







一、生产者原理
1、Producer消息发送过程
学习和了解Producer的message发送过程,咱们先看下图
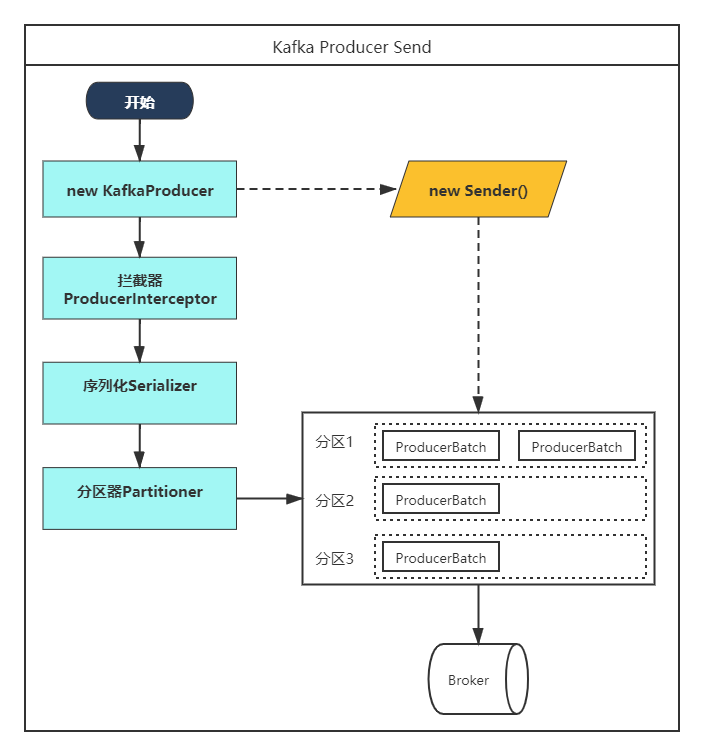
接下来,我们按照图中的步骤来分析Producer的message发送过程。
1.1、创建KafkaProducer
Prouducer主要由两个线程协调运行。一条是main线程;一条则为sender线程。
KafkaProducer<String,String> producer = new KafkaProducer<String,String>(pros);
在创建KafkaProducer的时候,同时创建sender对象,并且启动了一个IO线程,如下图kafka-clients-2.6.0.jar 源码。

1.2、拦截器ProducerIntercepetor
拦截器是在producer调用send方法中执行的,查看kafka-clients-2.6.0.jar 源码,我们在KafkaProducer.java中看到如下代码

这里的拦截器的作用类似AOP的使用,作用在发送消息的操作前后。
接下来,我们来看看ProducerIntercepetor使用
- 实现
org.apache.kafka.clients.producer.ProducerInterceptor接口,并实现方法。 - 在使用的时候配置
interceptor.classes参数。
使用实例
创建拦截器
public class TestInterceptor implements ProducerInterceptor<String, String> {
// 发送消息前的时候触发
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
System.out.println("消息即将发送!!!!");
return record;
}
// 收到服务端的ACK的时候触发
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
System.out.println("消息被服务端接收啦");
}
// 生产者关闭触发
@Override
public void close() {
System.out.println("生产者关闭啦");
}
// 用键值对配置的时候触发
@Override
public void configure(Map<String, ?> configs) {
System.out.println("configure...");
}
}
调用时进行配置
Properties props=new Properties();
props.put("bootstrap.servers","127.0.0.1:9092");
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("acks","1");
// 添加拦截器
List<String> interceptors = new ArrayList<>();
interceptors.add("com.testkafka.interceptor.TestInterceptor");
// props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
props.put("interceptor.classes", interceptors);
Producer<String,String> producer = new KafkaProducer<String,String>(props);
producer.send(new ProducerRecord<String,String>("mytopic","1","1"));
1.3、序列化Serializer
在配置和使用完拦截器后,就开始对key和value进行系列化了。我们可以查看查看kafka-clients-2.6.0.jar 源码KafkaProducer.java中看到如下代码

kafka针对不同数据的序列化,提供了响应的序列化工具;
ByteArraySerializer
ByteBufferSerializer
BytesSerializer
DoubleSerializer
FloatSerializer
IntegerSerializer
LongSerializer
ShortSerializer
StringSerializer
UUIDSerializer
VoidSerializer
除了自带的序列化工具之外,可以使用如Avro、JSON、Thrift、Protobuf等,或者使用自定义类型的序列化器来实现,实现Serializer接口即可。
代码可参考连接
https://gitee.com/fanger8848/study/tree/master/kafka/kafka-api-test/src/main/java/com/fanger/serializer
1.4、路由指定(分区器)
序列化完成后就开始要指定消息的分区,查看kafka-clients-2.6.0.jar 源码,我们在KafkaProducer.java中看到如下代码

