







 IXI MEGA声卡系列提供多种功能,适用于直播、音乐制作、室外演出等场景。本文将详细介绍M4、M6、M8、PIUS、M2、M-NU2和M-NU4的安装调试步骤,包括下载对应驱动、配置缓冲区大小、跳线设置,以及在Studio One等宿主机中的音频和输入输出设置。通过教程视频,帮助用户快速掌握声卡的使用技巧。
IXI MEGA声卡系列提供多种功能,适用于直播、音乐制作、室外演出等场景。本文将详细介绍M4、M6、M8、PIUS、M2、M-NU2和M-NU4的安装调试步骤,包括下载对应驱动、配置缓冲区大小、跳线设置,以及在Studio One等宿主机中的音频和输入输出设置。通过教程视频,帮助用户快速掌握声卡的使用技巧。
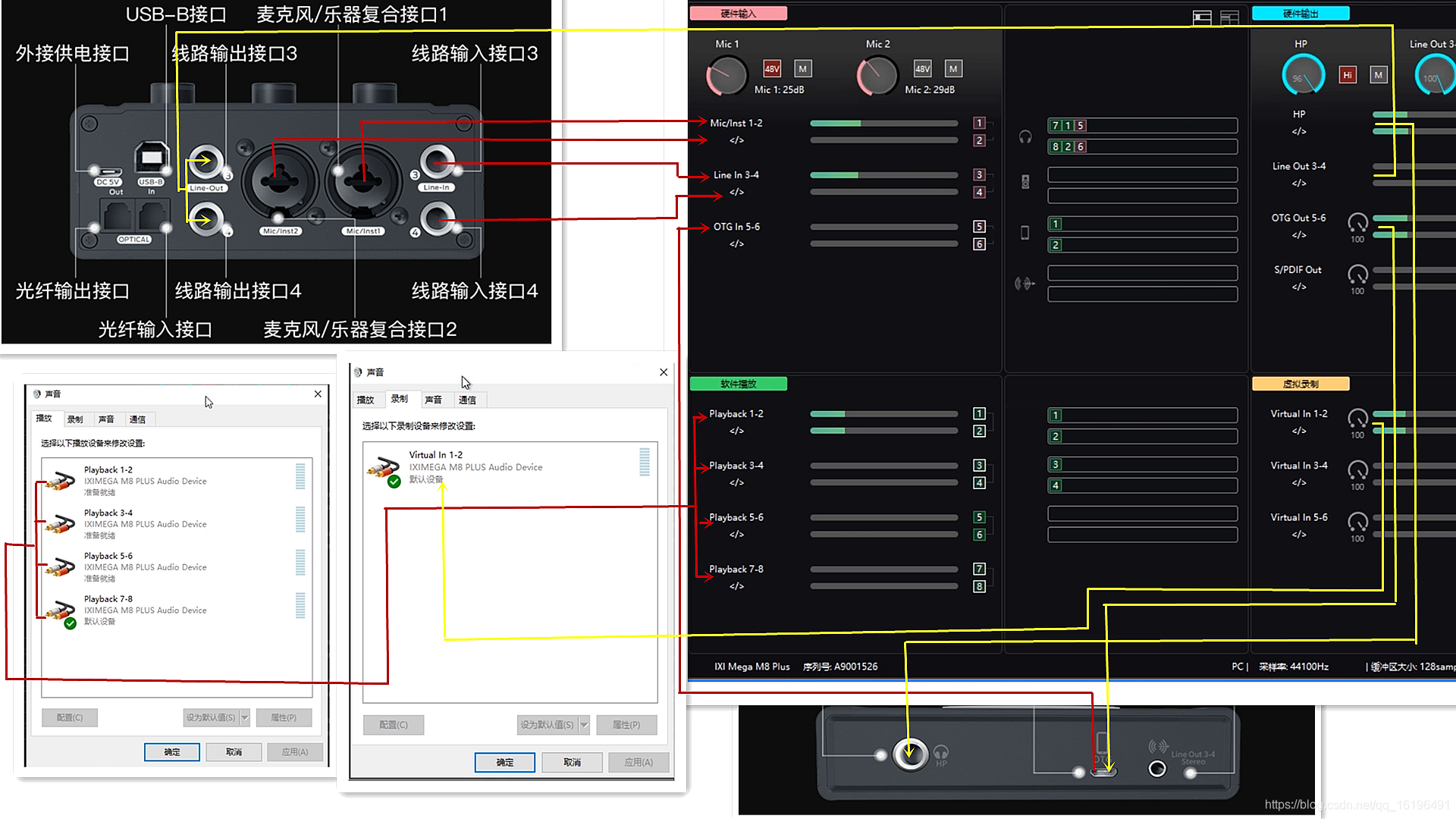
IXI MEGA声卡系列产自新加坡,主要型号有M4 plus m6 plus m8 plus m2 m-nu2 m-nu4等。它的囊括了多种功能以及用途;比如直播,电脑安装声卡驱动以后,搭载机架宿主,可以电脑直播,因为它有多个虚拟播放通道以及录制通道,可以将人声,乐器,电脑音乐等声音直播出去。也可以用于音乐后期制作,室外演出,录音棚录音等,而且声卡有无损音质的手机输入,输出接口,还有耳机无线发送信号,麦克风支持48v供电,耳机高阻抗等功能。性能超级稳定,声音失真小,核心处理器强大,跳线简洁方便。性价比高,等多种优点集与一身。是一款不可多得的声卡。下面简单明了的说一下IXI MEGA声卡系列的安装调试流程以及效果演示。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9251
9251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









