







本篇文章是笔者学习《数据库系统概念》总结来的,主要介绍SQL的基本结构和概念。
SQL语言有以下几个部分:
- 数据定义语言(Data-Definition Language,DDL):SQL DDL提供定义关系模式、删除关系以及修改关系模式的命令。
- 数据操纵语言(Data-Manipulation Language,DML):SQL DML提供从数据库中查询信息,以及在数据库中插入元组、删除元组、修改元组的能力。
- 完整性(integrity):SQL DDL包括定义完整性约束的命令,保存在数据库中得数据必须满足所定义的完整性约束。破坏完整性约束的更新是不允许的。
- 视图定义(view definition):SQL DDL包括定义视图的命令。
- 事务控制(transaction control):SQL包括定义事务的开始和结束的命令。
- 授权(authorization):SQL DDL包括定义对关系和视图的访问权限的命令。
SQL数据定义
数据库中的关系集合必须由数据定义语言(DDL)指定给系统,SQL的DDL不仅能够定义一组关系,还能定义每个关系的信息。
Mysql支持多种类型,大致可以分为三类:数值、字符串和日期/时间类型。此处我们只介绍数值和字符串类型,日期/时间类型后面再做介绍。
| 类型 | 长度(字节) | 范围(有符号) | 范围(无符号) | 说明 |
|---|---|---|---|---|
| TINYINT | 1 | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 | (-32768,32767) | (0,65535) | 大整数值 |
| MADIUNINT | 3 | (-8388608,8388607) | (0,16777215) | 大整数值 |
| INT | 4 | (-2147483648,2147483647) | (0,4294967295) | 大整数值 |
| BIGINT | 8 | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | DECIMAL(M,D),占用M+2个字节 | 取决于M和D | 取决于M和D | M为小数点左边和右边可存储的十进制数字的最大个数,D为小数点右边可存储的十进制数字的最大个数 |
| 类型 | 长度(字节) | 说明 |
|---|---|---|
| CAHR | (0,255) | 定长字符串,例如属性A类型为char(10),存入字符串“AAA”,该字符串后会追加7个空格达到10个串长度 |
| VARCHAR | (0,65535) | 变长字符串,例如属性V类型为varchar(10),存入字符串“BBB”,不会增加空格 |
| TINYBLOB | (0,255) | 二进制字符串 |
| TINYTEXT | (0,255) | 短文本字符串 |
| BLOB | (0,65535) | 二进制的长文本数据 |
| TEXT | (0,65535) | 长文本数据 |
| MEDIUMBLOB | (0,16777215) | 二进制中等长度文本数据 |
| MEDIUMTEXT | (0,16777215) | 中等长度文本数据 |
| LONGBLOB | (0,4294967295) | 二进制极大文本数据 |
| LONGTEXT | (0,4294967295) | 极大文本数据 |
基本模式定义
使用create table命令定义SQL关系,create table命令的通用形式是:
CREATE TABLE r
(A1 D1,
A2 D2,
...,
<完整性约束>);
其中r是关系名,每个A是关系r模式中的属性名,D是属性A的域,也就是说D指定了属性A的类型以及可选的约束,用于限制所允许的A取值的集合。create table命令用分号结束,事实上所有的SQL命令都用分号结束。另外,SQL语言是不区分大小写的,但按照规范所有关系名或者属性名都是小写,关键字以及内置函数全部大写。
创建名为city的关系命令如下:
CREATE TABLE `city` (
`city_id` int(10),
`city_name` varchar(50),
`province_id` varchar(20),
`first_letter` varchar(20),
`is_hot` int(10),
`state` int(10),
PRIMARY KEY (`city_id`)
);上面创建的关系具有6个属性,city_id是一个10位的整数,city_name是最大长度为50的字符串,指明了city_id属性是city关系的主码。
SQL支持许多不同的完整性约束,此处我们只讨论以下几个:
- primary key(A1,A2,...,An):表示属性A1,A2,...,An构成关系的主码。主码属性必须非空且唯一,也就是说没有一个元组在主码属性上取空值,关系中也没有两个元组在所有主码属性上取值相同。虽然主码的声明是可选的,但为每个关系指定一个主码通常会更好。
- foreign key(A1,A2,...,An)references s:表示关系中任意元组在属性(A1,A2,...,An)上的取值必须对应于关系s中某元组在主码属性上的取值。
- not null:一个属性上的not null约束表明在该属性上不允许空值,即此约束把空值排除在该属性域之外。
