







应用场景
- 单机软件的搜索
- 站内搜索
通常用于在大量数据出现的系统中,找出你想要的资料。常见的有
baidu贴吧、商品网站的搜索等、中关村在线 商品的名称、电脑硬件名称 (CPU)、文件管理系统、对文件的搜索功能。Window的文件搜索 - 垂直领域的搜索
针对 某个行业的搜索引擎
搜索引擎的细分和延伸
针对网页库中的专门信息的整合
其特点是专、深、精,并具有行业色彩
可以应用于购物搜索、房产搜索、人才搜索 - 专业搜索引擎公司
优点
- 所有的问题都通过一个额外抽象层来方便以后的扩展和重用:你可以通过重新实现来达到自己的目的,而对其他模块而不需要;
- 简单的应用入口Searcher, Indexer,并调用底层一系列组件协同的完成搜索任务;
- 所有的对象的任务都非常专一:比如搜索过程:QueryParser分析将查询语句转换成一系列的精确查询的组合(Query),通过底层的索引读取结构IndexReader进行索引的读取,并用相应的打分器给搜索结果进行打分/排序等。所有的功能模块原子化程度非常高,因此可以通过重新实现而不需要修改其他模块。
- 除了灵活的应用接口设计,Lucene还提供了一些适合大多数应用的语言分析器实现(SimpleAnalyser,StandardAnalyser),这也是新用户能够很快上手的重要原因之一。
缺点
- Lucene的搜索算法不适用于网格计算
- 封闭设计的API使得扩展Lucene变得很困难
- Lucene的结构设计不好;Lucene的OO设计的非常糟,尽管有包package和类class,但是Lucene的设计基本上没有设计模式的身影。这是不是c或者c++程序员写java程序的通病?
A、Lucene中没有使用接口Interface,比如Query 类( BooleanQuery, SpanQuery, TermQuery…) 大都是从超类中继承下来的;
B、Lucene的迭代实现不自然: 没有hasNext() 方法, next() 返回一个布尔值 boolean然后刷新对象的上下文; - 排序算法的实现不是可插拔的,因为贯穿Lucene的排序算法的tf/idf 的实现,尽管term是可以设置boost或者扩展Lucene的Query类,但是对于复杂的排序算法定制还是有很大的局限性;
- 区间范围搜索速度非常缓慢;
Lucene的区间范围搜索,不是一开始就提供的是后来才加上的。对于在单个文档中term出现比较多的情况,搜索速度会变得很慢。因此作者称Lucene是一个高效的全文搜索引擎,其高效仅限于提供基本布尔查询 boolean queries; - Lucene 的内建不支持群集。
Lucene是作为嵌入式的工具包的形式出现的,在核心代码上没有提供对群集的支持。实现对Lucene的群集有三种方式:1、继承实现一个 Directory;2、使用Solr 3、使用 Nutch+Hadoop;使用Solr你不得不用他的Index Server ,而使用Nutch你又不得不集成抓取的模块;
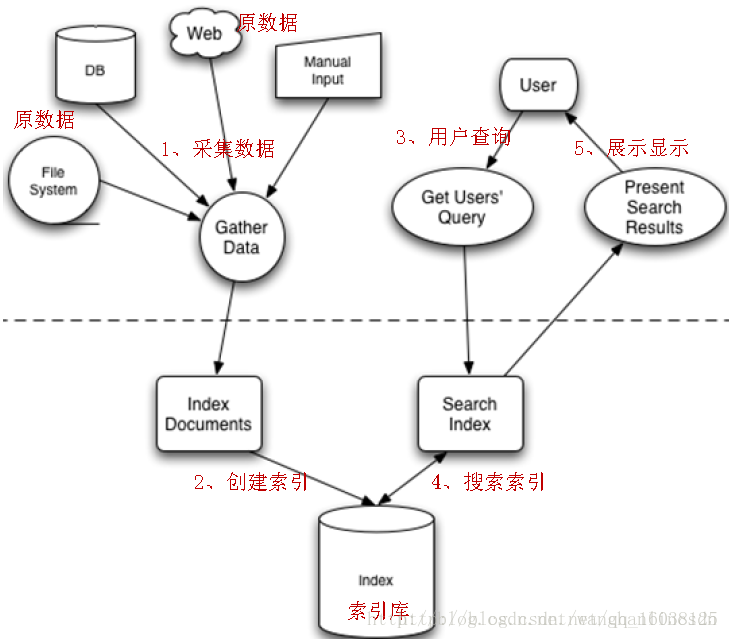
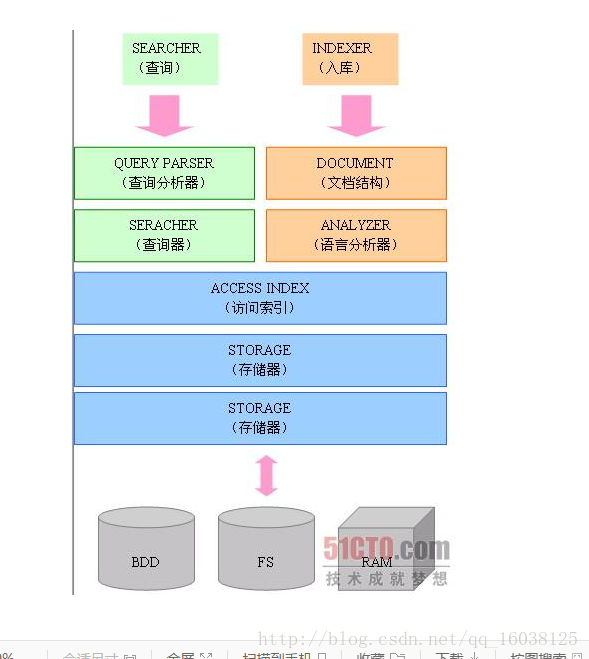
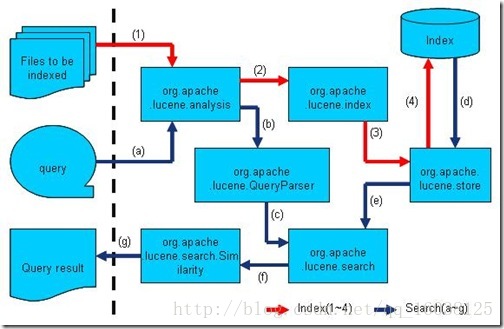

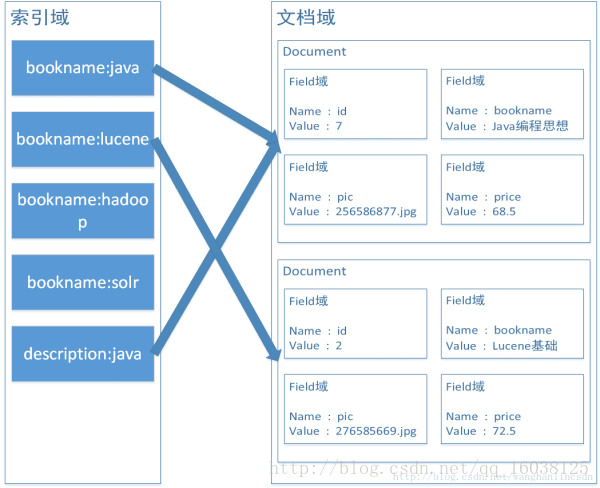
源码目录

参考站点:
http://www.chedong.com/tech/lucene.html
http://www.cnblogs.com/silence1133/articles/6306036.html















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









