







这篇博客就是接在我上篇博客网络编程–JAVA之多线程下载的基础上来实现的。
首先,我来说一下断点续存能解决啥问题:
假如当我们在进行MP4下载时,如果突然出现人为的中断或者意外的中断,那么当我们再次点击下载时,我们是希望下载的进度是接着上次中断的地方继续下载,而不是又重新的下载,这不是我们所希望的,那么断点续存就是解决这个问题的。
接着,我们还是来梳理一下断点续存的思路步骤:
要想继续在中断的位置继续下载,那么我们就得先记录下每条线程在中断时下载长度,而我们又不能判断出什么时候中断,所以我们就得时刻的将每条线程下载的长度及记录下来。
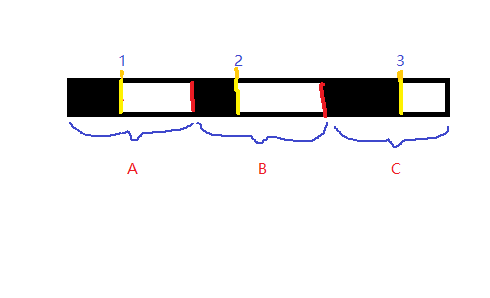
(在这里,假如这里还是有三条线程A、B、C来进行分段的下载MP4,突然,一部小网断了,下载中断了,A线程在1的地方中断了,B线程在2的地方中断了,C线程在3的地方中断了,那么要想实现续存,就得知道1、2、3这三点时A、B、C上阴影部分的长度)2.完成下载后,我们为了不影响用户的内存以及保证用户不删错东西,我们要将保存每条线程长度的临时文件删除,作为一个完美的善后工作。
在这里的Main方法中,我们还是基本沿用了上篇博客 网络编程–JAVA之多线程下载上的Main方法的代码,只是加了一行代码:public static int finishedThead=0;(这是为了标志记录已经下载完成的线程,是为了后面的善后工作,也就是为了当全部完成后删除那些记录每条线程下载长度的临时文件),所以这里的Main方法中的代码就不写了。我们主要的操作是在DownLoadThread这个方法中的:
DownLoadThread代码块:
package com.ecjtu.mutilThread;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.RandomAccessFile;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.ProtocolException;
import java.net.URL;
/*
* 在这里我们是先完成多线程下载,再在此基础上添加少许代码完成断点续存
*/
public class DownLoadThread extends Thread {
private int startIndex,endIndex,threadId;
private String path;
public DownLoadThread(int startIndex,int endIndex,String path,int threadId) {
this.startIndex=startIndex;
this.endIndex=endIndex;
this.path=path;
this.threadId=threadId;
}
@Override
public void run() {
URL url;
try {
///---------------------------------------------
////这写代码也是断点续存添加的代码
File file2=new File(threadId+".txt");
int lastProgress=0;
///这里是先判断临时文件是否存在,如果存在,将上次下载的最后进度读出来,并且加上startIndex
///以此保证断点恢复后开始下载的位置是上次中断前的位置
if(file2.exists()){
FileInputStream fileInputStream=new FileInputStream(file2);
BufferedReader br=new BufferedReader(new InputStreamReader(fileInputStream));
lastProgress=Integer.parseInt(br.readLine());
startIndex+=lastProgress;
}
///--------------------------------------------
///这里才是利用HttpURLConnection拿到需要下载的真正的输入流
url=new URL(path);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(8000);
connection.setReadTimeout(8000);
///在这里用HttpURLConnection的设置请求属性的方法,来请求获取每一段的信息
///在这里的格式书写是一样的,固定的。
connection.setRequestProperty("Range", "bytes="+startIndex+"-"+endIndex);
///这里的206是代表上面的区段请求的响应的返回码
if(connection.getResponseCode()==206){
///接下就是输入流的一些操作
InputStream is=connection.getInputStream();
File file=new File("nihao.zip");
RandomAccessFile ref=new RandomAccessFile(file,"rwd");
ref.seek(startIndex);///标志开始位置,可以让线程在文件中从不同位置开始存储
byte[] b=new byte[1024];
int len=0;
int total = lastProgress;//注意这里需要改变一下,才能完整的实现断点续存
while((len=is.read(b))!=-1){
ref.write(b, 0, len);
total+=len;
System.out.println("第"+threadId+"条线程的下载"+total);
///断点续存的添加代码
///这段代码是将每个线程的Id的下载进度total记录保存为文件
//--------------------------------------------------
RandomAccessFile refprgrass=new RandomAccessFile(file2, "rwd");
refprgrass.write((total+"").getBytes());
refprgrass.close();
//------------------------------------------------
}
ref.close();
System.out.println("第"+threadId+"条线程的下载结束");
///------------------------------------
/*
* 这里代码也是断点续存增加的代码,
* 在这里用一个标志位保证线程全部下载完成,才能让其删除临时文件
* 如果在这里不用标志位来保证线程全部的下载完成的话再删除,而是当一条线程一下载完后就删除了的话,
* (在这里假设线程A刚被下载完就存储下载长度的临时文件就被删除,)
* 那么接着一旦中断,等到下次恢复时,那么线程A的临时存储的下载完成进度的文件没有了,被删掉了,但是其他线程因为没下完那些存储下载进度的文件还在,那这样就又会默认的重新的又将线程A重新的下载
*/
Main.finishedThead++;
///这就是上面说的善后的工作
if(Main.finishedThead==Main.threadCount){
///线程全都下完了
for(int i=0;i<Main.threadCount;i++){
File f=new File(i+".txt");//这里就是要用这种方式来找到那些临时文件进行一一的删除操作
f.delete();///将新建的临时文件一一删除
}
}
///----------------------------------------------
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (ProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
super.run();
}
}
在代码中,我将后面断点续存添加的代码分割出来并注释了,到了现在断点续存就完成了,但是在写完后我发现这里还是有一点的小瑕疵,那就是我们也应该将Main.finishedThead这个记录下载完成的线程个数放在文本中先保存下来,因为有可能出现当我们线程A线程B下完了,又来一个突然,断网了,中断了,那么当重新运行时,Main.finishedThead又被初始化为0,那么当线程C被下载完后,Main.finishedThead才变为1,这样就永远不可能等于线程的总数,也就不能将那些临时文件删掉了。总之一句话就是在这我们需要将Main.finishedThead保留成不管怎么中断,Main.finishedThead的值会一直稳定的+1,而不是中断了就又变为0,这里我就不写了,和将每个线程的下载长度保留的方法是一样的。















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









