







主成分分析(Principal Component Analysis,PCA)是最常用的一种数据降维方法。顾名思义,PCA就是找出原始数据中最主要的方面来表示原始数据,可以获得比原始输入维度更低的表示。具体来说,假设原始数据 X={x(1),x(2),…,x(m)} X = { x ( 1 ) , x ( 2 ) , … , x ( m ) } , x(i) x ( i ) 是 d d 维向量,我们现在希望将每个样本从 d d 维降到维( d′<d d ′ < d ),并且希望新的 d′ d ′ 维数据能尽可能代表原始数据。显然,数据降维之后肯定会有数据损失,如何将这个损失降到最小就是PCA要解决的问题了。
1. PCA的直观理解
我们不妨先考虑这样一个问题:对于正交属性空间中的样本点,如何用一个超平面对所有样本进行恰当的表达?
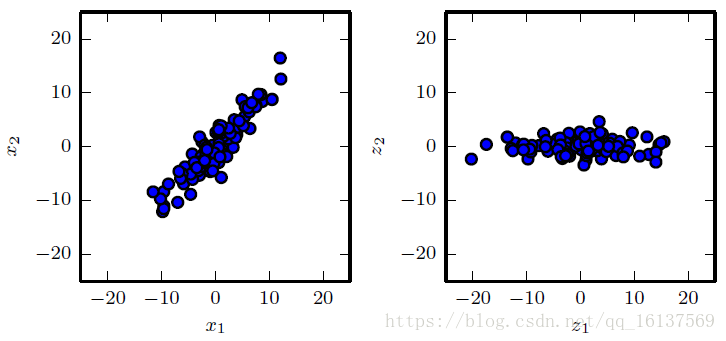
首先我们要明确什么叫做“恰当的表达”。以上图为例,左图中的二维数据中样本几乎都是沿着
x2=x1
x
2
=
x
1
方向分布,
x1
x
1
和
x2
x
2
存在着很明显的相关性,样本点在
x1
x
1
和
x2
x
2
两个方向变化幅度相当,所以如果要区分各个样本点,
x1
x
1
和
x2
x
2
缺一不可,缺少其中一个都有可能出现丢失大量数据的情况。如果我们将原始坐标系旋转
45∘
45
∘
,得到右图坐标系
(z1,z2)
(
z
1
,
z
2
)
,现在样本点几乎沿着
z1
z
1
方向分布了,在
z2
z
2
方向不同样本点几乎没有差别,因此去掉
z2
z
2
也影响不大。这里
z1
z
1
其实就对应这数据的第一个主要成分,我们用
z1
z
1
就能表达绝大部分数据。
然后再回到本节开始的问题,如果存在这样的超平面,那么它大概存在什么样的性质呢?从上图中的例子我们归纳:
(1) 最近重构性:样本点到这个超平面的距离都足够近
(2) 最大可分性:样本点在这个超平面上的投影能尽可能分开
其实用一句话总结就是,PCA学习了一种元素之间彼此没有线性相关的表示。从上图中也可以看出,相比
(x1,x2)
(
x
1
,
x
2
)
坐标系表达,
(z1,z2)
(
z
1
,
z
2
)
坐标系两个轴的相关性明显低得多甚至可以忽略。基于上面的最近重构性和最大可分性,可以得到PCA两种不同的等价推导。
2. PCA推导
假设 m m 个维数据 (x(1),x(2),…,x(m)) ( x ( 1 ) , x ( 2 ) , … , x ( m ) ) 都已经进行了中心化,即 ∑mi=1x(i)=0 ∑ i = 1 m x ( i ) = 0 。经过投影变换后得到的新坐标系为 {w1,w2,…,wd} { w 1 , w 2 , … , w d } ,其中 wi w i 是标准正交基, ∥wi∥2=1,wTiwj=0(i≠j) ‖ w i ‖ 2 = 1 , w i T w j = 0 ( i ≠ j ) 。如果我们将数据从 d d 维降到维,即丢弃新坐标系中的部分坐标,则样本点 x(i) x ( i ) 在新坐标系中的投影为 z(i)=(z(i)1,z(i)2,…,z(i)d′) z ( i ) = ( z 1 ( i ) , z 2 ( i ) , … , z d ′ ( i ) ) ,其中 z(i)j=wTjx(i) z j ( i ) = w j T x ( i ) 是 x(i) x ( i ) 在低维新坐标系下第 j j 维的坐标。那么新坐标和旧坐标 x(i) x ( i ) 的映射关系为
最近重构性推导
最近重构性是指样本点到这个超平面的距离足够近,即通过主成分重构得到的 x^(i) x ^ ( i ) 和原始样本点 x(i) x ( i ) 的距离尽可能小。也可以从另外一个角度理解:降维后的数据要尽可能接近原始数据。考虑整个训练集,重构得到的 x^(i) x ^ ( i ) 和原始样本点 x(i) x ( i ) 的距离平方和为
最大可分性推导
下面再来看一下最大可分性怎么推导出PCA。样本点在超平面上投影尽可能分开等价于投影后样本点的方差最大化。投影后样本点的方差为 ∑mi=1WTx(i)x(i)TW ∑ i = 1 m W T x ( i ) x ( i ) T W ,于是优化目标可以写为
3. PCA算法流程
先梳理一下PCA的算法流程,然后最后再来讨论一下PCA的性质。
假设原始数据
X={x(1),x(2),…,x(m)}
X
=
{
x
(
1
)
,
x
(
2
)
,
…
,
x
(
m
)
}
,
x(i)
x
(
i
)
是
d
d
维向量,我们现在希望将每个样本从
d
d
维降到维(
d′<d
d
′
<
d
)。
输入:
d
d
维数据集,要降到的维数
d′
d
′
输出:降维后的数据集
X′
X
′
Step1: 对所有样本进行中心化
Step3: 对协方差矩阵 XTX X T X 进行特征值分解/奇异值分解,得到特征值 λi λ i 及其对应的特征向量 wi w i , i=1,2,…,d i = 1 , 2 , … , d ;
Step4: 取前 d′ d ′ 大个特征值对应的特征向量 (w1,w2,…,wd′) ( w 1 , w 2 , … , w d ′ ) ,标准化后构成特征向量矩阵 W W ;
Step5: 根据特征向量矩阵计算出原始数据 x(i) x ( i ) 在特征空间中的投影 z(i) z ( i ) :
关于低维空间维度 d′ d ′ 的选择,通常情况下是用户事先指定的;或对不同 d′ d ′ 进行交叉验证然后选择最优的;或设置一个重构阈值 t t ,然后选取使下式成立的最小值:
4. PCA的性质
- PCA降维舍弃的这部分信息往往是必要的:一方面,舍弃这部分信息之后能使样本的采样密度增大,这正是降维的重要动机;另一方面,当数据受噪声影响时,最小的特征值所对应的特征向量往往和噪声有关,舍弃它们在一定程度上有去噪的效果。
- PCA另一个重要特性是能将数据变换为元素之间彼此不想关的表示,可以消除数据中未知变化因素。所以PCA也是一种数据白化的技术。
- 由 z(i)=WTx(i) z ( i ) = W T x ( i ) 可知,高维空间到低维空间的函数映射是线性的,但是在许多现实任务中,可能需要非线性映射才能找到恰当的低维嵌入。这时我们可以用SVM中提到的核技巧来引入非线性。
















 46万+
46万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











