







当内存分配的时候,剩余的空间不能满足要分配的对象时就会优先触发新生代回收(Young GC,YGC)。G1的YGC是针对部分内存进行的垃圾回收,所以YGC花费的时间通常都比较小。G1的内存被划分为众多小的分区,分区可能属于新生代,也可能属于老生代。G1的YGC收集的内存是不固定的,每次回收的内存可能并不相同,即每次回收的分区数目是不固定的,但是每一次YGC都是收集所有的新生代分区,所以每一次GC之后都会调整新生代分区的数目。如何调整新生代分区的数目?就是根据我们之前提到的预测停顿模型。本章介绍的主要内容有:YGC算法、YGC代码剖析、YGC算法演示、日志解析和如何进行YGC调优。
YGC算法概述
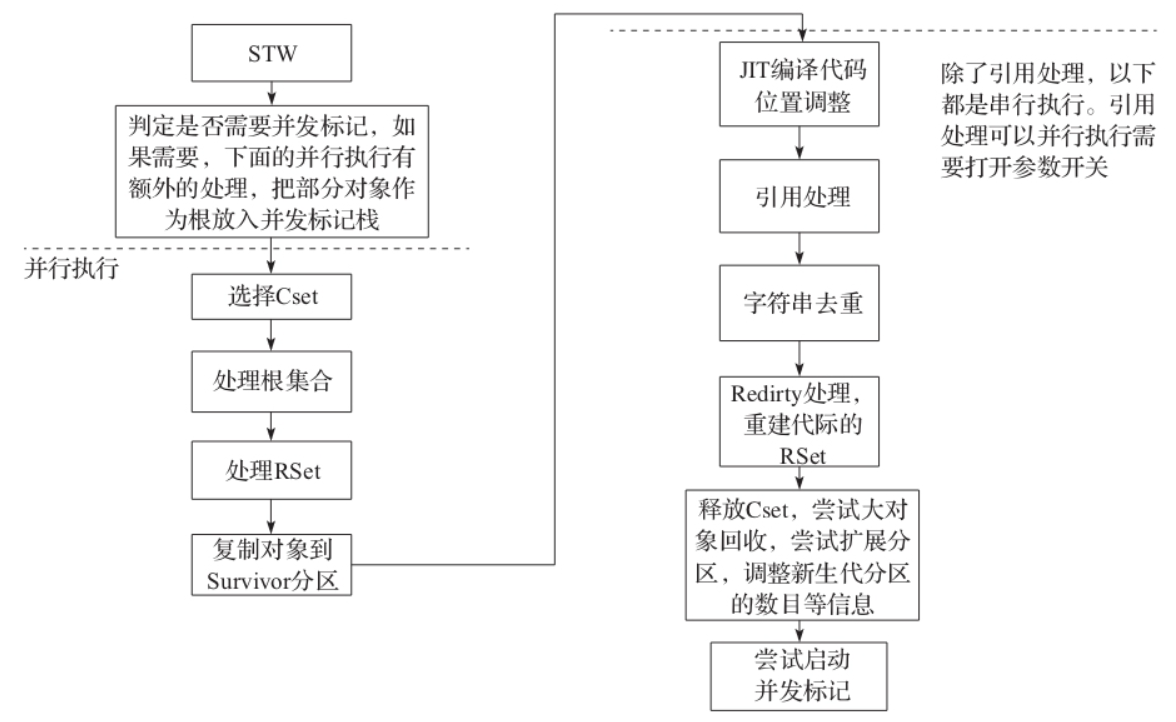
YGC算法主要分为两部分:并行部分和其他部分。我们根据YGC的执行顺序来看一下整个收集过程的主要步骤。
1)进行收集之前需要STW。
2)选择要收集的CSet,对于YGC来说整个新生代分区就是CSet。
3)进入并行任务处理:
- 根扫描并处理;处理过程会把根直接引用的对象复制到新的Survivor区,然后把被引用对象的field入栈等待后续的复制处理。
- 处理老生代分区到新生代分区的引用;首先会更新所有的代际引用,即更新RSet[插图],然后从RSet出发,把RSet所在卡表对应的分区内存块中所有的对象都认为是根,把这些根引用的对象复制到新的Survivor区,然后把被引用对象的field入栈等待后续的复制处理。
- JIT代码扫描。
- 根据栈中的对象,进行深度递归遍历复制对象。
4)下面是其他任务处理,大部分都是串行执行:
- JIT代码位置更新,在并行任务中已经对代码进行了扫描和复制,这里会更新相关指针所指向的位置。
- 引用处理,即把引用中使用的存活对象也要复制到新的分区,否则就会造成错误;引用处理在第8章中介绍。
- 字符串去重优化回收,这个是JDK8 G1新引入的功能。是为了优化字符串使用的效率,字符串去重优化在第9章中介绍。
- 清除卡表,就是把全局卡表中已经处理过的分区对应的卡表清空。
- JIT代码回收,代码已经可以回收,实际上是删除相关的引用,这一部分代码对GC影响不大,所以本文不再涉及。
- 如果Evac失败,则进行处理,主要的工作就是恢复对象头;关于Evac失败的具体可以参考第7章中的介绍。
- 引用再处理,把引用中还活着的对象放入引用队列中,这个和引用特殊的设计有关;可以参考后文中引用处理的介绍。
- 进行Redirty,主要工作就是重构RSet,包括收集过程中,因为对象移动需要重构老生代分区到新生代分区新分区的引用,这个过程不仅仅是收集成功也包括回收失败,不过收集失败需要做额外的记录;Redirty通常是并行执行的。
- 释放CSet,在这个位置可以启动释放内存,即把这些分区放入自由列表(Free List),供后续使用,这里的后续指的是对象分配时如果需要新的分区,可以直接从自由列表获取。当然分区可能作为新生代分区也可能作为老生代分区。
- 尝试大对象回收,处理比较简单,只要判定这些大对象所在的分区是否有RSet引用,且只需要判断大对象所在第一个分区,如果没有引用则说明整个大对象肯定已经死亡,有引用则说明大对象可能还活着,在并发标记中进一步处理。
- 尝试扩展内存,这里的扩展就是用到我们在前面讲到的根据GCTimeRatio和G1ExpandByPercentOfAvailable来判断是否可以扩展,如果可以,扩展多大的内存。
- 如果可能的话,启动并发标记;使用的内存超过一定的阈值则可以启动,具体在混合回收中介绍。
整体流程如下图所示。
YGC代码分析
正如上面提到的,YGC分为两大部分,并行任务和其他任务。并行任务是YGC最重要的部分,我们在介绍的时候也主要关注并行任务。
并行任务
并行任务处理是通过第2章中的工作线程FlexibleWorkGang来执行任务G1ParTask,这个任务主要分为:
1)根扫描并处理。针对所有的根,对可达对象做:
- a)如果对象还没有设置过标记信息,把对象从Eden复制到Survivor,然后针对对象的每一个field,如果field所引用的分区在CSet,则把对象的地址加入到G1ParScanThreadState(PSS)的队列中待扫描处理;如果字段不在CSet,则更新该对象所在堆分区对应的RSet。
- b)更新根对象到对象新的位置。更新根对象后,对象发生了复制,所以一个对象对应两个内存区域,通常我们以对象的老位置和新位置来区分对象复制前后的内存。在下文中有时候我们也用老对象表示对象的老位置的引用,新对象表示对象的新位置的引用,请注意这些概念。
2)处理老生代分区到新生代分区的引用。
- a)处理Dirty card,更新RSet,更新老生代分区到新生代分区的引用。
- b)扫描RSet,把引用者作为根,从根出发,对可达对象进行根扫描并处理(参见第1步)。
3)复制。在PSS中队列的对象都是活跃对象,每一个对象都要复制到Survivor区,然后针对该对象的每一个字段:如果字段所引用的分区在CSet,则把对象的地址加入到G1ParScanThreadState(PSS)的队列中待扫描处理;循环直到队列中没有对象。
class G1ParTask : public AbstractGangTask {
protected:
G1CollectedHeap* _g1h;
RefToScanQueueSet *_queues;
G1RootProcessor* _root_processor;
ParallelTaskTerminator _terminator;
uint _n_workers;
Mutex _stats_lock;
Mutex* stats_lock() { return &_stats_lock; }
public:
G1ParTask(G1CollectedHeap* g1h, RefToScanQueueSet *task_queues, G1RootProcessor* root_processor)
: AbstractGangTask("G1 collection"),
_g1h(g1h),
_queues(task_queues),
_root_processor(root_processor),
_terminator(0, _queues),
_stats_lock(Mutex::leaf, "parallel G1 stats lock", true)
{}
RefToScanQueueSet* queues() { return _queues; }
RefToScanQueue *work_queue(int i) {
return queues()->queue(i);
}
ParallelTaskTerminator* terminator() { return &_terminator; }
virtual void set_for_termination(int active_workers) {
_root_processor->set_num_workers(active_workers);
terminator()->reset_for_reuse(active_workers);
_n_workers = active_workers;
}
// Helps out with CLD processing.
//
// During InitialMark we need to:
// 1) Scavenge all CLDs for the young GC.
// 2) Mark all objects directly reachable from strong CLDs.
template <G1Mark do_mark_object>
class G1CLDClosure : public CLDClosure {
G1ParCopyClosure<G1BarrierNone, do_mark_object>* _oop_closure;
G1ParCopyClosure<G1BarrierKlass, do_mark_object> _oop_in_klass_closure;
G1KlassScanClosure _klass_in_cld_closure;
bool _claim;
public:
G1CLDClosure(G1ParCopyClosure<G1BarrierNone, do_mark_object>* oop_closure,
bool only_young, bool claim)
: _oop_closure(oop_closure),
_oop_in_klass_closure(oop_closure->g1(),
oop_closure->pss(),
oop_closure->rp()),
_klass_in_cld_closure(&_oop_in_klass_closure, only_young),
_claim(claim) {
}
void do_cld(ClassLoaderData* cld) {
cld->oops_do(_oop_closure, &_klass_in_cld_closure, _claim);
}
};
void work(uint worker_id);
};并行处理的入口在G1ParTask::work,它是通过工作线程激活,工作线程的数目由ParallelGCThreads控制,这个值默认为0,G1可以自行推断线程数。并行处理代码如下所示:
void G1ParTask::work(uint worker_id) {
if (worker_id >= _n_workers) return; // no work needed this round
_g1h->g1_policy()->phase_times()->record_time_secs(G1GCPhaseTimes::GCWorkerStart, worker_id, os::elapsedTime());
{
ResourceMark rm;
HandleMark hm;
ReferenceProcessor* rp = _g1h->ref_processor_stw();
G1ParScanThreadState pss(_g1h, worker_id, rp);
G1ParScanHeapEvacFailureClosure evac_failure_cl(_g1h, &pss, rp);
pss.set_evac_failure_closure(&evac_failure_cl);
bool only_young = _g1h->g1_policy()->gcs_are_young();
// Non-IM young GC.