这里的partition()方法返回的是分区编号,从0开始。
一条消息会发送到哪个partition呢?
- 指定了partition;
- 没有指定partition,自定义了分区器;
- 没有指定partition,没有自定义分区器,但是key不为空;
- 没有指定partition,没有自定义分区器,但是key是空的。
接下来,我们来一种一种分析。
第一种情况:指定分区,这样他就会被发送到指定分区上。
第二种情况:没有指定partition,自定义了分区器。这时候通过自定义的分区器,得到分区编号。
自定义分区器需要实现org.apache.kafka.clients.producer.Partitioner类,并重写partition()方法。
并且Producer需要配置分区器路径
props.put("partitioner.class", "com.fanger.partition.SimplePartitioner");
第三种情况:没有指定partition,没有自定义分区器,但是key不为空。
没有指定partition值但有key的情况下,使用默认分区器DefaultPartitioner,将key的hash 值与topic的 partition 数进行取余得到partition值;
第四种情况:没有指定partition,没有自定义分区器,但是key是空的。
既没有partition值又没有key值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic可用的partition总数取余得到partition值,也就是常说的round-robin算法。
1.5、消息累加器
通过查询源码,我们可以知道,消息指定完分区以后,并没有立即发送出去。而是追叫到累加器RecordAccumulator中。

而消息累加器,实际上是ConcurrentMap,维护TopicPartition和 Deque之间的关系。
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;
当一个partition的ProducerBatch满了或者时间到了,就会唤醒Sender线程,发送消息。

2、服务端响应ACK
Producer可以通过配置acks,来设置服务端的应答策略。
acks=0,Broker接收到消息就返回(还未写入磁盘)。延迟最低,若Broker故障,丢数据的风险大。acks=1,等到Partition的leader落盘成功后返回ack,若follower同步成功之前,leader故障,会丢失数据。acks=-1,Partition的leader和follower全部落盘以后才返回ack。
这里涉及到Partition的leader和follower,后面在Broker的存储原理在聊!!
二、Broker的存储原理
1、文件存储结构

