







InfoMap算法
详细原文地址
了解InfoMap算法之前,需要先了解最小熵原理
最小熵原理是一个无监督学习的原理,“熵”就是学习成本,而降低学习成本是我们的不懈追求,所以通过“最小化学习成本”就能够无监督地学习出很多符合我们认知的结果,这就是最小熵原理的基本理念。
H
(
P
)
=
−
∑
i
=
1
n
p
i
l
o
g
2
p
i
H(P) = -\sum_{i=1}^{n}p_ilog_2p_i
H(P)=−i=1∑npilog2pi
编码的最短平均长度就是信息熵,这其实也是无损压缩的能力极限,我们通过寻找更佳的方案去逼近这个极限,这便是最小熵。
假如我们有这么一个任务,要求我们在短时间内把下面的序列背下来:
| 雪梨 | 葡萄 | 香蕉 | 广州 | 上海 | 北京 | 杭州 | 深圳 | 123 | 654 | 798 | 963 |
|---|
序列不长,背下来不难,为了快速地形成记忆,大家的记忆思路可能是这样的:
1、前面3个水果分别是雪梨、葡萄、香蕉;
2、中间5个城市分别是广州、上海、北京、杭州、深圳;
3、后面4个数字分别是123、654、798、963。
也就是说,大家基本上都会想着按类分组记忆的思路,这样记忆效率和效果都会更好些,而最小熵系列告诉我们,“提效”、“省力”的数学描述就是熵的降低,所以一个好的分类方案,应该是满足最小熵原理的,它能够使得系统的熵降低。这便是InfoMap本质的优化目标,通过最小化熵来寻求最优的聚类方案。
层次编码
前面说了,信息熵就等价于最短编码长度,所以最小熵事实上就是在寻找更好的压缩算法。既然刚才说分组记忆效率更高,那必然对应着某种编码方法使得我们能更有效地压缩信息,这种编码方法就是层次编码。
所谓层次编码,就是我们不再用单一的编码来表示一个对象,而是用两个(也可以更多)编码的组合来表示一个对象,其中第一个编码代表对象的类别,第二个编码则代表它在类内的编号。假如同一个类的对象经常“扎堆”出现,那么层次编码就能起到压缩的作用。
| 水果 | 雪梨 | 葡萄 | 香蕉 | END | 城市 | 广州 | 上海 | 北京 | 杭州 | 深圳 | END | 数字 | 123 | 654 | 798 | 963 | END |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 000 | 001 | 010 | 011 | 000 | 001 | 001 | 010 | 011 | 100 | 101 | 000 | 011 | 001 | 010 | 011 | 100 | 000 |
层次编码方式。在同一个类别的词语前插入一个类别标记,以及在类结束处插入一个终止标记
要注意,编码要保证无损,换言之要有相应的方法解码为原始序列,为此层次编码在原始序列的基础上插入了类别标记和终止标记,其中类别标记用单独一套编码,类别内的对象以及终止标记用另一套编码,由于有了类别区分,因此不同类的对象可以用同一个编码,比如上图中“雪梨”和“上海”都可以用001编码,这样就可以使得整体的平均编码长度变小了。解码的时候,只需要读到第一个类别编码,就开始使用该类别的类内编码来识别原对象,直到出现结束符就开始新的类别编码读取,然后重复这个过程。
既然确定了这种编码方式确实是无损的,接下来就需要计算了,因为“缩短平均编码长度”的结论不能单靠直观感知,还必须有定量的计算结果。
假设已经有了特定的层次编码方案,那么我们就可以计算这种编码方案的平均编码长度了,定义下述记号
| 记号 | 含义 |
|---|---|
| p a p_a pa | 对象a的出现概率 |
| q i ↷ q_{i↷} qi↷ | 类别i的出现概率 |
根据上述编码约定,每个类别序列的出现,必然以该类别的终止标记结束,所以 q i ↷ q_{i↷} qi↷也是类别i的终止标记的出现概率。要强调的是,这里的概率都是指全局归一化的概率,也就是

由于类和类内对象使用两套不同的编码,所以可以分别计算两者的最短平均编码长度。其中,类的最短平均编码长度是
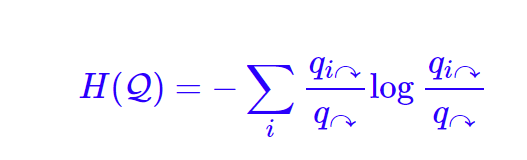
这里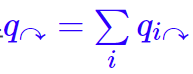
。这是因为类的编码是独立一套的,将类的概率在类间归一化后,代入熵的公式就得到类的理论上的最短平均编码长度了。
类似地,每个类i的类内对象的最短平均编码长度是
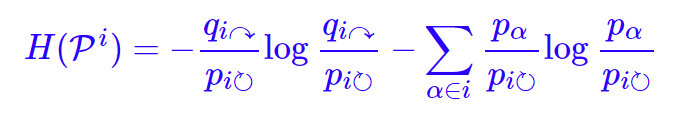
这里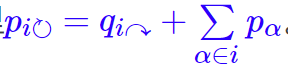
。这里要认真区分好记号,不要看错了,一旦看错将会大大增加你的理解难度。上式的含义也很清晰,每个类的类内对象都用独自的一套编码,所以连同终止标记概率在类内归一化后,代入熵的公式。
最后,将两者加权平均,就得到总的最短平均编码长度了:
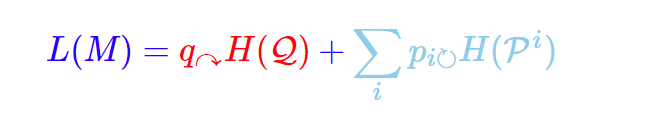