G1ParCopyClosure<G1BarrierNone, G1MarkNone> scan_only_root_cl(_g1h, &pss, rp);
G1CLDClosure<G1MarkNone> scan_only_cld_cl(&scan_only_root_cl,
only_young, // Only process dirty klasses.
false); // No need to claim CLDs.
// IM young GC.
// Strong roots closures.
G1ParCopyClosure<G1BarrierNone, G1MarkFromRoot> scan_mark_root_cl(_g1h, &pss, rp);
G1CLDClosure<G1MarkFromRoot> scan_mark_cld_cl(&scan_mark_root_cl,
false, // Process all klasses.
true); // Need to claim CLDs.
// Weak roots closures.
G1ParCopyClosure<G1BarrierNone, G1MarkPromotedFromRoot> scan_mark_weak_root_cl(_g1h, &pss, rp);
G1CLDClosure<G1MarkPromotedFromRoot> scan_mark_weak_cld_cl(&scan_mark_weak_root_cl,
false, // Process all klasses.
true); // Need to claim CLDs.
OopClosure* strong_root_cl;
OopClosure* weak_root_cl;
CLDClosure* strong_cld_cl;
CLDClosure* weak_cld_cl;
bool trace_metadata = false;
if (_g1h->g1_policy()->during_initial_mark_pause()) {
// We also need to mark copied objects.
strong_root_cl = &scan_mark_root_cl;
strong_cld_cl = &scan_mark_cld_cl;
if (ClassUnloadingWithConcurrentMark) {
weak_root_cl = &scan_mark_weak_root_cl;
weak_cld_cl = &scan_mark_weak_cld_cl;
trace_metadata = true;
} else {
weak_root_cl = &scan_mark_root_cl;
weak_cld_cl = &scan_mark_cld_cl;
}
} else {
strong_root_cl = &scan_only_root_cl;
weak_root_cl = &scan_only_root_cl;
strong_cld_cl = &scan_only_cld_cl;
weak_cld_cl = &scan_only_cld_cl;
}
pss.start_strong_roots();
// 处理根
_root_processor->evacuate_roots(strong_root_cl,
weak_root_cl,
strong_cld_cl,
weak_cld_cl,
trace_metadata,
worker_id);
G1ParPushHeapRSClosure push_heap_rs_cl(_g1h, &pss);
// 处理DCQS中剩下的DCQ,以及把RSet作为根处理
_root_processor->scan_remembered_sets(&push_heap_rs_cl,
weak_root_cl,
worker_id);
pss.end_strong_roots();
{
double start = os::elapsedTime();
// 开始复制
G1ParEvacuateFollowersClosure evac(_g1h, &pss, _queues, &_terminator);
evac.do_void();
double elapsed_sec = os::elapsedTime() - start;
double term_sec = pss.term_time();
_g1h->g1_policy()->phase_times()->add_time_secs(G1GCPhaseTimes::ObjCopy, worker_id, elapsed_sec - term_sec);
_g1h->g1_policy()->phase_times()->record_time_secs(G1GCPhaseTimes::Termination, worker_id, term_sec);
_g1h->g1_policy()->phase_times()->record_thread_work_item(G1GCPhaseTimes::Termination, worker_id, pss.term_attempts());
}
_g1h->g1_policy()->record_thread_age_table(pss.age_table());
_g1h->update_surviving_young_words(pss.surviving_young_words()+1);
if (ParallelGCVerbose) {
MutexLocker x(stats_lock());
pss.print_termination_stats(worker_id);
}
assert(pss.queue_is_empty(), "should be empty");
// Close the inner scope so that the ResourceMark and HandleMark
// destructors are executed here and are included as part of the
// "GC Worker Time".
}
_g1h->g1_policy()->phase_times()->record_time_secs(G1GCPhaseTimes::GCWorkerEnd, worker_id, os::elapsedTime());
}1.根处理
JVM中的根在这里也称为强根,指的是JVM的堆外空间引用到堆空间的对象,有栈或者全局变量等。整个根分为两大类:
- Java根:主要指类加载器和线程栈。
- 类加载器主要是遍历这个类加载器中所有存活的Klass并复制(copy)到Survivor或者晋升到老生代。
- 线程栈既会处理普通的Java线程栈分配的局部变量,也会处理本地方法栈访问的堆对象,在介绍线程栈的时候已经介绍了如何把栈对象和堆对象进行关联。
- JVM根:通常是全局对象,比如Universe、JNIHandles、ObjectSynchronizer、FlatProfiler、Management、JvmtiExport、SystemDictionary、StringTable。
注意:Klass指的是JVM对Java对象的元数据描述,Java对象的创建都需要通过元数据获得。这里不展开介绍这些概念,如需进一步了解可阅读相关书籍。
G1RootProcessor 是 G1 垃圾回收器中扫描根部的类,主要负责扫描系统中的所有根节点,对其进行可达性分析,并对存活的对象做标记。具体来说,它实现了以下函数和属性:
- _g1h: G1CollectedHeap 对象,代表当前垃圾回收器所处理的堆。
- _process_strong_tasks: 一个 SubTasksDone 对象,表示强引用处理的任务是否完成。
- _srs: StrongRootsScope 对象,代表当前强引用的范围。
- _oop_storage_set_strong_par_state: 一个 OopStorageSetStrongParState 对象,代表当前的强引用状态。
- process_java_roots: 对 Java 根节点进行处理。
- process_vm_roots: 对 VM 根节点进行处理。
- process_code_cache_roots: 对代码缓存区根节点进行处理。
- evacuate_roots: 对所有根节点进行处理。
- process_strong_roots: 对强引用的根节点进行处理。
- process_all_roots: 对所有根节点进行处理。
- n_workers: 返回当前使用的 worker 线程数。
整个JVM进程的根引用包括:
- Java堆中的根对象(包括静态对象、本地方法栈中的对象、JNI中的对象、Java栈中的对象)
- VM内部的根引用(包括系统类加载器、Java Agent等)
- Code Cache中的根引用(包括JIT编译产生的代码缓存)
- OopStorage中的根引用(包括引用数组等)
在G1垃圾回收中,扫描这些区域是非常重要的,因为这些根引用是所有对象存活的起点。
// Scoped object to assist in applying oop, CLD and code blob closures to
// root locations. Handles claiming of different root scanning tasks
// and takes care of global state for root scanning via a StrongRootsScope.
// In the parallel case there is a shared G1RootProcessor object where all
// worker thread call the process_roots methods.
class G1RootProcessor : public StackObj {
G1CollectedHeap* _g1h;
SubTasksDone _process_strong_tasks;
SharedHeap::StrongRootsScope _srs;
// Used to implement the Thread work barrier.
Monitor _lock;
volatile jint _n_workers_discovered_strong_classes;
enum G1H_process_roots_tasks {
G1RP_PS_Universe_oops_do,
G1RP_PS_JNIHandles_oops_do,
G1RP_PS_ObjectSynchronizer_oops_do,
G1RP_PS_FlatProfiler_oops_do,
G1RP_PS_Management_oops_do,
G1RP_PS_SystemDictionary_oops_do,
G1RP_PS_ClassLoaderDataGraph_oops_do,
G1RP_PS_jvmti_oops_do,
G1RP_PS_CodeCache_oops_do,
G1RP_PS_filter_satb_buffers,
G1RP_PS_refProcessor_oops_do,
// Leave this one last.
G1RP_PS_NumElements
};
void worker_has_discovered_all_strong_classes();
void wait_until_all_strong_classes_discovered();
void process_all_roots(OopClosure* oops,
CLDClosure* clds,
CodeBlobClosure* blobs,
bool process_string_table);
void process_java_roots(OopClosure* scan_non_heap_roots,
CLDClosure* thread_stack_clds,
CLDClosure* scan_strong_clds,
CLDClosure* scan_weak_clds,
CodeBlobClosure* scan_strong_code,
G1GCPhaseTimes* phase_times,
uint worker_i);
void process_vm_roots(OopClosure* scan_non_heap_roots,
OopClosure* scan_non_heap_weak_roots,
G1GCPhaseTimes* phase_times,
uint worker_i);
void process_string_table_roots(OopClosure* scan_non_heap_weak_roots,
G1GCPhaseTimes* phase_times,
uint worker_i);
void process_code_cache_roots(CodeBlobClosure* code_closure,
G1GCPhaseTimes* phase_times,
uint worker_i);
public:
G1RootProcessor(G1CollectedHeap* g1h);
// Apply closures to the strongly and weakly reachable roots in the system
// in a single pass.
// Record and report timing measurements for sub phases using the worker_i
void evacuate_roots(OopClosure* scan_non_heap_roots,
OopClosure* scan_non_heap_weak_roots,
CLDClosure* scan_strong_clds,
CLDClosure* scan_weak_clds,
bool trace_metadata,
uint worker_i);
// Apply oops, clds and blobs to all strongly reachable roots in the system
void process_strong_roots(OopClosure* oops,
CLDClosure* clds,
CodeBlobClosure* blobs);
// Apply oops, clds and blobs to strongly and weakly reachable roots in the system
void process_all_roots(OopClosure* oops,
CLDClosure* clds,
CodeBlobClosure* blobs);
// Apply scan_rs to all locations in the union of the remembered sets for all
// regions in the collection set
// (having done "set_region" to indicate the region in which the root resides),
void scan_remembered_sets(G1ParPushHeapRSClosure* scan_rs,
OopClosure* scan_non_heap_weak_roots,
uint worker_i);
// Apply oops, clds and blobs to strongly and weakly reachable roots in the system,
// the only thing different from process_all_roots is that we skip the string table
// to avoid keeping every string live when doing class unloading.
void process_all_roots_no_string_table(OopClosure* oops,
CLDClosure* clds,
CodeBlobClosure* blobs);
// Inform the root processor about the number of worker threads
void set_num_workers(int active_workers);
};evacuate_roots
evacuate_roots函数接受一个 G1ParScanThreadState 对象和一个 worker_id,表示当前线程状态和线程编号。函数开始时,获取当前堆的 GC 时间记录器 phase_times,使用 G1EvacPhaseTimesTracker 对象对“扫描根对象”这一阶段进行计时,并记录当前线程状态 pss 的堆根对象处理器 closures。接下来,调用 process_java_roots 和 process_vm_roots 分别处理 Java 和虚拟机根。这两个函数分别使用 closures 处理强根和弱根,并且都会使用 phase_times 进行计时。
处理完强根和弱根后,接下来处理 CM ref_processor roots,也就是使用 G1GCPhaseTimes::CMRefRoots 计时器处理 CM Ref Processor 根对象。如果当前任务队列中存在 G1RP_PS_refProcessor_oops_do 任务,则使用 _g1h->ref_processor_cm()->weak_oops_do(closures->strong_oops()) 处理弱根。
最后,处理 CodeCache 的根对象,因为 CodeCache 已经在 process_java_roots 中处理了,因此在这里直接调用 _process_strong_tasks.all_tasks_claimed(G1RP_PS_CodeCache_oops_do) 标记任务已经完成。
总体来说,这个函数的作用是对 GC 的根对象进行扫描和处理。它通过调用不同的函数处理 Java 根、虚拟机根、CM ref_processor 根和 CodeCache 根等不同类型的根。
src\share\vm\gc_implementation\g1\g1CollectedHeap.cpp
void G1RootProcessor::evacuate_roots(OopClosure* scan_non_heap_roots,
OopClosure* scan_non_heap_weak_roots,
CLDClosure* scan_strong_clds,
CLDClosure* scan_weak_clds,
bool trace_metadata,
uint worker_i) {
// First scan the shared roots.
