







深度求索(DeepSeek)的模型和框架通常基于主流深度学习框架(如PyTorch、TensorFlow),其与GPU服务器的适配性主要取决于硬件架构、驱动支持、计算库版本以及软件环境配置。以下是不同型号GPU服务器的适配情况及关键注意事项:
一、适配核心原则
1. GPU架构支持
- 需支持NVIDIA CUDA(主流选择)或AMD ROCm(需框架兼容)。
- NVIDIA GPU:推荐Ampere架构(A100、A30)、Hopper架构(H100)或Ada Lovelace架构(RTX 4090)等。
- AMD GPU:需确认框架是否支持ROCm(如PyTorch ROCm版本)。
2. 显存容量
- 模型参数量越大,显存需求越高:
- 10B以下参数模型:24GB显存(如RTX 3090/4090);
- 10B~100B参数模型:需多卡并行(如A100 80GB)。
- 大模型训练需关注显存带宽(如HBM2e)。
3. 软件依赖
- CUDA/cuDNN版本需与深度学习框架匹配(如PyTorch 2.0+要求CUDA 11.7+)。
- 操作系统建议使用Linux(Ubuntu/CentOS)。
二、主流NVIDIA GPU型号适配情况
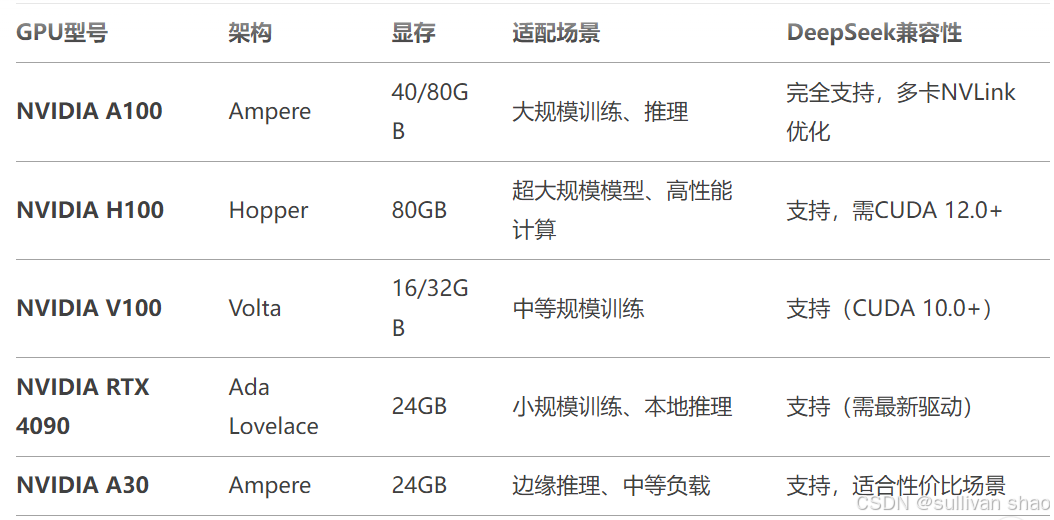
- A100/H100:适合企业级服务器(如DGX系统),支持多卡NVLink互联,显存带宽高(2TB/s)。
- 消费级显卡(RTX 3090/4090):适合预算有限的场景,但需注意显存容量和散热。
- 老旧型号(如T4/P40):可支持推理,但训练效率较低。
三、GPU服务器品牌与型号推荐
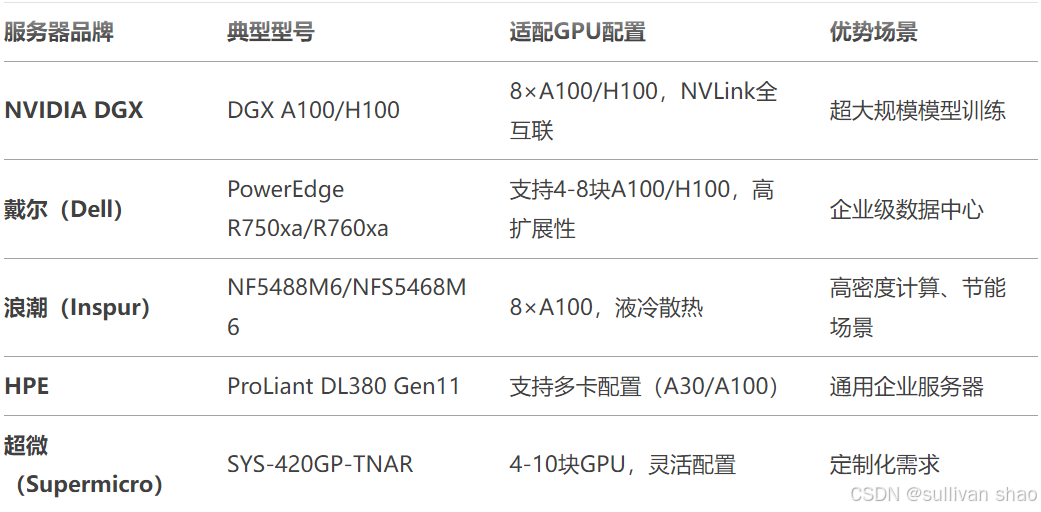
1. 计算密度:高密度服务器(如DGX)适合集中训练,通用服务器(Dell/HPE)适合混合负载。
2. 散热与供电:
- A100/H100单卡功耗300W-700W,需服务器支持冗余电源(如2000W+)和高效散热(液冷/风冷)。
3. 扩展性:PCIe 4.0/5.0接口确保GPU带宽(避免瓶颈)。
四、软件环境配置
1. 基础依赖
- 操作系统:Ubuntu 20.04/22.04 LTS(对NVIDIA驱动兼容性最佳)。
- 驱动版本:NVIDIA Driver 535+(需匹配CUDA版本)。
