







一、介绍

二、遍历理解

三、先序算法
可以注意到先序算法图中Visit函数,在递归调用左,右结点前已经调用,实现了根结点的首先读取。

先序,中序,后序算法都是按照同一种顺序访问结点,但是区别在读取结点数据函数Visit位置。如果我们把图中Visit函数下移一行。就变成了先序遍历。
四、先序,中序得到二叉树
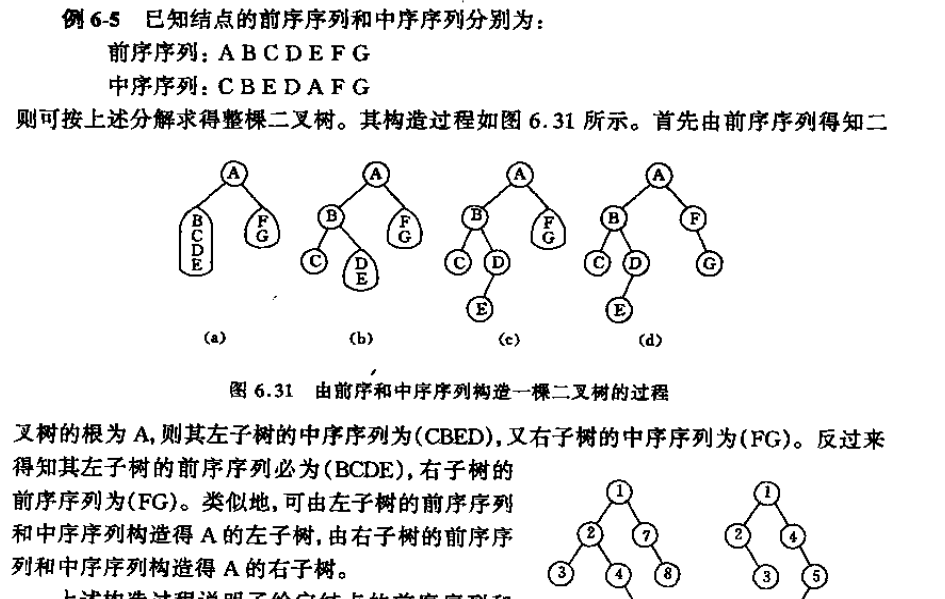
首先需明白:先序,中序,后序中的先,中,后指的是根结点的遍历顺序。
以中序遍历为例(数据读取顺序:先左树,再根结点,再右树):
1、先找到根结点,遍历了但是不能读取数据,此时树被分成两个子树,分别称为左树1,右树1。
2、对于左树1,我们把它当成新的一棵树。先访问根结点,遍历了但是不能读取数据,左树1左边为叶子
读取数据(a),然后读取根结点 (+)。左树1右边为子树,姑且称为右树2
3、对于右树2,右树2左边为叶子,读取数据(b),然后读取根结点 (*)。右树2右边为子树,姑且称为右树3
4、对于右树3,右树3左边为叶子,读取数据(c),然后读取根结点 (-)。右树2右边为叶子,读取数据(d)。
。。。。。。
同理其他
规则:先序的第一结点必定是根结点,中序根结点左右两边分别为左右子树。
注意:我们通过在先序中找到的根结点来通过中序中对于的位置对先序中的左右树进行划分,但是划分到只剩两个结点时我们需要通过中序来判断叶子是左叶子还是右叶子。
按照上述规则:
看前序序列:A为根节点
看中序序列:因A为根节点,(CBED)左子树,(FG)右子树
看前序序列:对其划分A|BCDE|FG,知B为根节点,F为根节点
看中序序列(FG):因F为根结点,G为右叶子
看中序序列(CBED):因B为根节点,(C)左子树,(ED)右子树
看前序序列(BCDE):对其划分B|C|DE,知D为根节点
看前序序列(ED):因D为根结点,E为左叶子
五、代码
来源
一、前序遍历
1)依据上文提到的遍历思路:根结点 —> 左子树 —> 右子树,非常easy写出递归版本号:
public void preOrderTraverse1(TreeNode root) {
if (root != null) {
System.out.print(root.val+" ");
preOrderTraverse1(root.left);
preOrderTraverse1(root.right);
}
}
2)如今讨论非递归的版本号:
依据前序遍历的顺序,优先訪问根结点。然后在訪问左子树和右子树。所以。对于随意结点node。第一部分即直接訪问之,之后在推断左子树是否为空,不为空时即反复上面的步骤,直到其为空。若为空。则须要訪问右子树。注意。在訪问过左孩子之后。须要反过来訪问其右孩子。所以,须要栈这样的数据结构的支持。对于随意一个结点node,详细过程例如以下:
a)訪问之,并把结点node入栈。当前结点置为左孩子;
b)推断结点node是否为空,若为空。则取出栈顶结点并出栈,将右孩子置为当前结点;否则反复a)步直到当前结点为空或者栈为空(能够发现栈中的结点就是为了訪问右孩子才存储的)
代码例如以下:
public void preOrderTraverse2(TreeNode root) {
LinkedList<TreeNode> stack = new LinkedList<>();
TreeNode pNode = root;
while (pNode != null || !stack.isEmpty()) {
if (pNode != null) {
System.out.print(pNode.val+" ");
stack.push(pNode);
pNode = pNode.left;
} else { //pNode == null && !stack.isEmpty()
TreeNode node = stack.pop();
pNode = node.right;
}
}
}
二、中序遍历
1)依据上文提到的遍历思路:左子树 —> 根结点 —> 右子树,非常easy写出递归版本号:
public void inOrderTraverse1(TreeNode root) {
if (root != null) {
inOrderTraverse1(root.left);
System.out.print(root.val+" ");
inOrderTraverse1(root.right);
}
}
2)非递归实现,有了上面前序的解释,中序也就比較简单了。同样的道理。仅仅只是訪问的顺序移到出栈时。代码例如以下:
public void inOrderTraverse2(TreeNode root) {
LinkedList<TreeNode> stack = new LinkedList<>();
TreeNode pNode = root;
while (pNode != null || !stack.isEmpty()) {
if (pNode != null) {
stack.push(pNode);
pNode = pNode.left;
} else { //pNode == null && !stack.isEmpty()
TreeNode node = stack.pop();
System.out.print(node.val+" ");
pNode = node.right;
}
}
}
三、后序遍历
1)依据上文提到的遍历思路:左子树 —> 右子树 —> 根结点。非常easy写出递归版本号:
public void postOrderTraverse1(TreeNode root) {
if (root != null) {