double ext_roots_start = os::elapsedTime();
G1GCPhaseTimes* phase_times = _g1h->g1_policy()->phase_times();
// 这里使用的BufferingOopClosure,主要是为了缓存对象,然后一次性处理,大小为1024,
// 溢出时先处理。是为了提高处理的效率
BufferingOopClosure buf_scan_non_heap_roots(scan_non_heap_roots);
BufferingOopClosure buf_scan_non_heap_weak_roots(scan_non_heap_weak_roots);
OopClosure* const weak_roots = &buf_scan_non_heap_weak_roots;
OopClosure* const strong_roots = &buf_scan_non_heap_roots;
// CodeBlobClosures are not interoperable with BufferingOopClosures
G1CodeBlobClosure root_code_blobs(scan_non_heap_roots);
// 处理Java根
process_java_roots(strong_roots,
trace_metadata ? scan_strong_clds : NULL,
scan_strong_clds,
trace_metadata ? NULL : scan_weak_clds,
&root_code_blobs,
phase_times,
worker_i);
// This is the point where this worker thread will not find more strong CLDs/nmethods.
// Report this so G1 can synchronize the strong and weak CLDs/nmethods processing.
if (trace_metadata) {
worker_has_discovered_all_strong_classes();
}
// 处理JVM根
process_vm_roots(strong_roots, weak_roots, phase_times, worker_i);
// 处理字符串表根
process_string_table_roots(weak_roots, phase_times, worker_i);
{
// Now the CM ref_processor roots.
// 处理引用发现
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::CMRefRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_refProcessor_oops_do)) {
// We need to treat the discovered reference lists of the
// concurrent mark ref processor as roots and keep entries
// (which are added by the marking threads) on them live
// until they can be processed at the end of marking.
_g1h->ref_processor_cm()->weak_oops_do(&buf_scan_non_heap_roots);
}
}
if (trace_metadata) {
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::WaitForStrongCLD, worker_i);
// Barrier to make sure all workers passed
// the strong CLD and strong nmethods phases.
wait_until_all_strong_classes_discovered();
}
// Now take the complement of the strong CLDs.
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::WeakCLDRoots, worker_i);
ClassLoaderDataGraph::roots_cld_do(NULL, scan_weak_clds);
} else {
phase_times->record_time_secs(G1GCPhaseTimes::WaitForStrongCLD, worker_i, 0.0);
phase_times->record_time_secs(G1GCPhaseTimes::WeakCLDRoots, worker_i, 0.0);
}
// Finish up any enqueued closure apps (attributed as object copy time).
buf_scan_non_heap_roots.done();
buf_scan_non_heap_weak_roots.done();
double obj_copy_time_sec = buf_scan_non_heap_roots.closure_app_seconds()
+ buf_scan_non_heap_weak_roots.closure_app_seconds();
phase_times->record_time_secs(G1GCPhaseTimes::ObjCopy, worker_i, obj_copy_time_sec);
double ext_root_time_sec = os::elapsedTime() - ext_roots_start - obj_copy_time_sec;
phase_times->record_time_secs(G1GCPhaseTimes::ExtRootScan, worker_i, ext_root_time_sec);
// During conc marking we have to filter the per-thread SATB buffers
// to make sure we remove any oops into the CSet (which will show up
// as implicitly live).
{
// 在混合回收的时候,把并发标记中已经失效的引用关系移除。YGC并不会执行到这里
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::SATBFiltering, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_filter_satb_buffers) && _g1h->mark_in_progress()) {
JavaThread::satb_mark_queue_set().filter_thread_buffers();
}
}
// 等待所有的任务结束
_process_strong_tasks.all_tasks_completed();
}process_java_roots
该函数主要分为两个部分:
第一部分处理强类型Java根节点,包括所有可达于线程栈帧的nmethods,它们会被应用G1RootClosures::strong_codeblobs()回调函数。该函数会遍历nmethod中的所有oop对象,并进行三个操作:
- a) 对于集合中的对象进行疏散,将其迁移到非集合区域;
- b) 对对象的oop进行修复,以反映新地址;
- c) 对对象进行标记,以标记其为活动对象。
这样,这些对象就可以在后续的标记阶段中被保留下来,并且它们所属的类不会被卸载。
第二部分处理弱类型Java根节点,包括所有只可通过代码根保留集合中的nmethods。对于这些nmethods,G1会应用G1RootClosures::weak_codeblobs()回调函数,它会遍历nmethod中的所有oop对象,并执行前两个操作(a和b),但不会将对象标记为活动对象。由于这些对象没有被标记,所以它们所属的类可能会被卸载。
处理Java根的代码逻辑如下:
src\share\vm\gc_implementation\g1\g1RootProcessor.cpp
void G1RootProcessor::process_java_roots(OopClosure* strong_roots,
CLDClosure* thread_stack_clds,
CLDClosure* strong_clds,
CLDClosure* weak_clds,
CodeBlobClosure* strong_code,
G1GCPhaseTimes* phase_times,
uint worker_i) {
assert(thread_stack_clds == NULL || weak_clds == NULL, "There is overlap between those, only one may be set");
// Iterating over the CLDG and the Threads are done early to allow us to
// first process the strong CLDs and nmethods and then, after a barrier,
// let the thread process the weak CLDs and nmethods.
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::CLDGRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_ClassLoaderDataGraph_oops_do)) {
ClassLoaderDataGraph::roots_cld_do(strong_clds, weak_clds);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::ThreadRoots, worker_i);
Threads::possibly_parallel_oops_do(strong_roots, thread_stack_clds, strong_code);
}
}void ClassLoaderDataGraph::roots_cld_do(CLDClosure* strong, CLDClosure* weak) {
for (ClassLoaderData* cld = _head; cld != NULL; cld = cld->_next) {
CLDClosure* closure = cld->keep_alive() ? strong : weak;
if (closure != NULL) {
closure->do_cld(cld);
}
}
}void Threads::possibly_parallel_oops_do(OopClosure* f, CLDClosure* cld_f, CodeBlobClosure* cf) {
// Introduce a mechanism allowing parallel threads to claim threads as
// root groups. Overhead should be small enough to use all the time,
// even in sequential code.
SharedHeap* sh = SharedHeap::heap();
// Cannot yet substitute active_workers for n_par_threads
// because of G1CollectedHeap::verify() use of
// SharedHeap::process_roots(). n_par_threads == 0 will
// turn off parallelism in process_roots while active_workers
// is being used for parallelism elsewhere.
bool is_par = sh->n_par_threads() > 0;
assert(!is_par ||
(SharedHeap::heap()->n_par_threads() ==
SharedHeap::heap()->workers()->active_workers()), "Mismatch");
int cp = SharedHeap::heap()->strong_roots_parity();
ALL_JAVA_THREADS(p) {
if (p->claim_oops_do(is_par, cp)) {
p->oops_do(f, cld_f, cf);
}
}
VMThread* vmt = VMThread::vm_thread();
if (vmt->claim_oops_do(is_par, cp)) {
vmt->oops_do(f, cld_f, cf);
}
}process_vm_roots
这个函数是 G1 垃圾收集器中的可达性分析的一部分,用于处理 VM 根节点。
在 Java 虚拟机中,VM 根节点包括堆中的静态变量、常量池中的引用、本地代码中的 JNI 引用和 Java 线程的栈中的引用。在 G1 垃圾收集器中,这些根节点被保存在不同的数据结构中,例如 VM 栈、JNI 引用表和类静态变量表中。
具体地,这个函数使用一个 OopClosure 对象(closures->strong_oops())来处理所有强引用类型的根节点,包括类静态变量、JNI 引用和 Java 线程的栈中的引用。函数使用一个 OopStorageSet 对象(_oop_storage_set_strong_par_state)来访问 VM 栈中的引用。
对于 VM 栈中的引用,函数通过遍历 EnumRangeOopStorageSet::StrongId() 中的所有 StrongId,来访问 OopStorageSet 中的所有 Strong 根节点。对于每个 Strong 根节点,函数会使用 OopStorageSet::oops_do() 方法来遍历并处理其中的所有对象引用。这个过程中,使用的 OopClosure 对象是 closures->strong_oops()。
这个函数的主要作用是遍历并处理所有强引用类型的根节点,以便找到所有存活的对象。在 GC 过程中,G1 垃圾收集器会遍历并处理所有根节点,并在此基础上,进行可达性分析,以确定哪些对象是存活的。
void G1RootProcessor::process_vm_roots(OopClosure* strong_roots,
OopClosure* weak_roots,
G1GCPhaseTimes* phase_times,
uint worker_i) {
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::UniverseRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_Universe_oops_do)) {
Universe::oops_do(strong_roots);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::JNIRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_JNIHandles_oops_do)) {
JNIHandles::oops_do(strong_roots);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::ObjectSynchronizerRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_ObjectSynchronizer_oops_do)) {
ObjectSynchronizer::oops_do(strong_roots);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::FlatProfilerRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_FlatProfiler_oops_do)) {
FlatProfiler::oops_do(strong_roots);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::ManagementRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_Management_oops_do)) {
Management::oops_do(strong_roots);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::JVMTIRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_jvmti_oops_do)) {
JvmtiExport::oops_do(strong_roots);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::SystemDictionaryRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_SystemDictionary_oops_do)) {
SystemDictionary::roots_oops_do(strong_roots, weak_roots);
}
}
}
process_string_table_roots
void G1RootProcessor::process_string_table_roots(OopClosure* weak_roots, G1GCPhaseTimes* phase_times,
uint worker_i) {
assert(weak_roots != NULL, "Should only be called when all roots are processed");
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::StringTableRoots, worker_i);
// All threads execute the following. A specific chunk of buckets
// from the StringTable are the individual tasks.
