









Abstract:
在大语言模型时代,混合专家(MoE)是一种很有前景的架构,可以实现在扩大模型参数时,同时对计算成本进行有效控制。然而,像GShard这样的传统MoE架构,它在N个专家(experts)中激活top-K个,其在专家专业化方面面临着挑战,每个专家要求获得不重叠和集中的知识。为此,我们提出了DeepSeekMoE架构,以实现最终的专家专业化。它涉及两个主要策略:(1)更精细地将划分为mN个专家并激活其中的mK个,从而激活的专家具有更灵活的组合;(2)将Ks个专家独立为共享专家,目的是提取专家的共同知识并减少冗余。从具有2B的模型参数开始,我们证明DeepSeekMoE 2B的性能可与具有1.5倍专家参数和计算量的GShard(2.9B模型参数)相媲美。此外,在总参数数相同的情况下,DeepSeekMoE 2B的性能接近于作为MoE模型的上界的稠密模型(dense counterpart)。随后,我们将DeepSeekMoE扩展到16B,并表明它性能达到了7B的LLaMA2,但DeepSeekMoE只有大约LLaMA2的40%的计算量。此外,我们将DeepSeekMoE扩展到145B的参数,验证其相对于GShard架构的实质性优势,并显示其性能与DeepSeek 67B相当,但计算量仅28.5%(甚至可能是18.2%)。
1. Introduction
最近的研究和实践经验表明,在有足够的训练数据的情况下,增加参数和计算预算,可以产生非常强大的语言模型。然而,必须承认的是,将模型扩张到非常大的话同时也伴随着极高的计算成本。考虑到大量计算成本,混合专家Mixture-of-Experts (MoE) 架构可以对参数量进行缩放,同时将计算成本保持在适度的水平。最近MoE架构在Transformers中的应用已经成功地尝试将语言模型扩展到相当大的模型参数规模,并具有卓越的表现。这些成就强调了MoE语言模型的巨大潜力和前景。
尽管MoE体系结构具有很大的潜力,但现有的MoE体系结构存在着知识混杂(knowledge hybridity)和知识冗余(knowledge redundancy)的问题,这限制了专家的专业化,即每个专家应拥有专注且互不重叠知识。传统的MoE架构用MoE层代替Transformer中的前馈网络(FFNs)。每个MoE层由多个专家组成,每个专家在结构上都与标准的FFN结构相同,每个token被分配给一个或两个专家。这个体系结构存在两个潜在问题:(1) 知识混合(Knowledge Hybridity):现有的MoE通常采用有限数量的专家(例如,8或16),分配给特定专家的token可能涵盖多种知识。因此,被分配到专家便会在其参数中汇集大量不同类型的知识,这些知识很难被同时利用。(2) 知识冗余(Knowledge Redundancy):分配到不同专家的token可能需要共同知识。因此,多个专家可能会在各自的参数中获取共享知识,从而导致专家参数的冗余。这些问题共同阻碍了现有MoE的专业化,使他们无法达到MoE模型的理论上限性能。