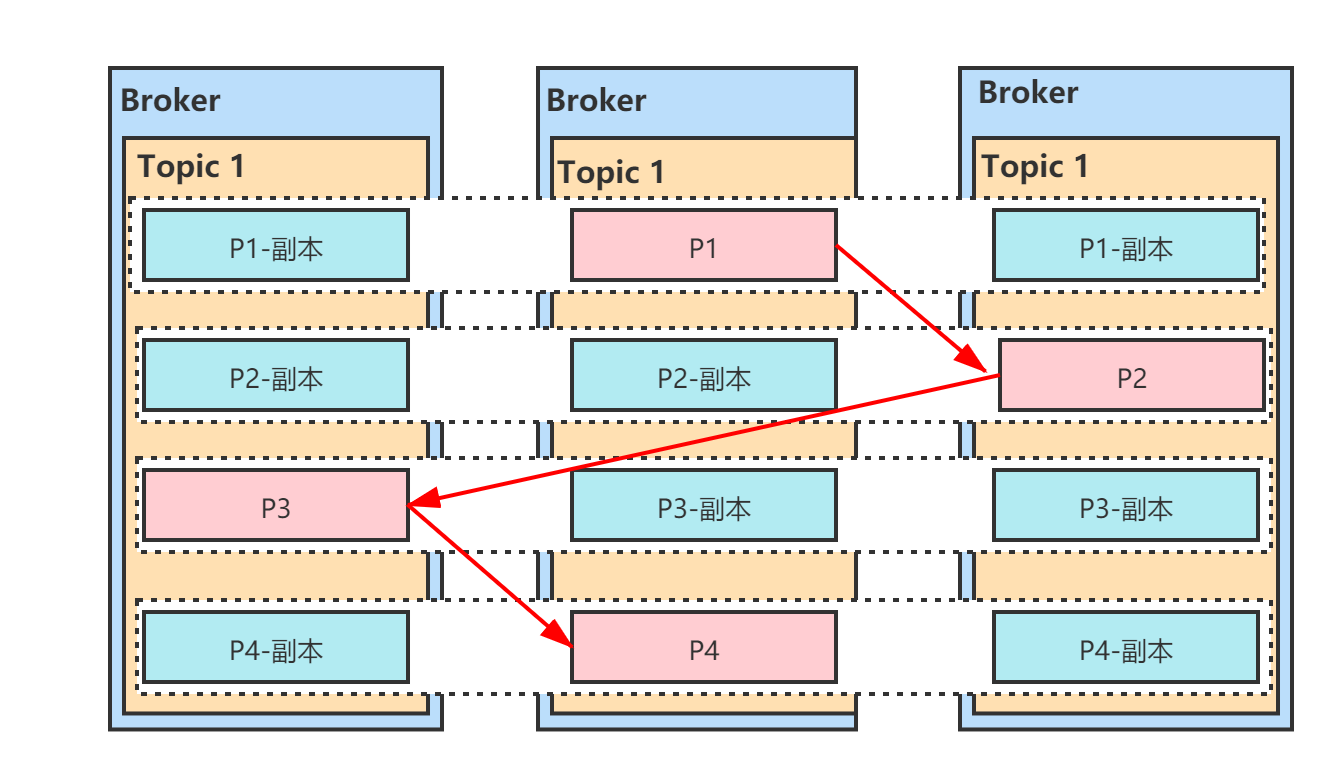
1.1、Broker存储模型分析
一个Topic是如何存储到多个Broker中的呢?由上图,我们可以知道,Topic 1分成了3个Partition分别是P1、P2、P3。
而且每个Partition还设置了2个副本。
上图中,红色背景的P1是Partition1的leader分区,蓝色背景的P1是follower分区。消费者读取数据只通过leader节点来进行,这样就避免了主从复制带来的数据一致性问题。
1.2、Replica副本的分布
1.2.1、如何查看副本分布情况
查看分区副本情况命令如下:
sh kafka-topics.sh --topic 3part3rep-1 --describe --zookeeper 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181;
查看结果如下图:

1.2.2、副本分布规则
- 首先,副本因子不能大于 Broker的个数;
- 第一个分区(编号为0的分区)的第一个副本放置位置是随机从 broker集合选择的;
- 其他分区的第一个副本放置位置相对于第0个分区依次往后移;举例:如果我们有5个 Broker,5个分区,假设第1个分区的第1个副本放在第四个 Broker 上,那么第2个分区的第1个副本将会放在第五个 Broker 上;第三个分区的第1个副本将会放在第一个 Broker 上;第四个分区的第1个副本将会放在第二Broker 上,依次类推;
- 每个分区剩余的副本相对于第1个副本放置位置其实是由
nextReplicaShift决定的,而这个数也是随机产生的。
一般第一个分区的第一个副本就是该分区的副本的leader。
1.3.segment分析
1.3.1、segment文件结构分析
为了防止log 不断追加导致文件过大,导致检索消息效率变低,一个partition又被划分成多个segment来存储数据(MySQL 也有segment的逻辑概念
叶子节点就是数据段,非叶子节点就是索引段)。
每个partition里面文件都有如下图中的一套文件(3个):