StringTable::possibly_parallel_oops_do(weak_roots);
}process_code_cache_roots
void G1RootProcessor::process_code_cache_roots(CodeBlobClosure* code_closure,
G1GCPhaseTimes* phase_times,
uint worker_i) {
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_CodeCache_oops_do)) {
CodeCache::blobs_do(code_closure);
}
}
在Java根中处理Klass的部分比较简单,主要通过G1KlassScanClosure::do_klass完成,代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1CollectedHeap.cpp
void G1KlassScanClosure::do_klass(Klass* klass) {
if (!_process_only_dirty || klass->has_modified_oops()) {
klass->clear_modified_oops();
_closure->set_scanned_klass(klass);
// 通过G1ParCopyHelper来把活跃的对象复制到新的分区中
klass->oops_do(_closure);
_closure->set_scanned_klass(NULL);
}
_count++;
}Java的栈处理通过静态函数Threads::possibly_parallel_oops_do遍历所有的Java线程和VMThread线程,代码如下所示:
hotspot/src/share/vm/runtime/thread.cpp
void Threads::possibly_parallel_oops_do(OopClosure* f, CLDClosure* cld_f, CodeBlobClosure* cf) {
……
ALL_JAVA_THREADS(p) {
if (p->claim_oops_do(is_par, cp)) {
p->oops_do(f, cld_f, cf);
}
}
VMThread* vmt = VMThread::vm_thread();
if (vmt->claim_oops_do(is_par, cp)) {
vmt->oops_do(f, cld_f, cf);
}
}下面是Java线程遍历的代码:
hotspot/src/share/vm/runtime/thread.cpp
void JavaThread::oops_do(OopClosure* f, CLDClosure* cld_f, CodeBlobClosure* cf) {
Thread::oops_do(f, cld_f, cf);
// 处理JNI本地代码栈
active_handles()->oops_do(f)
// 以及JVM内部本地方法栈
handle_area()->oops_do(f);
if (has_last_Java_frame()) {
// Record JavaThread to GC thread
RememberProcessedThread rpt(this);
// privileged_stack用于实现Java安全功能的类
if (_privileged_stack_top != NULL) {
_privileged_stack_top->oops_do(f);
}
if (_array_for_gc != NULL) {
for (int index = 0; index < _array_for_gc->length(); index++) {
f->do_oop(_array_for_gc->adr_at(index));
}
}
// 遍历Monitor块
for (MonitorChunk* chunk = monitor_chunks(); chunk != NULL; chunk =
chunk->next()) {
chunk->oops_do(f);
}
// 遍历栈
for(StackFrameStream fst(this); !fst.is_done(); fst.next()) {
fst.current()->oops_do(f, cld_f, cf, fst.register_map());
}
}
// 遍历jvmti
GrowableArray<jvmtiDeferredLocalVariableSet*>* list = deferred_locals();
if (list != NULL) {
for (int i = 0; i < list->length(); i++) {
list->at(i)->oops_do(f);
}
}
// 遍历这些实例对象,这些对象可能也引用了堆对象
f->do_oop((oop*) &_threadObj);
f->do_oop((oop*) &_vm_result);
f->do_oop((oop*) &_exception_oop);
f->do_oop((oop*) &_pending_async_exception);
if (jvmti_thread_state() != NULL) {
jvmti_thread_state()->oops_do(f);
}
}重点关注一下Java栈的遍历,对不同类型的栈帧处理不同,我们只看一下解释型栈帧的处理,代码如下所示:
hotspot/src/share/vm/runtime/frame.cpp
void frame::oops_interpreted_arguments_do(Symbol* signature, bool has_receiver, OopClosure* f) {
InterpretedArgumentOopFinder finder(signature, has_receiver, this, f);
finder.oops_do();
}
void InterpretedArgumentOopFinder::oop_offset_do() {
oop* addr;
addr = (oop*)_fr->interpreter_frame_tos_at(_offset);
_f->do_oop(addr);
}其中f为G1ParCopyClosure实例化的对象,它的真正工作在do_oop_work,用于把对象复制到新的分区(Survivor或者老生代分区)。在这里就会用到对象头的信息了,当发现对象需要被复制,先复制对象到新的位置,复制之后把老对象(对象老位置的引用)的对象头标记为11,然后把对象头里面的指针指向新的对象(对象新位置的引用)。这样当一个对象被多个对象引用时,只有第一次遍历对象时候才需要复制,后续都不需要复制了,直接通过这个指针就能找到新的对象,后面的重复引用直接修改自己的指针指向新的对象就完成了遍历。代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1CollectedHeap.cpp
void G1ParCopyClosure<barrier, do_mark_object>::do_oop_work(T* p) {
T heap_oop = oopDesc::load_heap_oop(p);
if (oopDesc::is_null(heap_oop)) return;
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
const InCSetState state = _g1->in_cset_state(obj);
if (state.is_in_cset()) {
oop forwardee;
markOop m = obj->mark();
// 对象是否已经复制完成
if (m->is_marked()) {
// 如果完成,直接找到新的对象
forwardee = (oop) m->decode_pointer();
} else {
// 如果对象还没有复制,则复制对象
forwardee = _par_scan_state->copy_to_survivor_space(state, obj, m);
}
oopDesc::encode_store_heap_oop(p, forwardee);
if (do_mark_object != G1MarkNone && forwardee != obj) {
// 如果对象成功复制,把新对象的地址设置到老对象的对象头
mark_forwarded_object(obj, forwardee);
}
if (barrier == G1BarrierKlass) {
do_klass_barrier(p, forwardee);
}
} else {
// 对于不在CSet中的对象,先把对象标记为活的,在并发标记的时候作为根对象
if (state.is_humongous()) {
_g1->set_humongous_is_live(obj);
}
if (do_mark_object == G1MarkFromRoot) {
mark_object(obj);
}
}
if (barrier == G1BarrierEvac) {
// 如果是Evac失败情况,则需要将对象记录到一个特殊的队列中,在最后Redirty时需要
// 重构RSet
_par_scan_state->update_rs(_from, p, _worker_id);
}
}我们简单看一下对象复制的具体实现,代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1ParScanThreadState.cpp
oop G1ParScanThreadState::copy_to_survivor_space(InCSetState const state,
oop const old,
markOop const old_mark) {
const size_t word_sz = old->size();
HeapRegion* const from_region = _g1h->heap_region_containing_raw(old);
const int young_index = from_region->young_index_in_cset()+1;
uint age = 0;
/*判断对象是要到Survivor还是到Old区,判断的依据是根据对象age。
这里的AgeTable是一个数组,描述不同age所用到的总空间。当发现
对象超过晋升的阈值或者Survivor不能存放的时候需要把对象晋升到老生代分区。*/
InCSetState dest_state = next_state(state, old_mark, age);
// 使用PLAB方法直接在PLAB中分配新的对象
HeapWord* obj_ptr = _g1_par_allocator->plab_allocate(dest_state, word_sz,
context);
if (obj_ptr == NULL) {
/*如果分配失败,则尝试分配一个PLAB或者直接在堆中分配对象。这里和TLAB类似,
先计算是否需要分配一个新的PLAB,也是由参数控制。对于新生代分区,PLAB的大
小为16KB(32位JVM),由YoungPLABSize控制;对于老生代PLAB的大小为4KB(32位JVM)
由OldPLABSize控制。还有一个参数,由ParallelGCBufferWastePct控制,表示PLAB浪费的比例,
当PLAB剩余的空间小于PLABSize×10%,即1634或者409个字节(根据目标是在Survivor还是
老生代分区),可以分配一个新的PLAB,否则直接在堆中分配。同样的道理如果要分配一个
新的PLAB的时候,需要把PLAB里面碎片部分填充为dummy对象。*/
obj_ptr = _g1_par_allocator->allocate_direct_or_new_plab(dest_state,
word_sz, context);
if (obj_ptr == NULL) {
// 仍然失败,如果此次尝试是在Survivor中,则再次尝试在老生代分区分配,如果此次尝试为
// 在老生代分区分配,则直接报错,因为上面已经尝试过了
obj_ptr = allocate_in_next_plab(state, &dest_state, word_sz, context);
if (obj_ptr == NULL) {
// 还是失败,说明无法复制对象,需要把对象头设置为自己
return _g1h->handle_evacuation_failure_par(this, old);
}
}
}
……
const oop obj = oop(obj_ptr);
const oop forward_ptr = old->forward_to_atomic(obj);
if (forward_ptr == NULL) {
/*对象头里面没有指针,说明这是第一次复制,注意这里的复制是内存的完全复制,所以复制后引用关系不变,相当于对被引用者多了一个新的引用*/
Copy::aligned_disjoint_words((HeapWord*) old, obj_ptr, word_sz);
// 更新age信息和对象头
if (dest_state.is_young()) {
if (age < markOopDesc::max_age) {
age++;
}
if (old_mark->has_displaced_mark_helper()) {
/*对于重量级锁,前面的ptr指向的是Monitor对象,其中ObjectMonitor的第一个字段是oopDes,所以要先设置old mark再获得Monitor,最后再更新age */
obj->set_mark(old_mark);
markOop new_mark = old_mark->displaced_mark_helper()->set_age(age);
old_mark->set_displaced_mark_helper(new_mark);
} else {
obj->set_mark(old_mark->set_age(age));
}
age_table()->add(age, word_sz);
} else {
obj->set_mark(old_mark);
}
// 把字符串对象送入字符串去重的队列,由去重线程处理。具体参见第9章
if (G1StringDedup::is_enabled()) {
G1StringDedup::enqueue_from_evacuation(…);
}
size_t* const surv_young_words = surviving_young_words();
surv_young_words[young_index] += word_sz;
/*如果对象是一个对象类型的数组,即数组里面的元素都是一个对象而不是原始值,并且它的长度超过阈值ParGCArrayScanChunk(默认值为50),则可以先把它放入到队列中而不是放入到深度搜索的对象栈中。目的是为了防止在遍历对象数组里面的每一个元素时因为数组太长而导致处理队列溢出。所以这里只是把原始对象放入,后续还会继续处理*/
if (obj->is_objArray() && arrayOop(obj)->length() >= ParGCArrayScanChunk) {
arrayOop(obj)->set_length(0);
oop* old_p = set_partial_array_mask(old);
push_on_queue(old_p);
} else {
HeapRegion* const to_region = _g1h->heap_region_containing_raw(obj_ptr);
_scanner.set_region(to_region);
// 把obj的每一个Field对象都通过scanner
obj->oop_iterate_backwards(&_scanner);
// oop_iterate_backwards方法实际上是一个宏,定义在oopDesc::oop_iterate_
// backwards,在这里最终会调用到klass()->oop_oop_iterate_backwards##nv_
// suffix(this, blk)
}
return obj;
} else {
// 已经分配过了,则不需要重复分配
_g1_par_allocator->undo_allocation(dest_state, obj_ptr, word_sz, context);
return forward_ptr;
}
}最后我们再看一下如何处理obj的每一个field,将所有的field都放入到待处理的队列中。触发的位置在obj->oop_iterate_backwards(&_scanner),真正的工作在G1ParScanClosure中,代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1OopClosures.inline.hpp
template <class T> inline void G1ParScanClosure::do_oop_nv(T* p) {
T heap_oop = oopDesc::load_heap_oop(p);
if (!oopDesc::is_null(heap_oop)) {
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
const InCSetState state = _g1->in_cset_state(obj);
if (state.is_in_cset()) {
// 如果f ield需要回收,即在CSet中,放入队列,准备后续复制
_par_scan_state->push_on_queue(p);
} else {
if (state.is_humongous()) {
_g1->set_humongous_is_live(obj);
}
// 如果不需要,仅仅只需要在后面重构RSet,保持引用关系
_par_scan_state->update_rs(_from, p, _worker_id);
}
}
}2.RSet处理
RSet处理的入口在G1RootProcessor::scan_remembered_sets
src\share\vm\gc_implementation\g1\g1RootProcessor.cpp
void G1RootProcessor::scan_remembered_sets(G1ParPushHeapRSClosure* scan_rs,
OopClosure* scan_non_heap_weak_roots,
uint worker_i) {
G1GCPhaseTimes* phase_times = _g1h->g1_policy()->phase_times();
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::CodeCacheRoots, worker_i);
// Now scan the complement of the collection set.