针对上述问题,我们推出了DeepSeekMoE,这是一种面向极致专业化的,创新的MoE架构。我们的体系结构涉及两个主要策略:(1) 细粒度专家分割(Fine-Grained Expert Segmentation):在保持参数数量不变的情况下,在FFN中间隐藏层,我们将专家分割成更细的粒度。在保持计算成本不变的情况下,我们激活更多细粒度的专家,以实现更灵活更强的激活专家组合。细粒度的专家实现将不同的知识更精细地分解,并更精确地学习到知识,从而每个专家将保持更高的专业化水平。此外,更灵活的激活专家组合,也有助于更准确和有针对性的知识获取。(2)共享专家隔离(Shared Expert Isolation):我们将某些专家隔离开作为共享专家并且这些专家是一直激活的,目的是在不同的上下文中捕获和融合共同知识。通过将共同知识提炼到这些共享的专家中。其他专家之间的冗余问题将被缓和。这样可以提高模型参数的效率,从而保证每个专家专注于不同的方面来保持专业化。这些DeepSeekMoE的创新为训练参数高效,每个专家都高度专业化的MoE语言模型提供了可能性。
从2B参数的模型开始,我们验证了DeepSeekMoE架构的优势。我们对12个零样本学习(zero-shot)或少量样本学习(few-shot)的跨越不同任务的基准进行评估。实证结果表明,DeepSeekMoE 2B大大优于GShard 2B,甚至与更大的MoE模型2.9B的GShard相媲美,其具有1.5倍专家参数及计算量。值得注意的是,我们发现在参数数量相等的情况下,DeepSeekMoE 2B的性能几乎接近MoE模型性能严格上界的密集型模型。为了获得更深入的了解,我们对DeepSeekMoE进行了消融实验,并分析其专家的专业化。这些研究验证了细粒度专家分割和共享专家隔离的有效性,并提供了经验证据,支持DeepSeekMoE可以实现高水平的专家专业化的断言。
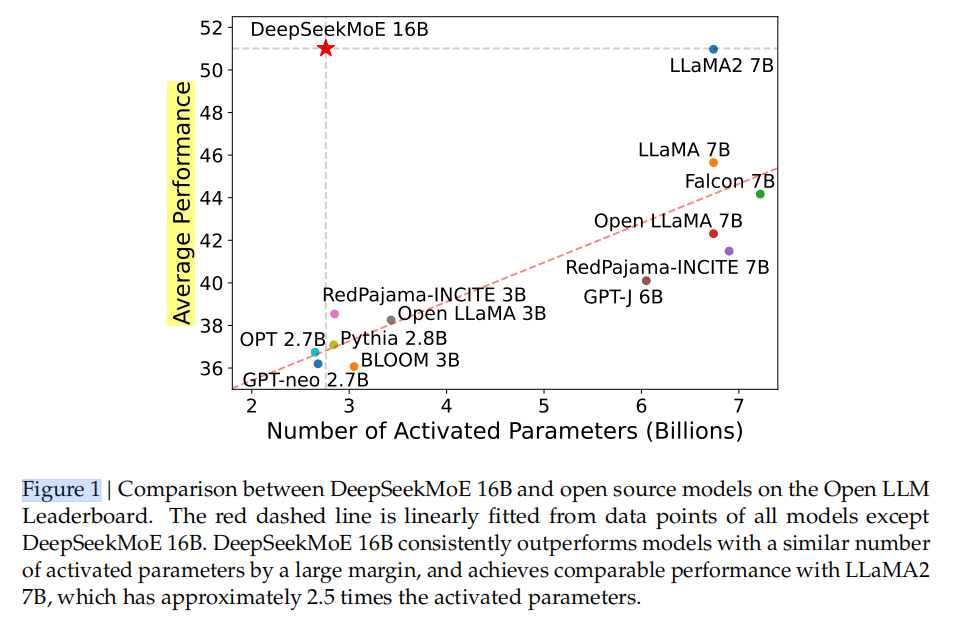
使用我们的架构,我们将模型参数扩展到16B,并在具有2T tokens的大规模语料库上进行训练。评估结果显示,DeepSeekMoE 16B只需要大约40%的计算,就可以达到与在相同的2T语料库上训练的密集模型DeepSeek 7B相当的性能。我们还将DeepSeekMoE与开源模型进行了比较,评估表明DeepSeekMoE 16B的性能始终远远优于具有相似激活参数数量的模型,并且与激活参数约为2.5倍的7B LLaMA2 的性能相当。图1展示了开源LLM评估结果的排行榜,此外,我们进行监督微调(SFT)进行对齐,将模型转换为聊天模型。评估结果表明,DeepSeekMoE Chat 16B也达到了与DeepSeek Chat 7B和LLaMA2 SFT 7B相当的性能。受这些结果的鼓舞,我们进一步将DeepSeekMoE扩展到145B。实验结果仍然一致地验证了其相对于GShard架构的实质性优势。此外,它表明了与DeepSeek 67B相当的性能,却只使用了28.5%(甚至可能是18.2%)的内存和计算量。
