







HBase写数据架构图:
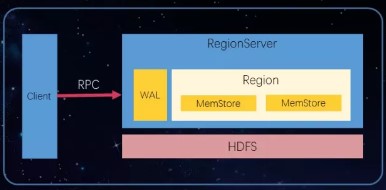
HBase写过程如下:
- 先将数据写到WAL中;
- WAL存放在HDFS上;
- 每次put、Delete操作的数据均追加到WAL末端;
- 持久化到WAL之后,再写到MemStore中;
- 两者写完返回ACK客户端。
MemStore其实是一种内存结构,一个Column Family对应一个MemStore,MemStore里边的数据也是对RowKey进行字典排序的,如下:

既然我们写数据都是先写WAL,再写MemStore,而MemStore是内存结构,所以MemStore总会写满的,将MemStore的数据从内存刷写到磁盘的操作称为flush;

以下几种行为会导致flush操作:
- 全局内存控制
- MemStore使用达到上限
- RegionServer的Hlog数量达到上限;
- 手动触发
- 关闭Region Server触发
每次flush操作都是将一个MemStore的数据写到一个HFile里面的,所以上图中HDFS上有许多个HFile文件。文件多了会对h后面的读操作有影响,所以HBase会隔一段时间将HFile合并。根据合并的范围不同分为Minor Compaction和Major Compaction:

Minor Compaction:指选取一些小的、相邻的HFile将他们合并成一个更大的HFile
Major Compaction:将一个column family下所有的HFile合并成更大的;删除那些标记为删除的数据、超过TTL(time-to-live)时限的数据,以及超过了版本数量限制的数据。
HBase读操作相对于写操作更为复杂,其需要读取BlockCache、MemStore以及HFile。

HBase表按照RowKey分布到集群的不同机器上,那么我们如何去确定我们该读哪些RegionServer呢?这就是HBase Region查找的问题

客户端按照上面的流程查找需要读写的RegionServer。这个过程一般是第一次读写的时候进行的,在第一次读取到元数据之后客户端一般会把这些信息缓存到自己的内存中,后面操作直接从内存拿就行。当然,后面元数据信息可能还会变动,这时候客户端会再次按照上面的流程获取元数据。
参考出处微信公众号:过往记忆大数据
你的鼓励是我分享技术最大的动力!如有错误之处,请指正,不胜感激。















 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









