







 本文深入解析了Swin Transformer中的掩码机制,该机制源于其滑动窗口自注意力机制。通过理解窗口划分和滑动过程,以及如何通过掩码避免不同窗口间不应有的注意力交互,文章详细阐述了掩码的生成与作用。文中还通过代码解释了掩码的计算过程,帮助读者更好地掌握这一关键概念。
本文深入解析了Swin Transformer中的掩码机制,该机制源于其滑动窗口自注意力机制。通过理解窗口划分和滑动过程,以及如何通过掩码避免不同窗口间不应有的注意力交互,文章详细阐述了掩码的生成与作用。文中还通过代码解释了掩码的计算过程,帮助读者更好地掌握这一关键概念。
0、前言
最近几天看了Swin-Transformer这篇论文,在看代码时对其中的掩码机制不解,尤其是看不懂代码的理解,而Swin的掩码机制又是论文的亮点之一,在查阅各方资料后终于弄懂了原理。
1、什么是掩码机制?
1.1滑动窗口机制(Shift windows)
为了理解什么是掩码机制,我们需要知道为什么需要掩码机制,这就是因为Swin的滑动窗口的原因。

图1.1.1
众所周知,Swin的自注意力机制是基于窗口的自注意力机制,如图1.1.1所示,而基于窗口的自注意力机制意味着窗口和窗口之间的联系消失了,这其实有悖于Transformer结构的全局自注意力机制,也丢掉了Transformer的最大优势。因此Swin的作者在这里又提出了一种自注意力机制。

图1.1.2
Swin中的另一种自注意力机制就是基于滑动窗口的自注意力机制,如图1.1.2所示。
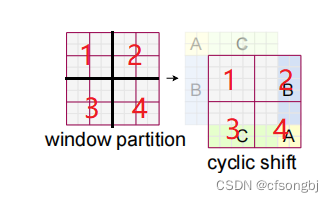
图1.1.3:左位未经滑动的原图,右图经过滑动的结果图
图1.1.3左图指代未经过滑动,图片一共有四个窗口,分别在这四个窗口内做自注意力机制。图1.1.3的右图指代经过滑动窗口后,还是四个窗口内做自注意力,但这四个窗口已经与图左的四个窗口有所区别。从1.1.3可以看出,滑动指的就是将图片的左面一部分和上面一部分分别移动到图片的右面和下面,移动的大小即为Shift-Size。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