我们的贡献总结如下:
• Architectural Innovation. 我们介绍了DeepSeekMoE,一种创新的MoE架构,为了实现极致的专家专业化,它采用了细粒度专家分割和共享专家隔离两种主要策略。
• Empirical Validation. 我们进行了大量的实验,以经验验证DeepSeekMoE架构的有效性。实验结果验证了该方法在DeepSeekMoE 2B的专家专业化水平的有效性,并表明DeepSeekMoE 2B几乎可以接近MoE模型的上界性能。
• Scalability. 我们将DeepSeekMoE扩展到训练一个16B模型,并只需要大约40%的计算量,DeepSeekMoE 16B就可以达到与DeepSeek 7B和LLaMA2 7B的性能。我们也在做努力扩大模型DeepSeekMoE到145B,突出其相对GShard架构的一贯优势,并显示出与DeepSeek 67B相当的性能。
• Alignment for MoE. 我们成功地对DeepSeekMoE 16B进行有监督微调对齐,创建了一个聊天模型,展示了其适应性和功能的多样性。
• Public Release. 本着开源研究的精神,我们向公众发布了DeepSeekMoE 16B模型checkpoint。值得注意的是,该模型可以部署在具有40GB内存的单个GPU上,并且无需进行量化。
2. Preliminaries: Mixture-of-Experts for Transformers
我们首先介绍Transformer模型中常用的通用MoE体系结构。一个标准的Transformer模型是通过堆叠L层标准的Transformer blocks来构建的,其中每个Transformer blocks可以表示如下:
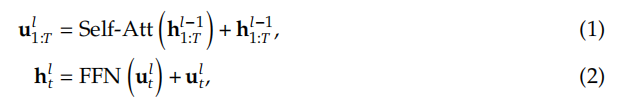
式中T为序列长度,Self-Att(·)为自注意模块(self-attention),FFN(·)为前馈网络(FFN), u1:T维度为T×d(序列长度T×特征向量维度d_model),其表示所有tokens经过attention模块后的隐藏层特征。ht'l维度为d,其表示经过第l个Transformer block之后第t个token的隐藏层特征。为简洁起见,我们在上述公式中省略了归一化层。
构建MoE模型的典型做法通常是在指定间隔内用MoE层替换Transformer中的FFNs。一个MoE层由多个专家组成,每个专家在结构上与标准FFN相同。然后,每个token将被分配给一个或两个专家。如果将第l层FFN替换为MoE层,则其输出隐藏状态h的计算可表示为:
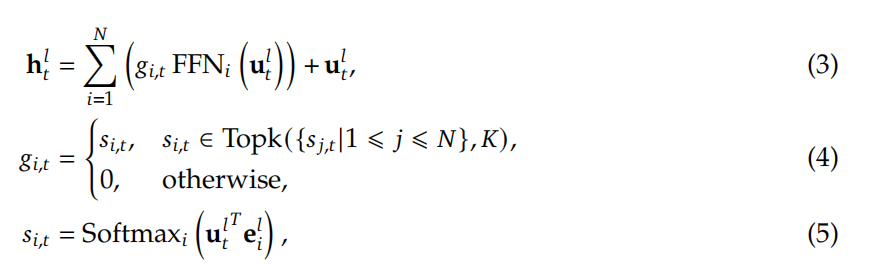
N表示专家的总数,FFNi(·)是第i个专家FFN,gi,t(t代表第t个token)表示第i个专家的门限值(gate value),si,t表示(第t个)token 跟(第i个)专家的匹配度,Topk(·𝐾)表示在N个专家里面,计算出与第t个token匹配值最高的K个专家,和ei'l表示第l层第i个专家的质心(centroid),值得注意的是,𝑔i,𝑡是稀疏的,这表明在N个值里,只有K个值是非零的。这种稀疏性确保了MoE层内的计算效率,即每个token将只分配给K个专家并进行计算。此外,在上述公式中,为了简洁起见,我们省略了层归一化操作。
3. DeepSeekMoE Architecture
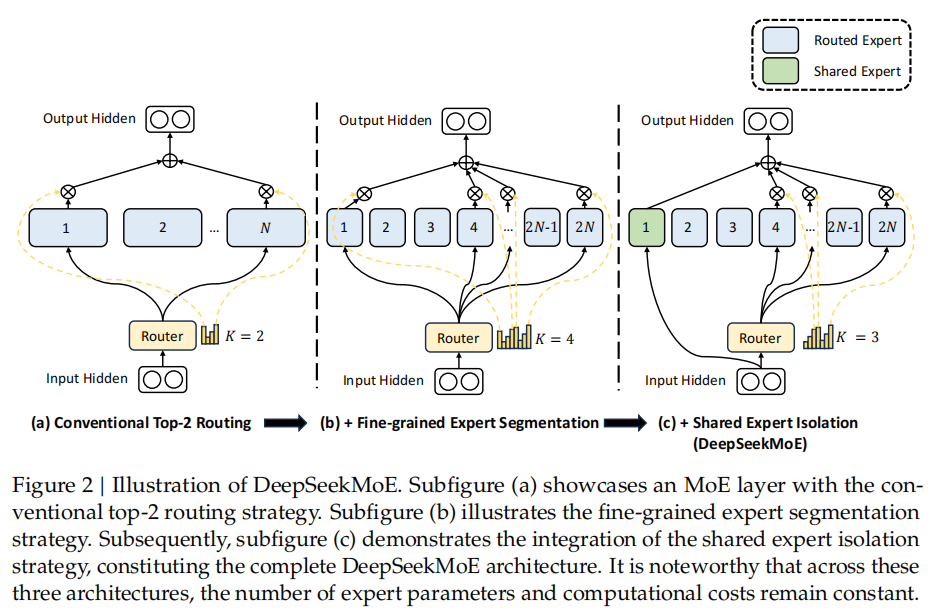
在第2节概述的通用MoE架构的基础上,我们介绍DeepSeekMoE,它是专门为挖掘专家专业化潜力而设计的。如图2所示,我们的结构包含两个主要策略:细粒度专家分割(fine-grained expert segmentation)和共享专家隔离(shared expert isolation)。这两种策略都旨在提高专家专业化水平。
3.1. Fine-Grained Expert Segmentation
在专家数量有限的情况下,分配给特定专家的token更有可能涵盖不同类型的知识。因此,指定的专家趋向在其参数中学习大量不同类型的知识,而这些知识很难同时被利用。然而,如果每个token可以分配给更多的专家,那么知识将更有可能被分解开并又不同的专家学习。在这种情况下,每个专家仍然可以保持高水平的专业化,有助于专家们实现更为集中的知识分布。
为了实现这一目标,在保持专家参数数量和计算成本一致的情况下,我们对专家进行了更细粒度的分割。更精细的专家分割使被选中激活的专家的组合更加灵活和更具适应性。具体来说,在图2(a)所示的典型MoE架构之上,我们通过将FFN中间隐藏维度降至1/m,将每个专家FFN划分为m个更小的专家。由于每个专家变得更小,因此,在保持相同计算量的情况下,我们也将激活专家的数量对比原来增加m倍。如图2(b)所示。细粒的专家分割,MoE层的输出可以表示为:
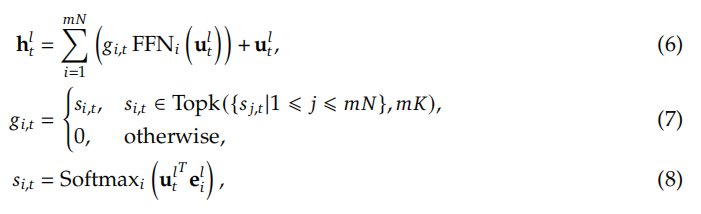
其中,专家参数总量等于标准前馈网络(FFN)参数量的N倍,并且mN代表细粒度专家的总数。采用细粒度专家分割策略,非零门限的数量也会增加到mK。
从组合的角度来看,细粒度专家分割策略大大提高了激活专家的组合灵活性。举个例子说明,我们考虑这样的情况:当N = 16时,典型的Top-2(选取2个专家模型激活)策略可以产生120中组合。相比之下,我们将每个专家切分成4个更小的专家,那么可以产生4426165368种组合。组合的灵活性增强了实现更准确和更有针对性的知识获取的潜力。
3.2. Shared Expert Isolation