G1CodeBlobClosure scavenge_cs_nmethods(scan_non_heap_weak_roots);
_g1h->g1_rem_set()->oops_into_collection_set_do(scan_rs, &scavenge_cs_nmethods, worker_i);
}
scan_remembered_sets会调用G1RemSet::oops_into_collection_set_do,它的工作是更新RSet和扫描RSet。代码如下所示:
src\share\vm\gc_implementation\g1\g1RemSet.cpp
void G1RemSet::oops_into_collection_set_do(G1ParPushHeapRSClosure* oc,
CodeBlobClosure* code_root_cl,
uint worker_i) {
#if CARD_REPEAT_HISTO
ct_freq_update_histo_and_reset();
#endif
// We cache the value of 'oc' closure into the appropriate slot in the
// _cset_rs_update_cl for this worker
assert(worker_i < n_workers(), "sanity");
_cset_rs_update_cl[worker_i] = oc;
// A DirtyCardQueue that is used to hold cards containing references
// that point into the collection set. This DCQ is associated with a
// special DirtyCardQueueSet (see g1CollectedHeap.hpp). Under normal
// circumstances (i.e. the pause successfully completes), these cards
// are just discarded (there's no need to update the RSets of regions
// that were in the collection set - after the pause these regions
// are wholly 'free' of live objects. In the event of an evacuation
// failure the cards/buffers in this queue set are passed to the
// DirtyCardQueueSet that is used to manage RSet updates
/*这里使用的DCQ不同于JavaThread里面的DCQ,JavaThread里面的DCQ是为了记录Mutator在运行时的引用关系,而这个DCQ是为了记录GC过程中发生失败时要保留的引用关系*/
DirtyCardQueue into_cset_dcq(&_g1->into_cset_dirty_card_queue_set());
assert((ParallelGCThreads > 0) || worker_i == 0, "invariant");
updateRS(&into_cset_dcq, worker_i);
scanRS(oc, code_root_cl, worker_i);
// We now clear the cached values of _cset_rs_update_cl for this worker
_cset_rs_update_cl[worker_i] = NULL;
}
更新RSet就是把引用关系存储到RSet对应的PRT中;扫描RSet则是根据RSet的存储信息扫描找到对应的引用者,即根,注意因为RSet内部使用了3种不同粒度的存储类型,所以根的大小也会不同,简单地说这个根指的是引用者对应的内存块,这里可能是512字节也可能是一整个分区,然后根据内存块找到引用者对象。
(1)更新RSet
在第4章介绍了Refine线程处理DCQS中绿区和黄区DCQ,白区的DCQ留给GC线程处理,红区的DCQ直接在Mutator中处理。前面已经介绍了绿区、黄区和红区的处理。在YGC中会处理白区,其处理方式和Refine线程完全一样,区别就是处理的DCQ对象不同。YGC通过UpdateRS方法来更新RSet,可以看到它最终调用dcqs.apply_closure_to_completed_buffer(cl,worker_i,0,true),UpdateRS在调用时传递的第三个参数为0,表示处理所有的DCQ。代码如下:
hotspot/src/share/vm/gc_implementation/g1/g1RemSet.cpp
void G1RemSet::updateRS(DirtyCardQueue* into_cset_dcq, uint worker_i) {
G1GCParPhaseTimesTracker x(_g1p->phase_times(), G1GCPhaseTimes::UpdateRS,
worker_i);
// 使用closure处理尚未处理的DCQ
RefineRecordRefsIntoCSCardTableEntryClosure into_cset_update_rs_cl(_g1,
into_cset_dcq);
_g1->iterate_dirty_card_closure(&into_cset_update_rs_cl, into_cset_dcq,
false, worker_i);
}
void G1CollectedHeap::iterate_dirty_card_closure(CardTableEntryClosure* cl,
DirtyCardQueue* into_cset_dcq,
bool concurrent,
uint worker_i) {
// 先处理热表
G1HotCardCache* hot_card_cache = _cg1r->hot_card_cache();
hot_card_cache->drain(worker_i, g1_rem_set(), into_cset_dcq);
// 处理DCQS中剩下的DCQ
DirtyCardQueueSet& dcqs = JavaThread::dirty_card_queue_set();
size_t n_completed_buffers = 0;
while (dcqs.apply_closure_to_completed_buffer(cl, worker_i, 0, true)) {
n_completed_buffers++;
}
dcqs.clear_n_completed_buffers();
}(2)扫描RSet
扫描RSet会处理CSet中所有待回收的分区。先找到RSet中的老生代分区对象,这些对象指向CSet中的对象。然后对这些老生代对象处理,把老生代对象field指向的对象的地址放入队列中待后续处理。代码如下:
hotspot/src/share/vm/gc_implementation/g1/g1RemSet.cpp
void G1RemSet::scanRS(…) {
// 在这里可以看出每个GC线程都只会针对部分的分区处理,这也就是为什么它们之间能够并行
// 运行的原因
HeapRegion *startRegion = _g1->start_cset_region_for_worker(worker_i);
ScanRSClosure scanRScl(oc, code_root_cl, worker_i);
// 第一次扫描,处理一般对象
_g1->collection_set_iterate_from(startRegion, &scanRScl);
// 第二次扫描,处理代码对象
scanRScl.set_try_claimed();
_g1->collection_set_iterate_from(startRegion, &scanRScl);
}对所有需要本线程处理的堆分区,逐一处理,代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1CollectedHeap.cpp
void G1CollectedHeap::collection_set_iterate_from(
HeapRegion* r, HeapRegionClosure *cl) {
// 处理本线程的第一个分区
HeapRegion* cur = r;
while (cur != NULL) {
HeapRegion* next = cur->next_in_collection_set();
if (cl->doHeapRegion(cur) && false) {
cl->incomplete();
return;
}
cur = next;
}
// 如果本线程已经处理完属于自己处理的分区,窃取其他线程待处理的分区
cur = g1_policy()->collection_set();
while (cur != r) {
HeapRegion* next = cur->next_in_collection_set();
if (cl->doHeapRegion(cur) && false) {
cl->incomplete();
return;
}
cur = next;
}
}每一个分区的处理过程在ScanRSClosure::doHeapRegion中,它最主要的功能就是找到引用者分区并扫描分区,代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1RemSet.cpp
bool ScanRSClosure::doHeapRegion(HeapRegion* r) {
HeapRegionRemSet* hrrs = r->rem_set();
if (hrrs->iter_is_complete()) return false; // All done.
if (!_try_claimed && !hrrs->claim_iter()) return false;
_g1h->push_dirty_cards_region(r);
HeapRegionRemSetIterator iter(hrrs);
size_t card_index;
/*这里_block_size由参数G1RSetScanBlockSize控制,默认值为64。
这个值表示一次扫描多少个分区块,这个值是为了提高效率,越大说
明扫描的吞吐量越大。例如RSet是细粒度PRT表存储,则一次处理64个元素。*/
size_t jump_to_card = hrrs->iter_claimed_next(_block_size);
for (size_t current_card = 0; iter.has_next(card_index); current_card++) {
if (current_card >= jump_to_card + _block_size) {
jump_to_card = hrrs->iter_claimed_next(_block_size);
}
if (current_card < jump_to_card) continue;
HeapWord* card_start = _g1h->bot_shared()->address_for_index(card_index);
// 找引用者的分区地址,注意这里不是引用者的对象地址,因为此时也找不到对象地址
HeapRegion* card_region = _g1h->heap_region_containing(card_start);
_cards++;
// 只有引用者分区不在CSet才需要扫描,因为这里是处理RSet根,在CSet的分区肯定会被
// 回收。如果引用者还没有被处理,则处理这个分区
if (!card_region->in_collection_set() && !_ct_bs->is_card_dirty(card_index)) {
scanCard(card_index, card_region);
}
}
if (!_try_claimed) {
// 处理编译的代码。这里不详细展开,在日志分析中有例子演示为什么需要处理代码
scan_strong_code_roots(r);
hrrs->set_iter_complete();
}
return false;
}引用者分区处理的思路,是找到卡表所在的区域,因为RSet中存储的是对象起始地址所对应的卡表地址,所以肯定可以找到对象。但是这个卡表对应512个字节的区域,而区域可能有多个对象,这个时候就会可能产生浮动垃圾。scancard代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1RemSet.cpp
void ScanRSClosure::scanCard(size_t index, HeapRegion *r) {
HeapRegionDCTOC cl(_g1h, r, _oc, CardTableModRefBS::Precise);
_oc->set_region(r);
MemRegion card_region(_bot_shared->address_for_index(index),
G1BlockOffsetSharedArray::N_words);
MemRegion pre_gc_allocated(r->bottom(), r->scan_top());
MemRegion mr = pre_gc_allocated.intersection(card_region);
if (!mr.is_empty() && !_ct_bs->is_card_claimed(index)) {
_ct_bs->set_card_claimed(index);
_cards_done++;
cl.do_MemRegion(mr);
}
}对这个内存块扫描,它通过DirtyCardToOopClosure::do_MemRegion调用HeapRegionDCTOC::walk_mem_region,代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/heapRegion.cpp
void HeapRegionDCTOC::walk_mem_region(MemRegion mr,
HeapWord* bottom,
HeapWord* top) {
G1CollectedHeap* g1h = _g1;
size_t oop_size;
HeapWord* cur = bottom;
/*从内存块所在的分区的头部(第一个字节)开始处理,
注意这里bottom已经指向mr中第一个对象的地址,
top是最后一个对象的地址。从这个循环也可以看出,
这里主要是为遍历这512字节里面所有的对象*/
if (!g1h->is_obj_dead(oop(cur), _hr)) {
oop_size = oop(cur)->oop_iterate(_rs_scan, mr);
} else {
oop_size = _hr->block_size(cur);
}
cur += oop_size;
if (cur < top) {
oop cur_oop = oop(cur);
oop_size = _hr->block_size(cur);
HeapWord* next_obj = cur + oop_size;
while (next_obj < top) {
// Keep filtering the remembered set.