.log文件就是存储消息的文件。.index是偏移量(offset)索引文件。.timeindex是时间戳(timestamp)索引文件。
.log文件在消息发送不断追加数据的过程中,满足一定的条件就会进行日志切分,产生一套新的segment文件。切分日志的条件如下:
第一种情况:根据.log文件的大小判断,可以通过如下参数控制,默认值是1073741824 byte (1G)
log.segment.bytes=1073741824
第二种情况:根据消息的最大时间戳,和当前系统时间戳的差值。可以通过如下参数控制,默认值168小时(一周)
log.roll.hours=168
# 可以用毫秒控制,参数如下
log.roll.ms
第三种情况:offset索引文件或者timestamp索引文件达到了一定的大小,默认是10485760字节(10M)。如果要减少日志文件的切分,可以把这个值调大一点。
log.index.size.max.bytes=10485760
1.3.2、偏移量(offset)索引文件
偏移量索引文件记录的是 offset和消息物理地址(在log文件中的位置)的映射关系。内容是二级制文件。可以通过如下命令查看
./kafka-dump-log.sh --files /tmp/kafka-logs/topic1-0/00000000000000000000.index|head -n 10
查询内容如下:
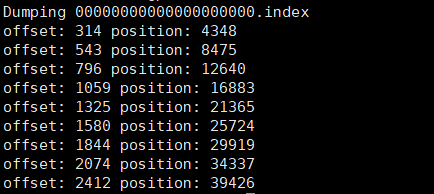
注意kafka的索引并不是每一条消息都会建立索引,而是一种稀疏索引sparse index。稀疏索引结构如下图所示
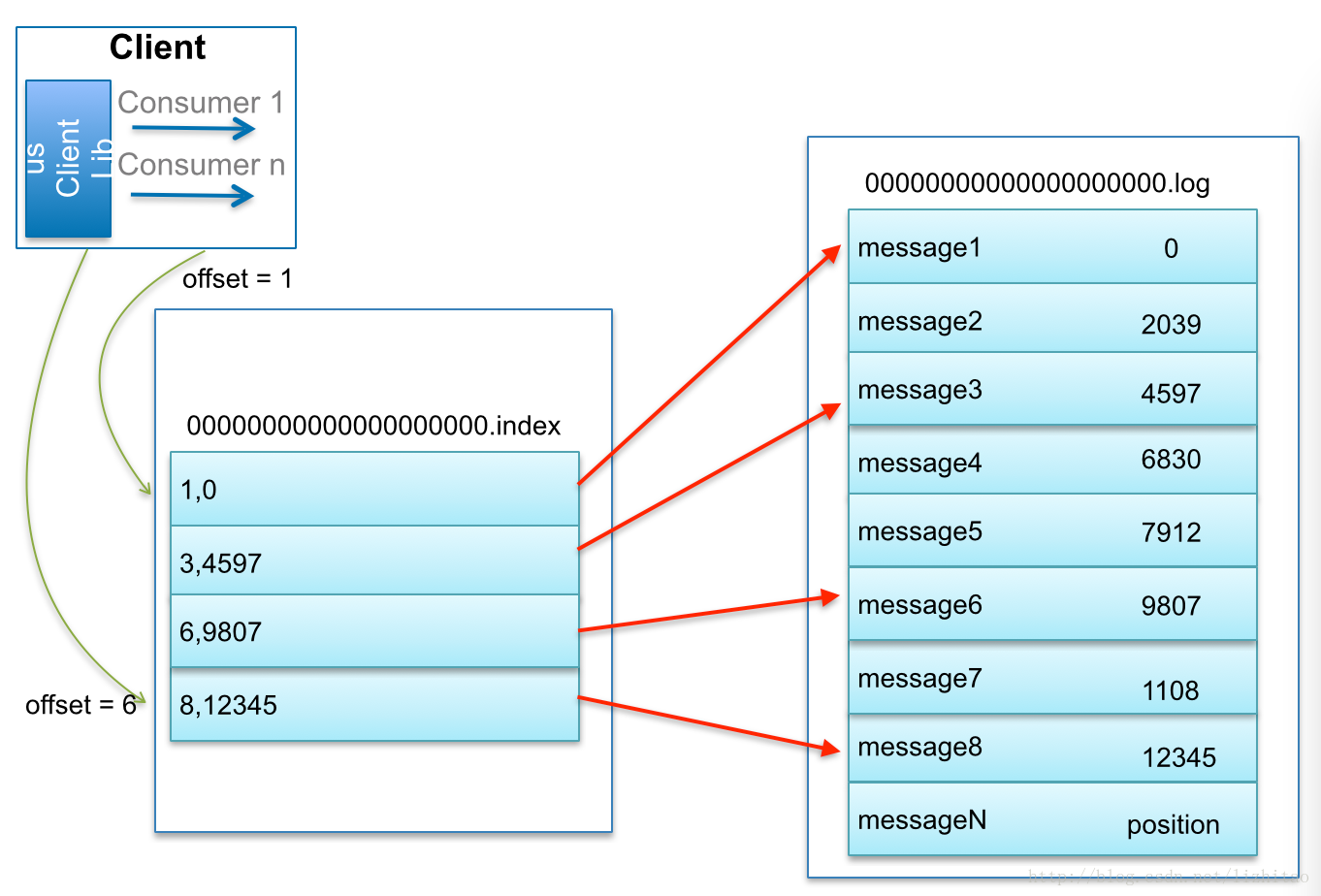
稀疏索引的稀疏程度,是怎么来确定的呢?
偏移量索引的稀疏程度是有中间间隔消息的大小来确定,默认是4KB,可以由下面的参数控制
log.index.interval.bytes=4096
只要写入消息超过4K,则偏移量索引增加一条记录。
1.3.3、时间戳索引文件
时间戳索引有两种,一种是消息创建的时间戳,一种是消费在Broker追加写入的时间。到底用哪个时间呢?由一个参数来控制:
log.message.timestamp.type=CreateTime或LogAppendTime
# 默认是消息创建时间(CreateTime),LogAppendTime是日志追加时间
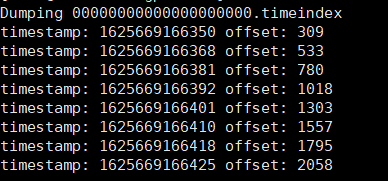
查看最早的10条时间戳索引,命令入如下:
./kafka-dump-log.sh --files /tmp/kafka-logs/topic1-0/00000000000000000000.timeindex|head -n 10
查看结果如下,这里记录的是时间和偏移量之间的映射关系
1.3.4、如何快速的检索到消息呢?
比如我要检索偏移量是10002673的消息。
- 消费的时候是能够确定分区的,所以第一步是找到在哪个segment 中。Segment文件是用base offset命名的,所以可以用二分法很快确定(找到名字不小于10002673的segment)。
- 这个segment有对应的索引文件,它们是成套出现的。所以现在要在索引文件中根据offset找position。
- 得到position之后,到对应的log文件开始查找offset,和消息的 offset进行比较,直到找到消息
1.4、总结