简单的理解上面这个公式:平均每步编码长度L(M)是两部分的加权和,一个是编码群组名字所需的平均字节长度,一个是编码每个群组中的节点所需的平均字节长度,权值是各自的占比。
现在,我们有了一个定量的指标L(M),可以比较两种不同的层次编码方案的优劣。反过来,有了一个对象序列后,我们可以去搜寻一个层次编码方案,使得L(M)越小越好,从而就找到了这些对象的一个聚类方案。注意这样的聚类算法几乎没有任何超参数——只需要给定对象序列,我们就可以得到该序列的层次编码,目标是L(M)最小化,这不需要事先指定聚类数目等参数(管你聚多少类,总之只要L(M)更小就行了)。
随机游走
至此,我们得到了一个优化目标L(M),在给定一个序列的情况下,我们可以通过最小化这个目标来为这个序列的对象聚类。但我们仍然还没有将它跟经典的聚类任务对应起来,因为经典的聚类问题并没有这种序列,一般只是给出了任意两个样本之间的相似度(或者给出样本本身的向量,通过这个向量也可以去算两个样本之间的某种相似度)。
所以我们可以通过随机游走得到想要的序列
InfoMap将我们要聚类的样本集抽象为一个有向图,每个样本是图上的一个点,而图上的任意两个点(α,β)都有一条β→α的边,边的权重为转移概率 p β → α p_{β→α} pβ→α。对于普通的图,图上的边一般就是代表着两个点之间的相似度,然后我们可以通过将边的权重归一化来赋予它转移概率的含义。
有了这个设定之后,一个很经典的想法——“随机游走”——就出来了:从某个点j开始,依概率p(i|j)跳转下一个点i,然后从i点出发,再依转移概率跳转到下一个点,重复这个过程。这样我们就可以得到一个很长很长的序列。有了序列之后,就能以L(M)为目标来聚类了。
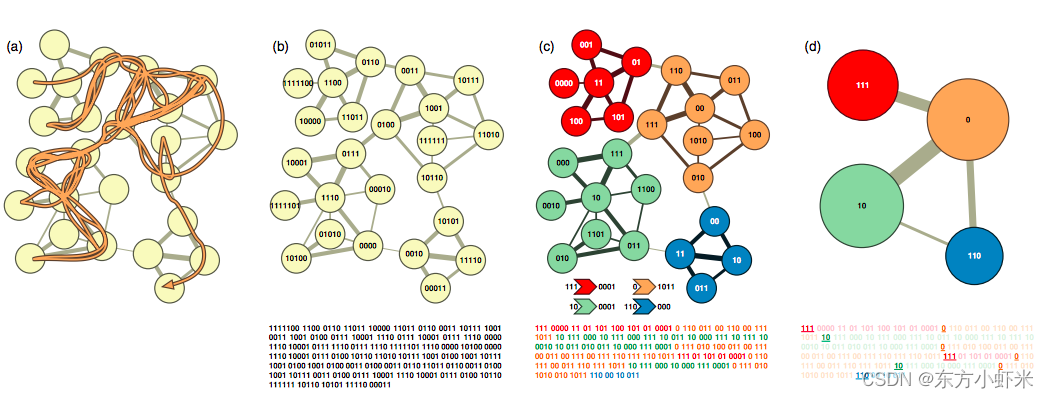
InfoMap编码与聚类过程。(a)随机游走; (b)根据随机游走的概率直接构建huffman编码; ©层次编码; (d)层次编码中的类别编码。最下方显示了对应的编码序列,可以看到层次编码的编码序列更短
这就是InfoMap的聚类过程了——通过构造转移概率,在图上进行随机游走来生成序列,在通过对序列做层次编码,最小化目标L(M),从而完成聚类。
但是,单纯这样的随机游走,结果可能会依赖于迭代的初始值,这并不难想象,假如图上有一些孤立区域,那如果游走进这些孤立区域,那就永远出不来了,导致区域以外的点的概率全都为0了。结果跟初始值有关,这是不合理的,聚类结果应该只跟图本身有关。为了解决这个问题,作者引入了“穿越概率”τ:以1−τ的概率按照pβ→α的转移概率来随机游走,以τ的概率随机选择图上任意一个点跳转。这样的话,就相当于转移概率pα→β换成了(1−τ)pα→β+τ/n。
有了穿越概率,模型一般就不会陷入某个局部解了,从而导致了解的唯一性。τ是一个额外的超参,作者取了τ=0.15
IofoMap算法
- 初始化相关参数,包括超参数随机跳转概率等,将每个节点都看作独立的社区。
- 使用随机游走对图里面的节点进行采样,得到一个序列,并且尝试按顺序把节点赋予和当前节点直接相连的邻居节点所在的社区,计算L(M)的值,并且取L(M)下降最大的那个社团作为当前节点的社团,如果L(M)没有降低,则当前节点的社区还是它本身。
- 反复进行步骤2后,直到L(M)无法继续变化。
import infomap
import collections
import networkx as nx
import networkx.algorithms as nalgos
import matplotlib.pyplot as plt
import matplotlib.colors as colors
class Graph:
graph = nx.DiGraph()
def __init__(self):
self.graph = nx.DiGraph()
def createGraph(self, filename):
file = open(filename, 'r')
for line in file.readlines():
nodes = line.split()
edge = (int(nodes[0]), int(nodes[1]))
self.graph.add_edge(*edge)
return self.graph
class Infomap:
graph = Graph()
def __init__(self, G):
self.graph = G
def findCommunities(self, G):
"""
用 InfoMap 算法划分网络。
用 "社区 "ID对节点进行注释,并返回发现的社区数量。
"""
infomapWrapper = infomap.Infomap("--two-level --directed")
network = infomapWrapper.network
print("Building Infomap network from a NetworkX graph...")