if (!g1h->is_obj_dead(cur_oop, _hr)) {
cur_oop->oop_iterate(_rs_scan);
}
cur = next_obj;
cur_oop = oop(cur);
oop_size = _hr->block_size(cur);
// 这里就是为什么需要对TLAB、PLAB填充dummy对象的原因,也是需要heap parsable
// 的原因
next_obj = cur + oop_size;
}
// 最后一个对象,注意这个对象的起始地址在这个内存块中,
// 结束位置有可能跨内存块,这就是为什么最后一个对象要特殊处理
if (!g1h->is_obj_dead(oop(cur), _hr)) {
oop(cur)->oop_iterate(_rs_scan, mr);
}
}
}此处oop_iterate将遍历这个引用者的每一个field,当发现field指向的对象(即被引用者)在CSet中则把对象放入队列中,如果不在则跳过这个field,代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1OopClosures.inline.hpp
template <class T> inline void G1ParPushHeapRSClosure::do_oop_nv(T* p) {
T heap_oop = oopDesc::load_heap_oop(p);
if (!oopDesc::is_null(heap_oop)) {
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
if (_g1->is_in_cset_or_humongous(obj)) {
_par_scan_state->push_on_queue(p);
}
}
}为什么有is_in_cset_or_humongous这样的判断,仅仅处理被引用者在CSet的情况?因为field引用的对象不在CSet说明它不会被回收,也就不涉及位置变化。另外要注意这里放入队列中的对象和Java根处理有点不同,Java根处理的时候对根的直接引用对象会复制到新的分区,但是这里仅仅是把指向field对象的地址放入队列中。这种处理方式的不同在于对Java根的处理发生了复制,在后续不需要再次遍历这些根。为了更清晰地说明这部分逻辑,通过图5-2进一步解释。
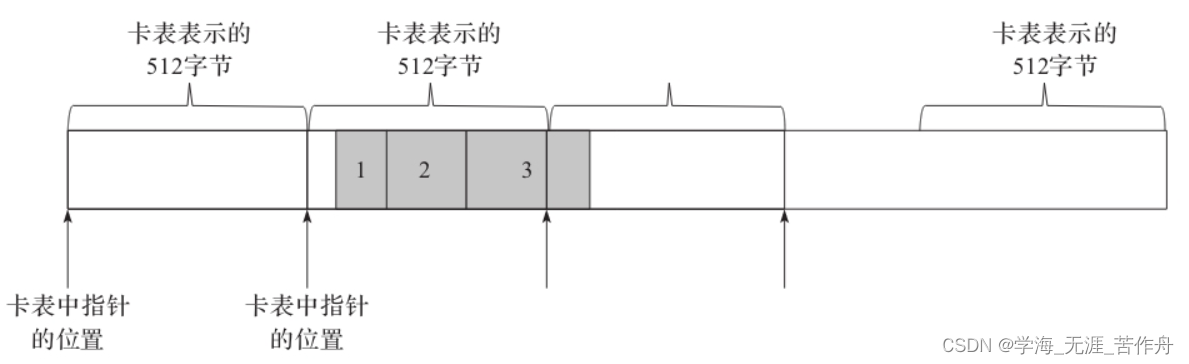
图5-2中描述了一个分区的大小,我们知道每个分区里面的引用关系通过RSet的形式来存储。其中RSet里面的每一个PRT存储的就是对应卡表的位置(即指针)。在图中我们假设对象1、2、3分配连续图中第2个卡表所指向的内存。由于卡表是按照512字节对齐,所以对象1、2、3的卡表指针是相同的。当对象1、2、3之一引用到新生代的对象时,在新生代里面的PRT都只能找到图中第2个卡表的起始位置。而这个卡表指针不能明确地说明是对象1、2或者3,所以当通过RSet找引用者的时候,这个指针只能理解为对象1、2、3都可能引用到生代了。
另外需要注意一点,图中第2个卡表所指向的512字节可能被前一个对象占用一部分,但这并不影响对象1、2、3的卡表位置,因为对象1、2、3的地址都会按照512对齐。针对这一情况,要找的新生代准确的引用者,必须有以下两步:
·先找到对象1的起始位置,有两种方案,第一是从整个分区的头部开始扫描,然后针对每一个对象将地址对齐到卡表,跳过所有不在这个卡表的对象。第二种方案是借助额外的数据结构来标记对象所在块的起始位置,G1中使用了G1BlockOffsetTable来记录。
·遍历从第一个对象到最后一个对象为止,查找对象1、2、3所有的field是否都有到待回收分区的引用,如果有,说明该field是一个有效地引用,把该field放入到待处理队列用于后续的遍历和复制。
G1BlockOffsetTable内部也是用类似位图来存储第一个对象距离卡表起始位置的偏移量,在内部使用的字符数组来存储。我们知道512字节如果在32位机器中就是128个字,而一个字符的范围是0~255,所以足够存储了。另外当一个对象非常大的时候,超过了一个卡表的空间,为了让后续的卡表能够快速地找到对象所在的第一个卡表的位置,所以设计了复杂的滑动窗口机制,这里不再介绍。
3.复制
接下来就进入到复制Evac处理。这个处理实际上就是将在Java根和RSet根找到的子对象全部复制到新的分区中。入口在G1ParEvacuateFollowersClosure::do_void,代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1CollectedHeap.cpp
class G1ParEvacuateFollowersClosure : public VoidClosure {
protected:
G1CollectedHeap* _g1h;
G1ParScanThreadState* _par_scan_state;
RefToScanQueueSet* _queues;
ParallelTaskTerminator* _terminator;
G1ParScanThreadState* par_scan_state() { return _par_scan_state; }
RefToScanQueueSet* queues() { return _queues; }
ParallelTaskTerminator* terminator() { return _terminator; }
public:
G1ParEvacuateFollowersClosure(G1CollectedHeap* g1h,
G1ParScanThreadState* par_scan_state,
RefToScanQueueSet* queues,
ParallelTaskTerminator* terminator)
: _g1h(g1h), _par_scan_state(par_scan_state),
_queues(queues), _terminator(terminator) {}
void do_void();
private:
inline bool offer_termination();
};
bool G1ParEvacuateFollowersClosure::offer_termination() {
G1ParScanThreadState* const pss = par_scan_state();
pss->start_term_time();
const bool res = terminator()->offer_termination();
pss->end_term_time();
return res;
}
void G1ParEvacuateFollowersClosure::do_void() {
G1ParScanThreadState* const pss = par_scan_state();
// 处理刚才插入队列的每一个对象
pss->trim_queue();
do {
// 线程处理完了,可以尝试去窃取别的线程还没有处理的对象
pss->steal_and_trim_queue(queues());
} while (!offer_termination());
}具体的处理我们看一下G1ParScanThreadState::trim_queue。这个函数就是把每一个待处理的对象拿出来处理。代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1ParScanThreadState.cpp
void G1ParScanThreadState::trim_queue() {
StarTask ref;
do {
// 取出每一个对象,处理
while (_refs->pop_overflow(ref)) {
if (!_refs->try_push_to_taskqueue(ref)) {
dispatch_reference(ref);
}
}
while (_refs->pop_local(ref)) {
dispatch_reference(ref);
}
} while (!_refs->is_empty());
}dispatch_reference会根据不同的对象,做不同的处理,最终会调用deal_with_reference,代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1ParScanThreadState.inline.hpp
template <class T> inline void G1ParScanThreadState::deal_with_reference
(T* ref_to_scan) {
if (!has_partial_array_mask(ref_to_scan)) {
// 这是对一般对象处理
HeapRegion* r = _g1h->heap_region_containing_raw(ref_to_scan);
do_oop_evac(ref_to_scan, r);
} else {
// 这里就是我们在前面提到的如果待处理对象是对象数组,并且长度比较大,设置特殊的标志位,待处理
do_oop_partial_array((oop*)ref_to_scan);
}
}
inline void G1ParScanThreadState::dispatch_reference(StarTask ref) {
assert(verify_task(ref), "sanity");
if (ref.is_narrow()) {
deal_with_reference((narrowOop*)ref);
} else {
deal_with_reference((oop*)ref);
}
}真正的处理工作在do_oop_evac,代码如下所示:
template <class T> void G1ParScanThreadState::do_oop_evac(T* p, HeapRegion* from) {
assert(!oopDesc::is_null(oopDesc::load_decode_heap_oop(p)),
"Reference should not be NULL here as such are never pushed to the task queue.");
// 注意这里传递的参数为*p,其实是引用者中field的地址
oop obj = oopDesc::load_decode_heap_oop_not_null(p);
// Although we never intentionally push references outside of the collection
// set, due to (benign) races in the claim mechanism during RSet scanning more
// than one thread might claim the same card. So the same card may be
// processed multiple times. So redo this check.
const InCSetState in_cset_state = _g1h->in_cset_state(obj);
if (in_cset_state.is_in_cset()) {
oop forwardee;
markOop m = obj->mark();
if (m->is_marked()) {
// 如果对象已经标记,说明对象已经被复制
forwardee = (oop) m->decode_pointer();
} else {
// 如果对象没有标记,复制对象到新的分区
forwardee = copy_to_survivor_space(in_cset_state, obj, m);
}
// 更新引用者field所引用对象的地址
oopDesc::encode_store_heap_oop(p, forwardee);
} else if (in_cset_state.is_humongous()) {
_g1h->set_humongous_is_live(obj);
} else {
assert(!in_cset_state.is_in_cset_or_humongous(),
err_msg("In_cset_state must be NotInCSet here, but is " CSETSTATE_FORMAT, in_cset_state.value()));
}
assert(obj != NULL, "Must be");
// 最后要维护一下新生成对象的RSet
update_rs(from, p, queue_num());
}如果一切顺利,在CSet中所有活跃的对象都将被复制到新的分区中,并且在复制的过程中,引用关系也随之处理。
oop G1ParScanThreadState::copy_to_survivor_space(InCSetState const state,
oop const old,
markOop const old_mark) {
const size_t word_sz = old->size();
HeapRegion* const from_region = _g1h->heap_region_containing_raw(old);
// +1 to make the -1 indexes valid...
const int young_index = from_region->young_index_in_cset()+1;
assert( (from_region->is_young() && young_index > 0) ||
(!from_region->is_young() && young_index == 0), "invariant" );
const AllocationContext_t context = from_region->allocation_context();
uint age = 0;
InCSetState dest_state = next_state(state, old_mark, age);
HeapWord* obj_ptr = _g1_par_allocator->plab_allocate(dest_state, word_sz, context);
// PLAB allocations should succeed most of the time, so we'll
// normally check against NULL once and that's it.
if (obj_ptr == NULL) {
obj_ptr = _g1_par_allocator->allocate_direct_or_new_plab(dest_state, word_sz, context);
if (obj_ptr == NULL) {
obj_ptr = allocate_in_next_plab(state, &dest_state, word_sz, context);
if (obj_ptr == NULL) {
// This will either forward-to-self, or detect that someone else has
// installed a forwarding pointer.
return _g1h->handle_evacuation_failure_par(this, old);
}
}
if (_g1h->_gc_tracer_stw->should_report_promotion_events()) {
// The events are checked individually as part of the actual commit
report_promotion_event(dest_state, old, word_sz, age, obj_ptr, context);
}
}
assert(obj_ptr != NULL, "when we get here, allocation should have succeeded");
#ifndef PRODUCT
// Should this evacuation fail?
if (_g1h->evacuation_should_fail()) {
// Doing this after all the allocation attempts also tests the
// undo_allocation() method too.