2、消息保留(清除)机制
2.1、开关和策略
是否开启消息清除机制可以通过如下参数配置
log.cleaner.enbable=true
kafka中提供了两种清除策略:
- 直接删除delete
- 日志压缩的compact
默认是直接删除,可配置
log.cleanup.policy=delete
2.2、直接删除(delete)策略
log.retention.check.interval.ms,该参数用来设置每次日志删除的间隔时间,默认是5分钟。
log.retention.hours,该参数设置一个时间(默认值168小时),消息保存时间超过该时间时,则被定义为需要删除的消息。也可以通过分钟或者毫秒来设置,参数为log.retention.minutes(默认为空)和log.retention.ms(默认为空)。
log.retention.bytes,该参数设置一个日志文件大小(所有segment文件大小),超过这个文件大小阈值,开始进行删除日志任务。默认值-1,不限制文件大小。
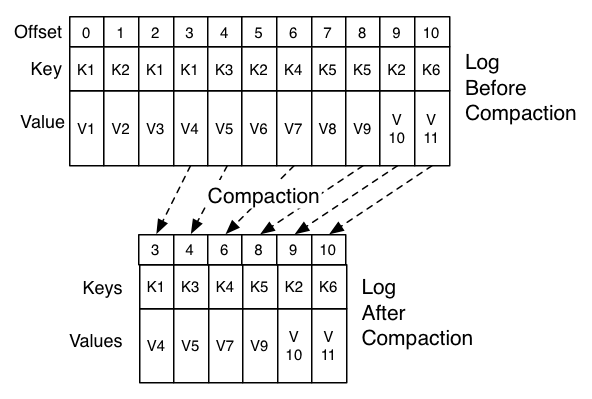
2.3、压缩策略(compact)
压缩就是把相同的key合并为最后一个value。如下图可知
3、高可用原理
3.1、Controller选举
首先,Controller是干啥的,Controller是从Broker中选举出来一个节点,主要任务如下
- 监听Broker的变化
- 监听Topic的变化
- 监听Partition的变化
- 获取和管理Broker、Partition、Topic的信息
- 管理Partition的主从信息
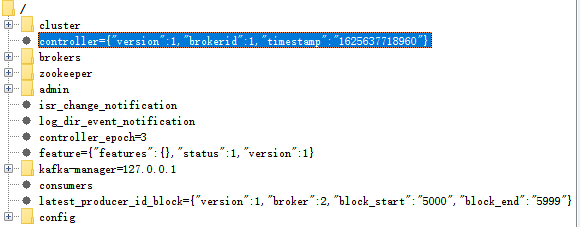
Controller是如选出来的呢?
所有的Broker启动时会尝试在ZK中创建临时节点/controller,只有一个能创建成功(先到先得)。如果Controller挂掉了或者网络出现了问题,ZK上的临时节点会消失。其他的Broker通过watch监听到Controller下线的消息后,开始竞选新的Controller。方法跟之前还是一样的,谁先在ZK里面写入一个/controller节点,谁就成为新的Controller。
3.2、分区副本leader选举
有了Controller的Broker节点,就可以进行分区副本的leader的选举了。这里需要知道如下几个概念
-
Assigned-Replicas (AR):是一个分区所有的副本。所有的皇太子;
-
In-Sync Replicas(ISR) :是这些所有的副本中,跟leader 数据保持一定程度同步的。天天过来参加早会的,有希望继位的皇太子。
-
Out-Sync-Replicas (OSR):是跟leader同步滞后过多的副本。天天睡懒觉,不参加早会,没被皇帝放在眼里的皇太子。
AR=ISR+OSR。正常情况下OSR是空的,大家都正常同步,AR=ISR。如果同步延迟超过30秒,就踢出ISR,进入OSR;如果赶上来了,就加入ISR。
leader副本如何选举呢?
这里是选举通过Controller来主持,使用微软的PacificA算法。在这种算法中,默认是让ISR中第一个replica变成leader。比如ISR是1、5、9,优先让1成为leader。
分布式系统中常见的选举协议有哪些(或者说共识算法)?
ZAB (ZK)、 Raft (Redis Sentinel)(他们都是Paxos 算法的变种),它们的思想归纳起来都是:先到先得、少数服从多数。
3.3、分区副本同步机制
3.3.1、副本同步机制
leader副本选举成功以后,就需要把数据同步给备份的的副本。follower是怎么想leader同步数据的呢?
首先我需要学习几个概念,如下图所示