SQL禁止破坏完整性约束的任何数据库更新。例如,如果关系中一条新插入或新修改的元组在任意一个主码属性上有空值,或者元组在主码属性上的取值与关系中的另一个元组相同,SQL将标记一个错误并阻止更新。类似的,对于foreign key(A1,A2,...,An)references s,如果插入一个在属性(A1,A2,...,An)上的取值没有出现在关系s中,就会破坏外码约束,SQL会阻止这种插入。
一个新创建的关系最初是空的,我们可以用insert命令将数据加载到关系中。例如向上面新创建的city关系插入一个元组,city_id为000000,city_name为纽约,province_id为110000,first_letter为ny,is_hot为0,state为1,则这条insert命令可以这样写:
INSERT INTO city VALUES(000000,'NewYork',110000,'ny',0,1);值被给出的顺序应该遵循对应属性在关系模式中列出的顺序。
我们可以使用delete命令从关系中删除元组,例如下面的SQL将会删除city关系中的所有元组。
DELETE FROM city;如果要从SQL数据库中删除一个关系,我们使用drop table命令,drop tablea命令从数据库中删除关于被删除关系的所有信息。
DROP TABLE city;命令drop table是比delete from更强的语句,后者删除了city关系中的所有元组但保留了city关系,前者不仅删除了city关系中的所有元组还删除了city关系。
我们使用alter table命令为已有关系增加属性,关系中的所有元组在新属性上的取值将被设为null,alter table命令的格式为:
ALTER TABLE r ADD A D;其中r是现有关系的名字,A是待添加属性的名字,D是待添加属性的域。例如为关系city添加属性grate,域为int(1),命令如下:
ALTER TABLE city ADD grade int(1);我们也可以使用以下命令从关系中删除属性:
ALTER TABLE r DROP A;其中r是现有关系的名字,A是关系的一个属性的名字。例如删除关系city中名为grade的属性的命令如下:
ALTER TABLE city DROP grade;SQL查询的基本结构
SQL查询的基本结构由三个子句构成:select、from和where。查询的输入是在from子句中列出的关系,在这些关系上进行where和select子句中指定的运算,然后产生一个关系作为结果。
先介绍我们稍后会使用的三个关系模式,分别为region,city,province。
region(region_id,region_name,city_id)
city(city_id,city_name,province_id,first_letter,is_hot,state)
province(province_id,province_name)单关系查询
我们用city关系的一个简单查询:“找出所有城市的名字”。city关系放在from子句中,城市的名字即city_name属性,因此把它放在select子句中,最终命令如下:
SELECT city_name FROM city;其结果是由属性名为city_name的单个属性构成的关系。查询结果如图(下左一):

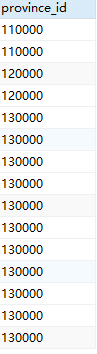
另一个查询:“找出所有城市所属的省份”,此查询的命令如下:
SELECT province_id FROM city;查询结果如图(上左二),因为一个省份有多个城市,所以在city关系中,province_id可以出现多次。
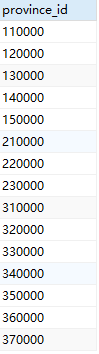
在关系模型的形式化数学定义中,关系是一个集合,因此重复的元组不应该出现在关系中。在实践中,去除重复是相当费时的,所以SQL允许在关系以及SQL表达式结果中出现重复。因此,在上述SQL查询中,每个province_id在city关系中的元组中没出现一次,都会在查询结果中列出一次。我们如果想强行删除重复,可以在select命令后加入关键词distinct,例如上面的查询中去除重复的province_id的语句为:
SELECT DISTINCT province_id FROM city;查询结果如图(上左三),可以看到与图(上左二)有差别,province_id只出现一次。
select子句还可带有+、-、*、/运算符的算术表达式,运算对象可以是常数或元组的属性,例如以下查询
SELECT city_id,city_name,province_id * 2 FROM city;查询结果如图(下左一)将province_id的值*2,但关系city的province_id属性并没有任何改变。
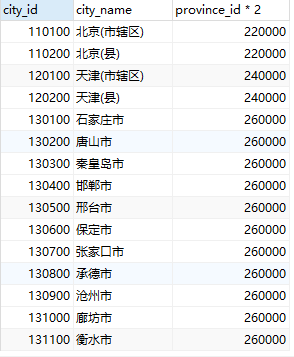
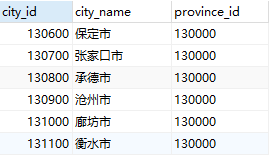
where子句允许我们只选出那些在from子句的结果挂你想中满足特定谓词的元组。例如查询:“找出所有在city关系中province_de为130000且ciry_id大于130500的城市名称”,该查询的SQL如下:
SELECT city_id,city_name,province_id FROM city WHERE province_id = 130000 AND city_id > 130500;查询结果如图(上左二)。SQL允许在where子句中使用逻辑连词and、or和not,逻辑连词的运算对象可以是包含比较运算符<、<=、>、>=、=和<>的表达式。SQL允许我们使用比较运算符来比较字符串、算术表达式以及特殊类型,例如日期类型。