_g1_par_allocator->undo_allocation(dest_state, obj_ptr, word_sz, context);
return _g1h->handle_evacuation_failure_par(this, old);
}
#endif // !PRODUCT
// We're going to allocate linearly, so might as well prefetch ahead.
Prefetch::write(obj_ptr, PrefetchCopyIntervalInBytes);
const oop obj = oop(obj_ptr);
const oop forward_ptr = old->forward_to_atomic(obj);
if (forward_ptr == NULL) {
Copy::aligned_disjoint_words((HeapWord*) old, obj_ptr, word_sz);
if (dest_state.is_young()) {
if (age < markOopDesc::max_age) {
age++;
}
if (old_mark->has_displaced_mark_helper()) {
// In this case, we have to install the mark word first,
// otherwise obj looks to be forwarded (the old mark word,
// which contains the forward pointer, was copied)
obj->set_mark(old_mark);
markOop new_mark = old_mark->displaced_mark_helper()->set_age(age);
old_mark->set_displaced_mark_helper(new_mark);
} else {
obj->set_mark(old_mark->set_age(age));
}
age_table()->add(age, word_sz);
} else {
obj->set_mark(old_mark);
}
if (G1StringDedup::is_enabled()) {
const bool is_from_young = state.is_young();
const bool is_to_young = dest_state.is_young();
assert(is_from_young == _g1h->heap_region_containing_raw(old)->is_young(),
"sanity");
assert(is_to_young == _g1h->heap_region_containing_raw(obj)->is_young(),
"sanity");
G1StringDedup::enqueue_from_evacuation(is_from_young,
is_to_young,
queue_num(),
obj);
}
size_t* const surv_young_words = surviving_young_words();
surv_young_words[young_index] += word_sz;
if (obj->is_objArray() && arrayOop(obj)->length() >= ParGCArrayScanChunk) {
// We keep track of the next start index in the length field of
// the to-space object. The actual length can be found in the
// length field of the from-space object.
arrayOop(obj)->set_length(0);
oop* old_p = set_partial_array_mask(old);
push_on_queue(old_p);
} else {
HeapRegion* const to_region = _g1h->heap_region_containing_raw(obj_ptr);
_scanner.set_region(to_region);
obj->oop_iterate_backwards(&_scanner);
}
return obj;
} else {
_g1_par_allocator->undo_allocation(dest_state, obj_ptr, word_sz, context);
return forward_ptr;
}
}
如果发生了失败,处理流程也基本类似,但是对于失败的对象要进行额外的处理,具体可见7.1节。
至此,GC线程中大部分工作已经介绍。GC继续执行将进入其他处理部分。在进入其他处理之前,我们看一下GC在处理过程中如何并行执行。
并行执行GC
·对于Java根处理来说,根对象有多个,所以分配一个数组来存储各个并行任务的状态,如_tasks=NEW_C_HEAP_ARRAY(uint,n,mtInternal),在使用的时候多个线程通过CAS获取数组中的元素来保证并行执行任务。代码如下所示:
hotspot/src/share/vm/utilities/workgroup.cpp
bool SubTasksDone::is_task_claimed(uint t) {
uint old = _tasks[t];
if (old == 0) {
old = Atomic::cmpxchg(1, &_tasks[t], 0);
}
assert(_tasks[t] == 1, "What else");
bool res = old != 0;
return res;
}·对于RSet根来说,处理的时候是根据分区来并行处理。即使老生代对象引用了多个CSet中不同的分区,也没问题,因为此时仅仅标记对象,即便一个引用对象被处理多次,也只是标记出来,所以没有问题。
·在Evac中,因为每次处理对象的时候,需要对对象进行复制,这个时候是需要多个线程使用CAS来保证串行,先把对象标记为待回收,之后才能复制,即只能有一个线程复制成功,其他线程都会重用这个新复制的对象。
提示:在Evac因为涉及对象复制,这将是非常耗时的。所以在这个阶段还提供任务窃取的功能。在并发执行的过程中,GC线程优先处理本地的队列。当本地的队列没有任务的时候,窃取别的队列的任务,帮助别的队列。实际中这一点非常有用,比如GC Root有很多,但是每个GC Root处理的对象不同,所需要的时间也不同,例如对于线程栈这个根来说,可能对象很多,而处理Universe可能比较少,当处理Universe的线程完成处理后,可以帮助线程栈的线程来处理剩下的对象,具体窃取方法也非常简单,因为Evac保证了并行执行时的冲突问题,所以从别的对象队列里面取几个待处理对象直接处理即可。
其他处理
其他处理通常是串行处理,大多是因为处理过程需要同步等待,需要独占访问临界区,通常在这一部分花费的时间都不多[插图],其他处理大部分工作是在并行工作之后完成开始(其他处理在日志里面有单独的一部分,比对本章开头的YGC顺序,可以发现有几步是发生在并行工作之前),除了几个特别的任务如Redirty,字符串去重和引用外都是串行处理。实际上GC一直致力于提高运行的效率,所以未来不排除把一些串行化处理并行化。这些串行处理的内容例如引用处理、字符串去重优化、Evac失败等在后文将有详细的介绍,对于refinement区域的调整在上一章已经介绍。这里我们只了解一下YGC是如何调整新生代大小来满足预测停顿时间。
如前所述,每次进行YGC时,会对全部的新生代分区做扫描处理。那么如何根据预测时间来控制CSet的大小?实际上这个问题在第2章中关于新生代的时候已经介绍,这里再稍微回顾一下:
- 如果在启动时设置了最大和最小新生代的大小,若最大值和最小值相等,即固定了新生代的空间,这种情况下预测时间对新生代无效。也就是说,YGC不受预测时间的控制。在这种情况下,要满足预测时间,只能调整新生代的最大值和最小值。
- 如果没有设置固定的新生代空间,即新生代空间可以自动调整,G1如何满足预测时间?答案是在初始化或者每次YGC结束后,会重新设置新生代分区的数量。这个数量是根据预测时间来设置的。逻辑如下:
- 首先计算最小分区的数目,其值为Survivor的长度+1,即每次除了Survivor外只有一个Eden分区用于数据分配;如果最小分区数目的收集都不能满足预测时间,则使用最小的分区数目。
- 计算最大分区的数目,其值为新生代最大分区数目或者除去保留空间的最大自由空间数目的较小值,然后在这个最大值和最小值之间选择一个满足预测时间的合适的值作为新生代分区的数目。
- 在这种情况下,需要选择合适的预测停顿时间来满足业务的需要。
日志解读
YGC日志
从一个Java的例子出发,代码如下:
public class Test {
private static final LinkedList<String> strings = new LinkedList<>();
public static void main(String[] args) throws Exception {
int iteration = 0;
while (true) {
for (int i = 0; i < 100; i++) {
for (int j = 0; j < 10; j++) {
strings.add(new String("String " + j));
}
}
Thread.sleep(100);
}
}
}运行程序使用的参数为:
-Xmx256M -XX:+UseG1GC -XX:+UnlockExperimentalVMOptions
-XX:G1LogLevel=finest -XX:+PrintGCTimeStamps其中,G1LogLevel是一个实验选项,需要打开-XX:+UnlockExperimentalVMOptions,打开之后能获得更为详细的日志信息,如下所示:
0.184: [GC pause (G1 Evacuation Pause) (young), 0.0182341 secs]
// 并行GC线程,一共有8个
[Parallel Time: 16.7 ms, GC Workers: 8]
/*这一行信息说明的是这8个线程开始的时间,Min表示最早开始的线程时间,Avg表示平均开始时间,Max表示的是最晚开始时间,Diff为最早和最晚的时间差。这个值越大说明线程启动时间越不均衡。线程启动的时间依赖于GC进入安全点的情况。关于安全点可以参考后文的介绍。*/
[GC Worker Start (ms): 184.2 184.2 184.2 184.3 184.3 184.4 186.1 186.1
Min: 184.2, Avg: 184.7, Max: 186.1, Diff: 1.9]
/*根处理的时间,这个时间包含了所有强根的时间,分为Java根,分别为Thread、JNI、CLDG;和JVM根下面的StringTable、Universe、JNI Handles、ObjectSynchronizer、FlatProfiler、Management、SystemDictionary、JVMTI */
[Ext Root Scanning (ms): 0.3 0.2 0.2 0.1 0.1 0.0 0.0 0.0
Min: 0.0, Avg: 0.1, Max: 0.3, Diff: 0.3, Sum: 0.8]
/*Java线程处理时间,主要是线程栈。这个时间包含了根直接引用对象的复制时间,如果根超级大,这个时间可能会增加 */
[Thread Roots (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[StringTable Roots (ms): 0.0 0.1 0.1 0.1 0.1 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.4]
[Universe Roots (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[JNI Handles Roots (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[ObjectSynchronizer Roots (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[FlatProfiler Roots (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Management Roots (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[SystemDictionary Roots (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[CLDG Roots (ms): 0.3 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.3, Diff: 0.3, Sum: 0.3]
[JVMTI Roots (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
// CodeCache Roots实际上是在处理Rset的时候的统计值,它包含下面的
// UpdateRS,ScanRS和Code Root Scanning
[CodeCache Roots (ms): 5.0 3.9 2.2 3.3 2.1 2.2 0.6 2.2
Min: 0.6, Avg: 2.7, Max: 5.0, Diff: 4.4, Sum: 21.6]
[CM RefProcessor Roots (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Wait For Strong CLD (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Weak CLD Roots (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[SATB Filtering (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
