
def remove_html(self, html):
if html == None:
return ''
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html).strip()
# 数据库连接
def db_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
@main_bp.route("/python05c7298x/danchexinxi/save", methods=['POST'])
def python05c7298x_danchexinxi_save():
'''
'''
if request.method == 'POST':
msg = {"code": normal_code, "msg": "success", "data": {}}
req_dict = session.get("req_dict")
if danchexinxi.count(danchexinxi, danchexinxi, {"danchebianhao":req_dict["danchebianhao"]})>0:
msg['code'] = crud_error_code
msg['msg'] = "单车编号已存在"
return jsonify(msg)
for key in req_dict:
if req_dict[key] == '':
req_dict[key] = None
error= danchexinxi.createbyreq(danchexinxi, danchexinxi, req_dict)
if error!=None:
msg['code'] = crud_error_code
msg['msg'] = error
return jsonify(msg)
为什么选择我们
大学毕业那年,曾经有幸协助指导老师做过毕业设计课题分类、论文初选(查看论文的格式)、代码刻录等打杂的事情,也帮助过同界N多同学完成过毕业设计工作,毕业后在一家互联网大厂工作8年,先后从事Java前后端开发、系统架构设计等方面的工作,有丰富的编程能力和水平,也在工作之余指导过别人完成过一些毕业设计的工作。2016年至今,团队已指导上万名学生顺利通过毕业答辩,目前是csdn特邀作者、CSDN全栈领域优质创作者,博客之星、掘金/华为云/B站/知乎等平台优质作者,计算机毕设实战导师,专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎咨询~✌
最后
💕💕
最新计算机毕业设计选题篇-选题推荐
小程序毕业设计精品项目案例-200套
Java毕业设计精品项目案例-200套
Python毕业设计精品项目案例-200套
大数据毕业设计精品项目案例-200套
💟💟如果大家有任何疑虑,欢迎在下方位置详细交流。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