多关系查询
目前为止我们的查询示例都是基于单个关系的,通过查询需要从多个关系中获取信息,下面来学习如何书写这样的查询。
我们现在想要这样的查询:“找出所有城市的名称,以及他们所属的省份id和省份名称”。在关系city中我们可以很简单的查找到城市名称以及他们所属的省份,但省份名称在province表中。因此city关系中的每个元组必须与province关系中的元组匹配,后者在province_id上的取值相配与city在province_id上的取值。最终的SQL语句如下:
SELECT city_name,city.province_id,province.province_name
FROM city,province
WHERE city.province_id = province.province_id;查询结果如图(下左一),由于province_id即出现在city关系中又出现在province关系中,因此在SQL中用关系名作为前缀来说明我们使用的是哪个属性。


多个关系的SQL查询包括三种类型的子句:
- select子句:用于列出查询结果中所需要的属性;
- from子句:列出查询求值中需要访问的关系列表;
- where子句:作用在from子句中关系的属性上的谓词。
如果省略where子句,则谓词为true,from语句定义了一个在该子句中所列关系上的笛卡尔积。例如上面的查询去掉where子句的查询结果如图(上左二),截图中的数据较少,但还是可以看的出来笛卡尔积把city关系中的每个元组与province关系中的每个元组组合了。很明显北京市只属于北京市,与其他省份无关,这样的数据是没有意义的。因此需要where子句中的谓词来限制笛卡尔积所建立的组合,只留下对所需答案有意义的组合。对于上面的查询,city关系中的province_id与province关系中的province_id相匹配时,他们的组合才是我们需要的答案。
对于多关系查询,一个SQL查询的含义可以理解如下:
- 在from子句中列出的关系产生笛卡尔积;
- 在步骤1的结果上应用where子句中指定的谓词;
- 对于步骤2产生的每个元组,输出select子句中指定的属性或表达式的结果。
但上述步骤的顺序只是有助于我们明白一个SQL查询的结果应该是怎样的,在SQL的实际实现中不会执行这种形式的查询,它会尽可能只产生满足where子句谓词的笛卡尔积来优化执行。
自然连接
在上面的查询示例中,需要从city关系和province关系中组合信息,匹配条件是city关系中的province_id属性等于province关系中的province_id属性。事实上from子句中的匹配条件在最通常的情况下需要在所有匹配名称的属性上相等。为了简化这种通用情况下SQL编程者的工作,SQL提供一种被称作自然连接的运算。
自然连接(natural join)运算作用于两个关系,并产生一个关系作为结果。与笛卡尔积不同的是,自然连接只考虑那些在两个关系模式中都出现的属性上取值相同的元组对。例如city关系和province关系,自然连接只考虑在它们相同的属性province_id上的取值相同的元组。
在多关系查询中的示例查询:“找出所有城市的名称,以及他们所属的省份id和省份名称”,用自然连接运算实现更简单:
SELECT city_name,city.province_id,province.province_name
FROM city NATURAL JOIN province;查询结果与多关系查询中的查询结果一致。
在from子句中,可以用自然连接将多个关系结合在一起,例如:
SELECT A1,A2,...,An
FROM r1 NATURAL JOIN r2 NATURAL JOIN ... NATURAL JOIN rn
WHERE P;为了让读者注意到自然连接的问题,在region关系中添加一个名称为province_name的属性,关系中所有元组的该属性值为null。现在我们想要这样一个查询:“找出所有的区名称,以及他们所属的城市名称和省份名称”,使用自然连接的语句如下:
SELECT region_name,city_id,city_name,province.province_name
FROM region NATURAL JOIN city NATURAL JOIN province;查询结果如图(下左一),生成的关系中没有一个元组,与我们预期的似乎有些不符。原因在于自然连接会考虑两个关系模式中都出现的属性在取值上相同的元组对,region关系和city关系自然连接后的属性包括region(region_id,region_name,city_id,province_name,city_name,province_id,first_letter,is_hot,state),而province关系包含的属性包括(province_id,province_name),作为这两者自然连接的结果,需要来自这两个输入的元组既要在province_id上取值相同,又要在province_name上取值相同。
我们想要的是region关系和city关系自然连接,产生的关系的province_id与province关系的province_id相同即可,province_name属性取值不需相同。下面的SQL即可满足此查询要求。
SELECT region_name,city_name,province.province_name
FROM region NATURAL JOIN city,province