postOrderTraverse1(root.left);
postOrderTraverse1(root.right);
System.out.print(root.val+" ");
}
}
2)
后序遍历的非递归实现是三种遍历方式中最难的一种。由于在后序遍历中,要保证左孩子和右孩子都已被訪问而且左孩子在右孩子前訪问才干訪问根结点,这就为流程的控制带来了难题。以下介绍两种思路。
第一种思路:对于任一结点P,将其入栈,然后沿其左子树一直往下搜索。直到搜索到没有左孩子的结点,此时该结点出如今栈顶,可是此时不能将其出栈并訪问,因此其右孩子还为被訪问。
所以接下来依照同样的规则对其右子树进行同样的处理,当訪问完其右孩子时。该结点又出如今栈顶,此时能够将其出栈并訪问。这样就保证了正确的訪问顺序。能够看出,在这个过程中,每一个结点都两次出如今栈顶,仅仅有在第二次出如今栈顶时,才干訪问它。因此须要多设置一个变量标识该结点是否是第一次出如今栈顶。
void postOrder2(BinTree *root) //非递归后序遍历
{
stack<BTNode*> s;
BinTree *p=root;
BTNode *temp;
while(p!=NULL||!s.empty())
{
while(p!=NULL) //沿左子树一直往下搜索。直至出现没有左子树的结点
{
BTNode *btn=(BTNode *)malloc(sizeof(BTNode));
btn->btnode=p;
btn->isFirst=true;
s.push(btn);
p=p->lchild;
}
if(!s.empty())
{
temp=s.top();
s.pop();
if(temp->isFirst==true) //表示是第一次出如今栈顶
{
temp->isFirst=false;
s.push(temp);
p=temp->btnode->rchild;
}
else //第二次出如今栈顶
{
cout<<temp->btnode->data<<" ";
p=NULL;
}
}
}
}
另外一种思路:要保证根结点在左孩子和右孩子訪问之后才干訪问,因此对于任一结点P。先将其入栈。假设P不存在左孩子和右孩子。则能够直接訪问它;或者P存在左孩子或者右孩子。可是其左孩子和右孩子都已被訪问过了。则相同能够直接訪问该结点。若非上述两种情况。则将P的右孩子和左孩子依次入栈。这样就保证了每次取栈顶元素的时候,左孩子在右孩子前面被訪问。左孩子和右孩子都在根结点前面被訪问。
void postOrder3(BinTree *root) //非递归后序遍历
{
stack<BinTree*> s;
BinTree *cur; //当前结点
BinTree *pre=NULL; //前一次訪问的结点
s.push(root);
while(!s.empty())
{
cur=s.top();
if((cur->lchild==NULL&&cur->rchild==NULL)||
(pre!=NULL&&(pre==cur->lchild||pre==cur->rchild)))
{
cout<<cur->data<<" "; //假设当前结点没有孩子结点或者孩子节点都已被訪问过
s.pop();
pre=cur;
}
else
{
if(cur->rchild!=NULL)
s.push(cur->rchild);
if(cur->lchild!=NULL)
s.push(cur->lchild);
}
}
}
四、层次遍历
层次遍历的代码比較简单。仅仅须要一个队列就可以。先在队列中增加根结点。之后对于随意一个结点来说。在其出队列的时候,訪问之。同一时候假设左孩子和右孩子有不为空的。入队列。代码例如以下:
public void levelTraverse(TreeNode root) {
if (root == null) {
return;
}
LinkedList<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
System.out.print(node.val+" ");
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
}
五、深度优先遍历
事实上深度遍历就是上面的前序、中序和后序。可是为了保证与广度优先遍历相照顾,也写在这。代码也比較好理解,事实上就是前序遍历,代码例如以下:
public void depthOrderTraverse(TreeNode root) {
if (root == null) {
return;
}
LinkedList<TreeNode> stack = new LinkedList<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
System.out.print(node.val+" ");
if (node.right != null) {
stack.push(node.right);
}
if (node.left != null) {
stack.push(node.left);
}
}
}
试题
LeetCode : Binary Tree Preorder Traversal 二叉树前序遍历 递归 迭代
LeetCode : Binary Tree Postorder Traversal 二叉树后序遍历 递归 迭代
LeetCode : Binary Tree Inorder Traversal 二叉树中序遍历 递归 迭代















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