for e in G.edges():
network.addLink(*e)
print("Find communities with Infomap...")
infomapWrapper.run()
tree = infomapWrapper.iterTree()
print("Found %d modules with codelength: %f" % (infomapWrapper.numTopModules(), infomapWrapper.codelength))
# 为每个节点打上社区标签作为属性
communities = {}
for node in infomapWrapper.iterLeafNodes():
communities[node.physicalId] = node.moduleIndex()
nx.set_node_attributes(G, name='community', values=communities)
# communities = collections.defaultdict(lambda: list())
# for node in infomapWrapper.iterLeafNodes():
# communities[node.moduleIndex()].append(node.physicalId)
# print(communities)
return infomapWrapper.numTopModules()
def printCom(self, G):
self.findCommunities(G)
communities = collections.defaultdict(lambda: list())
for k, v in nx.get_node_attributes(G, 'community').items():
communities[v].append(k)
communitie_sort = sorted(communities.values(), key=lambda b: -len(b))
count = 0
for communitie in communitie_sort:
count += 1
print(f'社区{count},成员{communitie}', end='\n')
print(self.cal_Q(communities.values()))
def drawNetwork(self, G):
# position map
pos = nx.spring_layout(G)
# community ids
communities = [v for k, v in nx.get_node_attributes(G, 'community').items()]
numCommunities = max(communities) + 1
# color map from http://colorbrewer2.org/
cmapLight = colors.ListedColormap(['#a6cee3', '#b2df8a', '#fb9a99', '#fdbf6f', '#cab2d6'], 'indexed',
numCommunities)
cmapDark = colors.ListedColormap(['#1f78b4', '#33a02c', '#e31a1c', '#ff7f00', '#6a3d9a'], 'indexed',
numCommunities)
# Draw edges
nx.draw_networkx_edges(G, pos)
# Draw nodes
nodeCollection = nx.draw_networkx_nodes(G,
pos=pos,
node_color=communities,
cmap=cmapLight
)
# Set node border color to the darker shade
darkColors = [cmapDark(v) for v in communities]
nodeCollection.set_edgecolor(darkColors)
# Draw node labels
for n in G.nodes():
plt.annotate(n,
xy=pos[n],
textcoords='offset points',
horizontalalignment='center',
verticalalignment='center',
xytext=[0, 0],
color=cmapDark(communities[n - 1])
)
plt.axis('off')
plt.savefig("image1.png")
plt.show()
def cal_Q(self, partition): # 计算Q
m = len(self.graph.edges(None, False)) # 如果为真,则返回3元组(u、v、ddict)中的边缘属性dict。如果为false,则返回2元组(u,v)
# print(G.edges(None,False))
# print("=======6666666")
a = []
e = []
for community in partition: # 把每一个联通子图拿出来
t = 0.0
for node in community: # 找出联通子图的每一个顶点
t += len([x for x in self.graph.neighbors(node)]) # G.neighbors(node)找node节点的邻接节点
a.append(t / (2 * m))
# self.zidian[t/(2*m)]=community
for community in partition:
t = 0.0
for i in range(len(community)):
for j in range(len(community)):
if (self.graph.has_edge(community[i], community[j])):
t += 1.0
e.append(t / (2 * m))
q = 0.0
for ei, ai in zip(e, a):
q += (ei - ai ** 2)
return q
def visualize(self, G):
self.findCommunities(G)
self.drawNetwork(G)
obj = Graph()
# graph = nx.karate_club_graph()
# graph = obj.createGraph("data//google.txt")
graph = obj.createGraph("Data//OpenFlights.txt")
a = Infomap(graph)
# a.findCommunities(graph)
# a.visualize(graph)
a.printCom(graph)
数据代码下载:github

















 5149
5149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