- Hight Watermark:副本水位值,表示分区中最新一条已提交(Committed)的消息的Offset。
- LEO:Log End Offset,Leader中最新消息的Offset。
- Committed Message:已提交消息,已经被所有ISR同步的消息。
- Lagging Message:没有达到所有ISR同步的消息。
数据同步过程是什么样的呢?
- follower节点会向Leader发送一个fetch请求,leader向follower’发送数据后,既需要更新follower的 LEO。
- follower接收到数据响应后,依次写入消息并且更新LEO。
- leader更新HW (ISR最小的LEO)。
注意,消费者只能消费在HW的数据。kafka设计了独特的ISR复制,可以在保障数据一致性情况下又可提供高吞吐量。
3.3.2、follower故障
如果follower发生了故障,会进行如下步骤的操作
- follower被提出ISR。
- follower回复以后,根据之前记录的HW,把高于HW的数据删除。
- 然后同步leader的数据,知道追上leader,重新加入ISR。
3.3.3、leader故障
如果leader发生了故障,会进行如下步骤的操作
- leader被提出ISR,Controller重新选举一个leader出来。
- 其他follower删除高于HW的消息,然后同步leader的数据。
注意,这种机制只能保证数据的一致性,不能保证数据的丢失和重复。
三、消费者原理
1、Offset的维护
消费者的消费信息是存储在_consumer_offset的Topic中的。主要存储两个对象:
- GroupMetadata:保存了消费者组中各个消费者的信息(每个消费者有编号)。
- OffsetAndMetadata:保存了消费者组和各个partition的offset位移信息元数据。
如果消费者加入消费者组后,找不到offset怎么办?
在消费者参数配置中有auto.offset.reset, 可以有如下的选项
- latest,也就是从最新的消息(最后发送的)开始消费的。历史消费是不能消费的。
- earliest,代表从最早的(最先发送的)消息开始消费。可以消费到历史消息。
- none,如果 consumer group在服务端找不到offset 会报错。
_consumer_offset中的数据是什么时候更新呢?
更新consumer_offset需要消费者commit以后,才会更新。可以配置下面的参数,选择是手动更新还是自动更新
# 默认是true。true代表消费者消费消息以后自动提交此时Broker 会更新消费者组的offset。
enable.auto.commit
# 可以使用这个参数来控制提交的频率,默认是5秒
auto.commit.interval.ms
如果设置成手动提交话,可以有如下的方式
// 方式一:手动同步提交
consumer.commitSync();
// 方式二:手动异步提交
consumer.commitAsync();
如果不提交或者提交失败,Broker的 offset不会更新,消费者组下次消费的时候会消费到重复的消息。
2、消费策略(消费者和分区关系)

