








十九 优化数据对象
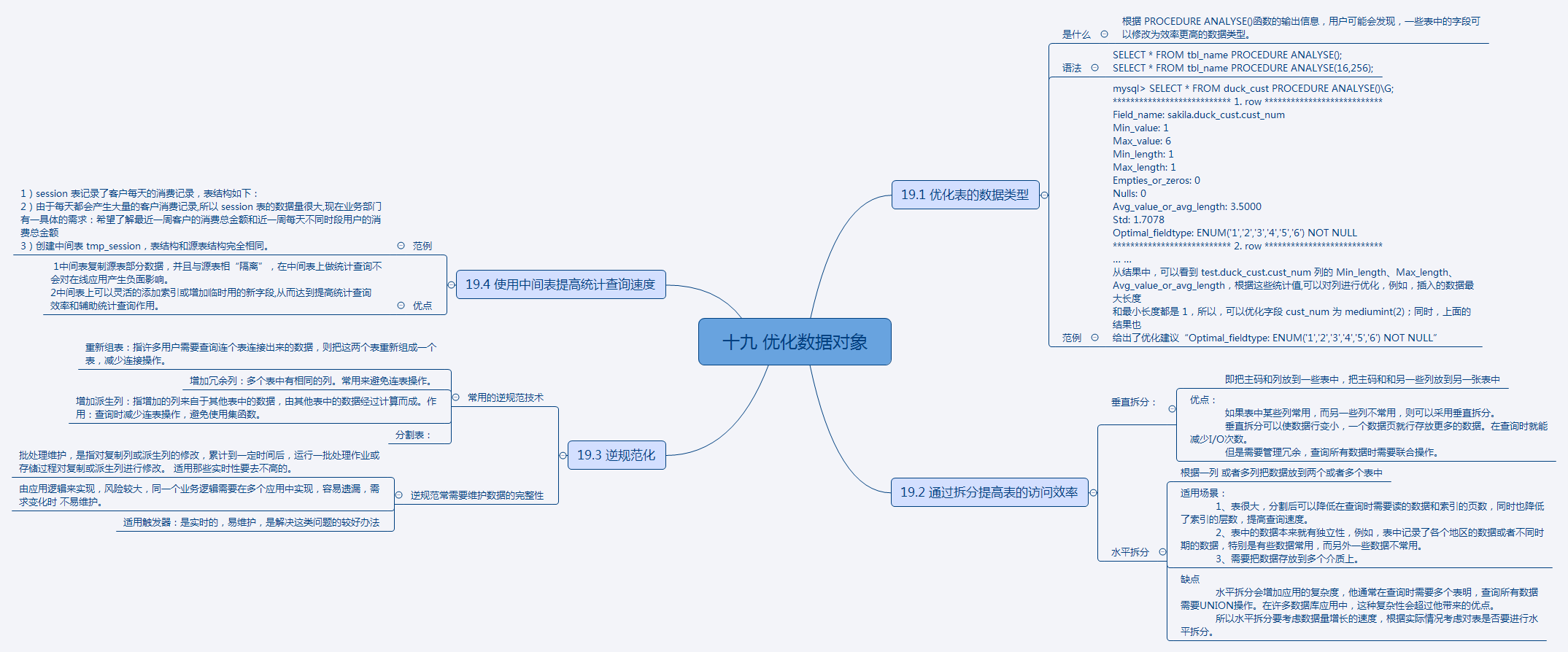
19.1 优化表的数据类型
是什么
根据 PROCEDURE ANALYSE()函数的输出信息,用户可能会发现,一些表中的字段可以修改为效率更高的数据类型。
语法
SELECT * FROM tbl_name PROCEDURE ANALYSE();
SELECT * FROM tbl_name PROCEDURE ANALYSE(16,256);
范例
mysql> SELECT * FROM duck_cust PROCEDURE ANALYSE()\G;
*************************** 1. row ***************************
Field_name: sakila.duck_cust.cust_num
Min_value: 1
Max_value: 6
Min_length: 1
Max_length: 1
Empties_or_zeros: 0
Nulls: 0
Avg_value_or_avg_length: 3.5000
Std: 1.7078
Optimal_fieldtype: ENUM('1','2','3','4','5','6') NOT NULL
*************************** 2. row ***************************
… …
从结果中,可以看到 test.duck_cust.cust_num 列的 Min_length、Max_length、
Avg_value_or_avg_length,根据这些统计值,可以对列进行优化,例如,插入的数据最大长度
和最小长度都是 1,所以,可以优化字段 cust_num 为 mediumint(2);同时,上面的结果也
给出了优化建议“Optimal_fieldtype: ENUM('1','2','3','4','5','6') NOT NULL”
19.2 通过拆分提高表的访问效率
垂直拆分:
即把主码和列放到一些表中,把主码和和另一些列放到另一张表中
优点:
如果表中某些列常用,而另一些列不常用,则可以采用垂直拆分。
垂直拆分可以使数据行变小,一个数据页就行存放更多的数据。在查询时就能减少I/O次数。
但是需要管理冗余,查询所有数据时需要联合操作。
水平拆分
根据一列 或者多列把数据放到两个或者多个表中
适用场景:
1、表很大,分割后可以降低在查询时需要读的数据和索引的页数,同时也降低了索引的层数,提高查询速度。
2、表中的数据本来就有独立性,例如,表中记录了各个地区的数据或者不同时期的数据,特别是有些数据常用,而另外一些数据不常用。
3、需要把数据存放到多个介质上。
缺点
水平拆分会增加应用的复杂度,他通常在查询时需要多个表明,查询所有数据需要UNION操作。在许多数据库应用中,这种复杂性会超过他带来的优点。
所以水平拆分要考虑数据量增长的速度,根据实际情况考虑对表是否要进行水平拆分。
19.3 逆规范化
常用的逆规范技术
重新组表:指许多用户需要查询连个表连接出来的数据,则把这两个表重新组成一个表,减少连接操作。
增加冗余列:多个表中有相同的列。常用来避免连表操作。
增加派生列:指增加的列来自于其他表中的数据,由其他表中的数据经过计算而成。作用:查询时减少连表操作,避免使用集函数。
分割表:
逆规范常需要维护数据的完整性
批处理维护,是指对复制列或派生列的修改,累计到一定时间后,运行一批处理作业或存储过程对复制或派生列进行修改。 适用那些实时性要去不高的。
由应用逻辑来实现,风险较大,同一个业务逻辑需要在多个应用中实现,容易遗漏,需求变化时 不易维护。
适用触发器:是实时的,易维护,是解决这类问题的较好办法
19.4 使用中间表提高统计查询速度
范例
1)session 表记录了客户每天的消费记录,表结构如下:
2)由于每天都会产生大量的客户消费记录,所以 session 表的数据量很大,现在业务部门有一具体的需求:希望了解最近一周客户的消费总金额和近一周每天不同时段用户的消费总金额
3)创建中间表 tmp_session,表结构和源表结构完全相同。
优点
1中间表复制源表部分数据,并且与源表相“隔离”,在中间表上做统计查询不
会对在线应用产生负面影响。
2中间表上可以灵活的添加索引或增加临时用的新字段,从而达到提高统计查询
效率和辅助统计查询作用。
深入浅出mysql_优化数据对象
最新推荐文章于 2021-01-21 16:40:21 发布
















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