// 这个就是GC线程更新RSet的时间花费,注意这里的时间和我们在Refine里面处理RSet
// 的时间没有关系,因为它们是不同的线程处理
[Update RS (ms): 5.0 3.9 2.2 3.3 2.1 2.2 0.6 2.2
Min: 0.6, Avg: 2.7, Max: 5.0, Diff: 4.4, Sum: 21.5]
// 这里就是GC线程处理的白区中的dcq个数
[Processed Buffers: 8 8 7 8 8 7 2 4
Min: 2, Avg: 6.5, Max: 8, Diff: 6, Sum: 52]
// 扫描RSet找到被引用的对象
[Scan RS (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms): 0.0 0.0 0.0 0.0 0.0 0.1 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.1]
// 这个就是所有活着的对象(除了强根直接引用的对象,在Java根处理时会直接复制)复制
// 到新的分区花费的时间。从这里也可以看出复制基本上是最花费时间的操作。
[Object Copy (ms): 11.3 12.5 14.2 13.1 14.3 14.2 14.2 12.5
Min: 11.3, Avg: 13.3, Max: 14.3, Diff: 3.0, Sum: 106.3]
// GC线程结束的时间信息。
[Termination (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Termination Attempts: 1 1 1 1 1 1 1 1
Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 8]
// 这个是并行处理时其他处理所花费的时间,通常是由于JVM析构释放资源等
[GC Worker Other (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
// 并行GC花费的总体时间
[GC Worker Total (ms): 16.6 16.6 16.6 16.5 16.5 16.4 14.7 14.7
Min: 14.7, Avg: 16.1, Max: 16.6, Diff: 1.9, Sum: 128.7]
// GC线程结束的时间信息
[GC Worker End (ms): 200.8 200.8 200.8 200.8 200.8 200.8 200.8 200.8
Min: 200.8, Avg: 200.8, Max: 200.8, Diff: 0.0]
// 下面是其他任务部分。
// 代码扫描属于并行执行部分,包含了代码的调整和回收时间
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
// 清除卡表的时间
[Clear CT: 0.1 ms]
[Other: 1.5 ms]
// 选择CSet的时间,YGC通常是0
[Choose CSet: 0.0 ms]
// 引用处理的时间,这个时间是发现哪些引用对象可以清除,这个是可以并行处理的
[Ref Proc: 1.1 ms]
// 引用重新激活
[Ref Enq: 0.2 ms]
// 重构RSet花费的时间
[Redirty Cards: 0.1 ms]
[Parallel Redirty: 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[Redirtied Cards: 8118 7583 6892 4496 0 0 0 0
Min: 0, Avg: 3386.1, Max: 8118, Diff: 8118, Sum: 27089]
// 这个信息是是可以并行处理的,这里是线程重构RSet的数目
// 大对象处理时间
[Humongous Register: 0.0 ms]
[Humongous Total: 2]
// 这里说明有2个大对象
[Humongous Candidate: 0]
// 可回收的大对象0个
// 如果有大对象要回收,回收花费的时间,回收的个数
[Humongous Reclaim: 0.0 ms]
[Humongous Reclaimed: 0]
// 释放CSet中的分区花费的时间,有新生代的信息和老生代的信息。
[Free CSet: 0.0 ms]
[Young Free CSet: 0.0 ms]
[Non-Young Free CSet: 0.0 ms]
// GC结束后Eden从15M变成0,下一次使用的空间为21M,S从2M变成3M,整个堆从
// 23.7M变成20M
[Eden: 15.0M(15.0M)->0.0B(21.0M) Survivors: 2048.0K->3072.0K
Heap: 23.7M(256.0M)->20.0M(256.0M)]在GC日志的最后稍微提一下日志为什么需要对Code Root扫描和调整。假设我们有下面的Java代码,在实际中codeRootTest这个代码在满足一定条件之后(比如执行多次),JIT编译器会把这样的代码进行编译,这样的代码中有直接访问OOP对象的语句,如下所示:
static final MyIntHolder staticVariable = new MyIntHolder();
// 假设MyIntHolder有一个公有的int变量x
public int codeRootTest() {
return staticVariable.x;
}这样的代码很有可能翻译成这样的汇编指令:
movabs $0x7111b5108,%r10 # staticVariable oop
mov 0xc(%r10),%edx # getfield x对于这种情况当对象发生移动之后,必须重新调整代码中对象的引用位置,所以需要对Code Root进行扫描、调整,如果能释放的话还会进行释放。
大对象日志分析
G1TraceEagerReclaimHumongousObjects实验选项(默认值为false)打开后可以看到大对象的收集情况,选项包括:
-Xmx256M -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
-XX:+UnlockExperimentalVMOptions -XX:+G1TraceEagerReclaimHumongousObjects日志信息如下:
Live humongous region 0 size 4194320 start 0x00000000f0000000 length 5 with remset 8194 code roots 0 is marked 0 reclaim candidate 0 type array 0
Live humongous region 5 size 4194320 start 0x00000000f0500000 length 5 with remset 8194 code roots 0 is marked 0 reclaim candidate 0 type array 0以上日志表示0号分区、5号分区活跃的大对象分区;大小都是4M;起始地址分别是0x00000000f0000000、0x00000000f0500000;都占用5个分区;RSet更新过8194次,代码块长度为0;并有被标记;0表示不能被回收;都不是数组类型。
对象年龄日志分析
打开PrintTenuringDistribution选项可以查看对象的年龄情况,选项包括:
-Xmx256M -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
-XX:+PrintTenuringDistribution日志如下所示:
Desired survivor size 75497472 bytes, new threshold 2 (max 15)
- age 1: 68407384 bytes, 68407384 total
- age 2: 12494576 bytes, 80901960 total
- age 3: 79376 bytes, 80981336 total
- age 4: 2904256 bytes, 83885592 total
, 0.1216628 secsSurvivor的大小为75 497 472,MaxTenuringThreshold是15,此处的2表示age为2的对象都将送入到老生代分区。
这四个年龄输出指的是age分别为1,2,3,4对象的大小。
这里看一下期望Survivor大小的计算方法。G1中会根据新生代分区的数目来计算Survivor区的大小,公式为_young_list_target_length/SurvivorRatio(SurvivorRatio默认值为8),之后对这个结果取上界作为S0和S1两个分区的大小,然后,通过参数TargetSurvivorRatio(TargetSurvivorRatio默认值为50)对整个Survivor空间进行划分。期望Survivor大小就是整个空间×TargetSurvivorRatio/100,如果TargetSurvivorRatio增大,则用于下一次Survivor的空间会变大,即晋升到Old分区的概率会减少,实际上也会导致G1给Survivor分配更多的内存。
SurvivorRatio默认值为8,TargetSurvivorRatio默认值为50。从日志可以看出,MaxTenuringThreshold是15。
参数介绍和调优
本章介绍了G1如何进行新生代回收。本节总结新生代回收过程中涉及的参数,以及该如何调整参数。
- 参数ParallelGCThreads,默认值为0,表示的是并行执行GC的线程个数。G1可以根据CPU的个数自行推断线程数;GC是CPU密集型的任务,通常来说线程个数不应该超过CPU核数,一般不用设置该值。
- 在对新生代收集的过程中,如果对象在YGC发生了一定次数之后还存活,这意味着对象有很大的概率存活更长的时间,所以通常会把它晋升到老生代。而这个次数可以通过参数MaxTenuringThreshold控制,默认值是15,即发生15次YGC后,对象仍然存活,存活的对象会晋升到老生代。这个值最大只能是15。减小该值可以会把对象更早地提升到老生代。
- 参数G1RsetScanBlockSize,默认值为64,指扫描Rset时一次处理的量,其目的是为了加速处理速度;如果计算能力较强,可以增大该值。
- 参数SurvivorRatio,默认值为8,指Eden和一个Survivor分区之间的比例;减小该值,将导致Survivor分区大小变大,G1中并不会因为增大该值直接导致Eden变小,Eden是根据GC的时间来预测的。
- 参数TargetSurvivorRatio,默认值为50,表示期望Survivor的大小。增大该值,则用于下一次Survivor的空间变大,晋升到Old分区的概率会减少。
- 参数ParGCArrayScanChunk,默认值为50,表示当一个对象数组的长度超过这个阈值之后,不会一次性遍历它,而是分多次处理,每次的长度都是这个阈值,只有最后一次处理的长度在ParGCArrayScanChunk和2×ParGCArrayScanChunk之间。减小该值会减少栈溢出的情况,增大该值效率会略有提升。G1中的处理和其他的收集器略有不同,其他的收集器中当使用对象压缩指针,并且发生Evac失败时可能导致信息丢失,所以如果你在使用其他的收集器,当发生这种问题时[插图],可以-XX:-UseCompressedOops或者把ParGCArrayScanChunk设置成最大的对象数组长度,即永远都不要对对象数组分多次处理。
- 参数ResizePLAB,默认值为true,表示在垃圾回收结束后会根据内存的使用情况来调整PLAB的大小,但是目前G1中的GC线程在不同的阶段如Evac,引用处理等都会涉及内存分配,所以在PLAB的调整上是根据整体内存的使用情况进行的,这个成本比较高[插图]。因此在一些基准测试中发现禁止该选项可能有更好的效果,但这并不一定也适用于你的应用,关于PLAB效率和性能有一个bug[插图],如果使用该选项也可以进行调整并测试。关于PLAB在JDK9等后面的版本中会引入相关参数。
- 参数YoungPLABSize,默认值为4096,是新生代PLAB缓存大小。在32位JVM中PLAB为16KB,在64位JVM中为32KB,表示对象从Eden复制到Survivor时,每次请求16KB作为分配缓存,提高分配效率。增大该值可以提高分配的效率,但是可能增加内存碎片,同时可能使得S分区很快耗尽;实际调优中可以尝试先减小该值。
- 参数OldPLABSize,默认值为1024,指老生代PLAB缓存大小。在32位JVM中PLAB为4KB,64位JVM中为8KB,表示对象从Eden复制到Old时,每次请求4KB作为分配缓存,提高分配效率。增大该值可以提高分配的效率,但是可能增加内存碎片;通常来说Old分区空间更大,实际调优中可以尝试先增大该值。
- 参数ParallelGCBufferWastePct,默认值为10,表示对象从Eden到Survivor或者Old区的时候,如果剩余空间小于这个比例,且不能分配新对象时可以丢弃这个PLAB块,申请一个新的PLAB,所以这个值越大分配的效率越高,内存浪费也越严重;这个参数和TLABRefillWasteFraction类似。
- 参数G1EagerReclaimHumongousObjects,默认值为true,表示在YGC时收集大对象;有应用测试发现YGC时回收大对象会引起性能问题[插图],如果遇到可以关闭选项。
- 参数G1EagerReclaimHumongousObjectsWithStaleRefs,默认值为true,表示在YGC时判定哪些大对象分区可以收集,如果为true表示当时大对象分区RSet的引用关系数小于G1RSetSparseRegionEntries(默认值为0)可以尝试收集,如果为false则只有RSet中的引用数为0才会收集。















 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