对于传统的路由(routing)选择策略,分配给不同专家的token可能需要一些共同的知识或信息。因此,多个专家可能会在各自的参数中获取共享的知识,从而导致专家参数的冗余。然而,如果有共享的专家致力于在不同的上下文中捕获和整合公共知识,那么专家之间的参数冗余将得到缓解。这种冗余的减少将有助于生成更多参数效率更高的专业专家。
为了实现这一目标,除了细粒度专家分割策略外,我们进一步隔离开Ks个专家作为共享专家。无论路由模块如何选择,每个token牌都将被确定性的分配给这些共享的专家。为了保持计算成本,在其他专家中激活的专家数量将减少Ks个,如图2(c)所示。通过集成共享专家隔离策略,完整的DeepSeekMoE架构中的MoE层计算如下所示:
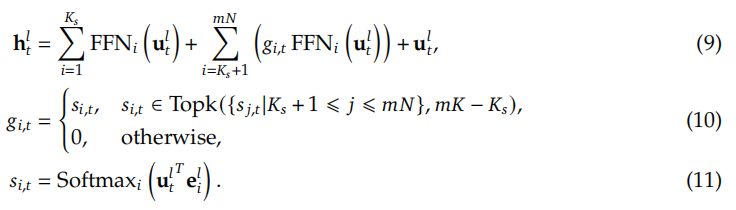
最后,DeepSeekMoE中,共享专家的数量为Ks,路由可选择的专家总数为mN - Ks,非零门限的个数为mK - Ks 。
值得注意的是,共享专家隔离的原型来源于Rajbhandari。关键的区别在于,他们是从工程学的角度推导出这个策略,而我们是从算法的角度来实现它。
3.3. Load Balance Consideration
自动学习路由选择策略(routing strategies)可能会遇到负载不平衡的问题,这表现出两个明显的缺陷。首先,存在路由选择崩溃的风险,即模型总是只选择少数专家,使其他专家无法得到充分的训练。其次,如果专家分布在多个设备上,负载不平衡会加剧计算瓶颈。
Expert-Level Balance Loss. 为了降低路由选择策略崩溃的风险,我们还引入一个专家层面(expert-level)的平衡损失函数。平衡损失函数计算如下:

其中α1是一个专家层面(expert-level)平衡因子的超参数,也就是N'等于(mN - Ks)和K'等于(mK - Ks),为了简介,1(·)表示指示函数(indicator function)。
Device-Level Balance Loss. 除了专家层面的平衡损失之外,我们还引入了设备层面(device level)的平衡损失函数。为了缓解计算瓶颈,在专家层面执行严格的平衡约束是不可取的,因为在专家层面对负载平衡的过多约束将损害模型性能。相反,我们的主要目标是确保跨设备的平衡计算。如果我们把所有路由可选择专家分成D组{ε1,ε2,....,εD},并且每组都部署在单个设备上,则设备层面均衡的损失函数计算如下:
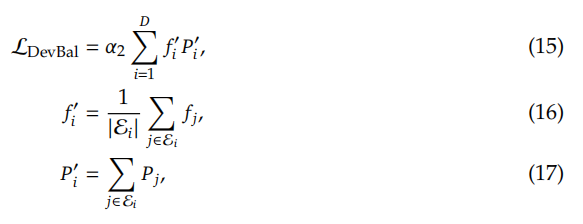
其中α2是一个设备层面平衡因子的超参数。在实践中,我们设置了较小的专家层面平衡因子来降低路由选择崩溃的风险,同时设置了较大的设备层面平衡因子来促进设备间的计算均衡。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