由上图可以看出,kafka给出了3中处理消费者和分区关系的方法:
- RangeAssignor (默认策略):按照范围连续分配。
- RoundRobinAssignor :轮询分配。
- StickyAssignor (粘滞)∶这种策略复杂一点,但是相对来说均匀一点(每次的结果都可能不一样)。原则:1)分区的分配尽可能的均匀;2)分区的分配尽可能和上次分配保持相同。
策略的选择使用,可以通过在消费者,配置如下参数进行选择:
prop.put("partition.assignment.strategy","org.apache.kafka.clients.consumer.RoundRobinAssignor");
3、分区重分配原理
有两种情况需要重新分配分区和消费者的关系:
-
消费者组的消费者数量发生变化,比如新增了消费者;
-
Topic的分区数发生变更,新增或者减少。
为了让分区分配尽量地均衡,这个时候会触发rebalance机制。
- 找一个话事人,它起到一个监督和保证公平的作用。每个Broker上都有一个用来管理offset、消费者组的实例,叫做GroupCoordinator。第一步就是要从所有GroupCoordinator 中找一个话事人出来。
- 第二步,清点一下人数。所有的消费者连接到GroupCoordinator报数,这个叫join group请求。
- 第三步,选组长,GroupCoordinator从所有消费者里面选一个leader。这个消费者会根据消费者的情况和设置的策略,确定一个方案。Leader把方案上报给GroupCoordinator,GroupCoordinator 会通知所有消费者。
四、Kafka为什么这么快?
1、总结原因如下:
- 磁盘顺序写(数据)
- 零拷贝 (读数据)
- 文件索引(segment的
.index、.timeindex) - 消息批量读写和压缩,减少网络IO的损耗。
五、保证Kafka消息不丢失的配置
- producer端使用
producer.send(msg, callback)带有回调的send方法,而不是producer.send(msg)方法。根据回调,一旦出现消息提交失败的情况,就可以有针对性地进行处理。 - 设置
acks = all。acks是Producer的一个参数,代表“已提交”消息的定义。如果设置成 all,则表明所有Broker都要接收到消息,该消息才算是“已提交”。 - 设置
retries为一个较大的值。同样是Producer的参数。当出现网络抖动时,消息发送可能会失败,此时配置了retries的 Producer能够自动重试发送消息,尽量避免消息丢失。 - 设置
unclean.leader.election.enable= false。 - 设置
replication.factor > = 3。需要三个以上的副本。 - 设置
min.insync.replicas > 1。Broker端参数,控制消息至少要被写入到多少个副本才算是“已提交”。设置成大于1可以提升消息持久性。在生产环境中不要使用默认值1。确保replication.factor > min.insync.replicas。如果两者相等,那么只要有一个副本离线,整个分区就无法正常工作了。推荐设置成replication.factor=min.insync.replicas + 1。 - 确保消息消费完成再提交。Consumer端有个参数
enable.auto.commit,最好设置成false,并自己来处理offset的提交更新。















 3530
3530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









