







网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
博主的思路是:
1.首先对服务器发送http请求。
2.对服务器的返回的html代码进行解析。(处理 <a href 标签> 并且对href的链接加入ArrayList中,再从ArrayList取出Url进行重复解析)。
代码的关键是就是进行Html进行解析,博主一开始是采用Dom解析html,经过大神指点,发现了Jsoup.jar包。Jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。因此对文档解析成了一件较为容易的事情。
核心代码:
try{
//获取参数内容
String url=urlrule.getUrl();
//Params Values比如
/*
* http://news.baidu.com/ns?cl=2&rn=20&tn=news&word=Java
params[]={"cl","rn","tn","word"};
values[]={"2","20","news","Java"}
*/
String[] params=urlrule.getParams();
String[] values=urlrule.getValues();
String resultTagName=urlrule.getResultTagName();
int type=urlrule.getType();
int httpmethod=urlrule.getHttpmethod();
//从一个网站获取和解析一个HTML文档,并查找其中的相关数据
Connection conn=(Connection) Jsoup.connect(url);
if( params !=null){
for(int i=0;i<params.length;i++){
conn.data(params[i], values[i]);
}
}
//设置请求方式
Document doc=null;
if(httpmethod==Weburl.GET){
try {
doc=conn.timeout(10000).get();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
else{
try {
doc=conn.timeout(10000).post();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//resultTagName Jsoup的解析html的方式 Jsoup的api提供了好多种函数接口
//处理返回数据对html的解析 可以根据<标签名 或者 类选择器 或者 ID选择器 或者 SELECTION>
Elements res=new Elements();
switch(type){
case Weburl.CLASS:
res=doc.getElementsByClass(resultTagName);
break;
case Weburl.ID:
Element r=doc.getElementById(resultTagName);
res.add(r);
break;
case Weburl.SELECTION:
res=doc.select(resultTagName);
break;
default:
if(TextUtil.isEmpty(resultTagName)){
//处理body标签
res=doc.getElementsByTag("body");
}
}
for(Element re:res){
Elements links=re.getElementsByTag("a");
for(Element link:links){
String linkhref=link.attr("href"); //取得链接地址
String linkText=link.text(); //取得链接地址的文本内容
data=new LinkTypeData(); //保存到ArrayList
data.setLinkHref(linkhref);
data.setLinkData(linkText);
dataslist.add(data);
}
}
}catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
Selector选择器概述(reslutTagName)
tagname: 通过标签查找元素,比如:ans|tag: 通过标签在命名空间查找元素,比如:可以用fb|name语法来查找<fb:name>元素#id: 通过ID查找元素,比如:#logo.class: 通过class名称查找元素,比如:.masthead[attribute]: 利用属性查找元素,比如:[href][^attr]: 利用属性名前缀来查找元素,比如:可以用[^data-]来查找带有HTML5 Dataset属性的元素[attr=value]: 利用属性值来查找元素,比如:[width=500][attr^=value],[attr$=value],[attr*=value]: 利用匹配属性值开头、结尾或包含属性值来查找元素,比如:[href*=/path/][attr~=regex]: 利用属性值匹配正则表达式来查找元素,比如:img[src~=(?i)\.(png|jpe?g)]*: 这个符号将匹配所有元素
Selector选择器组合使用
el#id: 元素+ID,比如:div#logoel.class: 元素+class,比如:div.mastheadel[attr]: 元素+class,比如:a[href]- 任意组合,比如:
a[href].highlight ancestor child: 查找某个元素下子元素,比如:可以用.body p查找在"body"元素下的所有p元素parent > child: 查找某个父元素下的直接子元素,比如:可以用div.content > p查找p元素,也可以用body > *查找body标签下所有直接子元素siblingA + siblingB: 查找在A元素之前第一个同级元素B,比如:div.head + divsiblingA ~ siblingX: 查找A元素之前的同级X元素,比如:h1 ~ pel, el, el:多个选择器组合,查找匹配任一选择器的唯一元素,例如:div.masthead, div.logo

可以看到在新闻标签中 mon=“ct=1&a=1" 如何我们想把这些新闻爬下来的话,只需要设置SELECTION选择器,[ mon*=ct=1&a=1&c=internet]
然后解析数据是就会把其他的标签内容忽略,只剩下我们想要内容的数据。
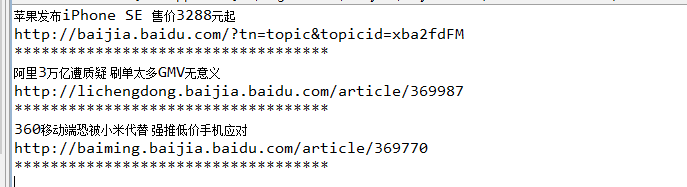
这样一个简单的网络爬虫数据就实现了。
Jsoup 1.7.3的中文文档下载地址:http://pan.baidu.com/s/1kUkIsy7















 3220
3220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