- CUDA Toolkit:建议CUDA 11.8或12.x(H100需CUDA 12+)。
2. 框架支持
- PyTorch:官方预编译版本支持主流GPU(`conda install pytorch torchvision torchaudio cudatoolkit=11.8`)。
- TensorFlow:需通过`tf.test.is_gpu_available()`验证兼容性。
3. 容器化部署
- 使用NVIDIA NGC容器(如`nvcr.io/nvidia/pytorch:23.10-py3`)可快速部署环境。
五、验证与优化建议
1. 兼容性测试
- 运行`nvidia-smi`确认GPU识别。
- 执行深度学习框架的GPU检测代码(如PyTorch的`torch.cuda.is_available()`)。
2. 性能调优
- 多卡训练:使用`DeepSpeed`或`Horovod`优化分布式训练。
- 显存优化:启用混合精度训练(AMP)、梯度检查点(Gradient Checkpointing)。
3. 监控工具
- NVIDIA DCGM:实时监控GPU利用率、显存占用。
- Prometheus+Grafana:可视化集群性能。
六、特殊场景注意事项
1. 国产GPU(如华为昇腾、寒武纪)
- 需使用定制化框架(如昇腾的CANN),可能需修改DeepSeek代码。
2. 云服务器(AWS/GCP/AliCloud)
- 选择GPU实例(如AWS p4d/p5,阿里云GN7/GN10)时,需确认虚拟化驱动支持。
总结
- 优先选择NVIDIA A100/H100:适配性最佳,性能稳定。
- 服务器品牌:根据预算和扩展需求选择戴尔、浪潮或NVIDIA DGX。
- 验证步骤:务必测试驱动、CUDA、框架的兼容性,避免部署失败。
示例配置:
- 训练场景:浪潮NF5488M6(8×A100 80GB + NVLink) + Ubuntu 22.04 + CUDA 12.1 + PyTorch 2.1。
- 推理场景:Dell PowerEdge R760xa(4×RTX 4090) + Docker + Triton推理服务器。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