WHERE city.province_id = province.province_id;查询结果如图(下左二)。
![]()

事实上,为了发扬自然连接的优点,同时避免不必要的相等属性带来的危险,SQL提供了一种自然连接的构造形式,允许用户来指定那些列需要相等,用这种方式完成上面的查询的SQL如下:
SELECT region_name,city_id,city_name,province.province_name
FROM (region NATURAL JOIN city) JOIN province USING(province_id);查询结果与图(上左二)相同。join...using运算需要给定一个属性名列表,其两个输入中都必须具有指定名称的属性。这样的连接构造允许region关系中的province_name与province关系中的province_name是不同的。
附加的基本运算
更名运算
在上面的多关系查询中,查询结果的属性名来自于from子句中关系的属性名,但有些情况我们不能用这种方法派生的名字,原因如下:
- from子句的两个关系可能存在同名属性,这种情况就会出现重复的属性名;
- 如果在select子句中使用算术表达式,那么在结果中该属性就没有名称;
- 有时我们需要重命名在查询的结果的属性。
因此,SQL提供了一个重命名结果关系中属性的方法,即使用as子句:
old_name AS new_nameas子句既可以出现在select子句中,也可以出现在from子句中。例如我们用name来代替city_name,想用c来代替city,用p来代替province,那么查询:“找出所有城市的名称,以及他们所属的省份id和省份名称”,可以用如下SQL语句完成:
SELECT city_name AS name,c.province_id,p.province_name
FROM city AS c NATURAL JOIN province AS p;查询结果如图(下左一),查询结果中的city_name被重命名成了name。像c和p那样被用来重命名关系的标识符在SQL标准中被称作相关名称(correlation name),通常也被称作表别名(table alias),或者相关变量(correlation variable),或者元组变量(tuple variable)。

字符串运算
SQL使用一对单引号来标示字符串,例如'hello'。如果单引号是字符串的组成部分,那就用两个单引号字符来表示,如字符串'it's right'可表示为'it"s right'。
在SQL标准中,字符串上的相等运算是大小写敏感的,所以表达式“'S'=='s'”的结果是假。但一些数据库例如MySQL,在匹配字符串时并不区分大小写。
SQL还允许在字符串上有多种函数,MySQL的字符串函数如下:
- LOWER(column | str):将字符串参数转换为小写后返回或者将某一列属性转换为小写后返回,例如:
//将字符串转换为小写然后返回 SELECT LOWER('HELLO'); //将某个属性转换为小写然后返回 SELECT LOWER(first_letter) FROM city; -
UPPER(column | str):将字符串参数转换为大写后返回或将某一列属性转换为大写后返回,例如:
//将字符串转换为大写然后返回 SELECT UPPER('HELLO'); //将某个属性转换为大写然后返回 SELECT UPPER(first_letter) FROM city; -
CONCAT(column1 | str1,column2 | str2, ...):将多个字符串参数或属性首尾相连后返回。如果某个参数为null,则函数返回null;如果参数是数字,自动转换为字符串。例如:
SELECT CONCAT('hello',' ',city_name,' ',first_letter) FROM city; -
CONCAT_WS(separator,str1,str2,...):将多个字符串以给定的分隔符separator首尾相连后返回,如果某个参数为null,则忽略null;如果参数是数字,自动转换为字符串。例如:
SELECT CONCAT_WS(' || ','hello',city_name,city_id) FROM city; -
SUBSTR(str,pos,len):与SUBSTRING函数相同,从字符串str的pos位置截取len个字符。len可以省略,省略时取到字符串结尾,len为负数表示从字符串的尾部开始截取。第一个字符的位置为1,不是0。例如:
SELECT SUBSTRING('hello world',5); 输出结果:0 world SELECT SUBSTRING('hello world',5,4); 输出结果:o wo SELECT SUBSTRING('hello world',-4); 输出结果:orld -
LENGTH(column | str):返回某个属性或字符串的长度。例如:
//输出结果为所有元组的first_letter的属性的长度 SELECT LENGTH(first_letter) FROM city; //输出结果为字符串长度,结果为5 SELECT LENGTH('hello'); //输出结果为字符串长度,结果为6。汉字的长度取决于字符集,utf8是6,gbk是4 SELECT LENGTH('你好'); -
CHAR_LENGTH(column | str):返回某个属性或字符串的字符个数。例如:
//输出结果为所有元组的first_letter的属性的字符 SELECT CHAR_LENGTH(first_letter) FROM city; //输出结果为字符串的字符个数 SELECT CHAR_LENGTH('hello'); //输出结果为字符串长度,结果为2。汉字,数字和字母都算一个字符 SELECT CHAR_LENGTH('你好'); -
INSTR(column | str,column | substr):返回substr或某个属性值在str或某个属性值中第一次出现的位置。例如:
//返回province_id从第3个字符开始的两个字符在city_id中第一次出现的位置 SELECT INSTR(city_id,SUBSTR(province_id,3,2)) FROM city; -
LPAD(str,len,padstr):在str的左边填充padstr直到长度达到len,返回填充后的字符串。例如:
SELECT LPAD('China',20,'hello'); 输出结果:hellohellohelloChina SELECT LPAD('China',7,'hello'); 输出结果:heChina SELECT LPAD('China',3,'hello'); 输出结果:Chi -
RPAD(str,len,padstr):在str的右边填充padstr直到长度达到len,返回填充后的字符串。例如:
SELECT RPAD('China',20,'hello'); 输出结果:Chinahellohellohello SELECT RPAD('China',7,'hello'); 输出结果:Chinahe SELECT RPAD('China',3,'hello'); 输出结果:Chi -
TRIM([{BOTH | LEADING | TRAILING} [removeStr] FROM] str):从str中去掉两端、 前缀或后缀的指定字符串。如果没有指定removeStr,默认去掉空格;如果没有指定BOTH、LEADING或TRAILING,默认为BOTH。例如:
//不指定removeStr,默认去掉字符串两端的空格 SELECT TRIM(' hello '); 输出结果:hello //去掉指定字符串前缀空格 SELECT TRIM(LEADING FROM ' hello '); 输出结果:hello(空格空格) //去掉指定字符串后缀空格 SELECT TRIM(TRAILING FROM ' hello '); 输出结果: hello //去掉指定字符串后缀指定子字符串 SELECT TRIM(TRAILING 'lo' FROM ' hello'); 输出结果: hel //去掉指定字符串前缀指定字符串 SELECT TRIM(LEADING 'he' FROM 'hello'); 输出结果:llo -
REPLACE(str,fromStr,toStr):在字符串str中查找全部的子字符串fromStr并替换为toStr。例如:
SELECT REPLACE('10101','1','*****'); 输出结果:*****0*****0***** -
LTRIM(str),RTRIM(str):去掉字符串左端或右端空格。例如:
//删除字符串左端空格 SELECT LTRIM(' hello '); 输出结果:hello(空格空格空格) //删除字符串右端空格 SELECT RTRIM(' hello '); 输出结果: hello -
REPEAT(str,count):将字符串str重复输出count次。例如:
SELECT REPEAT('hello',4); 输出结果:hellohellohellohello -
REVERSE(str):将字符串str反转后返回。例如
SELECT REVERSE('hello'); 输出结果:olleh -
SPACE(count):返回由count个空格组成的字符串。例如:
SELECT SPACE(5); 输出结果:空格空格空格空格空格 -
LEFT(str,len):返回字符串str最左边的len个字符。例如:
SELECT LEFT('hello',4); 输出结果:hell -
RIGHT(str,len):返回字符串str最右边的len个字符。例如:
SELECT RIGHT('hello',4); 输出结果:ello -
STRCMP(str1,str2):比较字符串str1和str2,如果两个字符串相同则返回0;如果str1小于str2则返回-1;如果str1大于str2则返回1。例如:
//字符串相同返回0 SELECT STRCMP('abcd','abcd'); 输出结果:0 //第一个字符串小于第二个字符串返回-1 SELECT STRCMP('abcde','accd'); 输出结果:-1 //第一个字符串大于第二个字符串返回1 SELECT STRCMP('dbcde','accd'); 输出结果:1
在字符串上还可以使用LIKE操作粗来实现模式匹配,我们用两个特殊的字符来描述模式:
- %:匹配任意子串。
- _:匹配任意一个字符。
'hello%':匹配任何以“hello”开头的字符串
'%hello%':匹配任何包含“hello”的字符串
'___':匹配包含三个字符的字符串
'___%':匹配至少包含三个字符的字符串例如:“找出城市名称中包含'京'字的城市id和城市名称”,SQL如下:
SELECT city_id,city_name FROM city WHERE city_name LIKE '%京%';类似的,还可以使用not like,例如:“找出城市名称中不包含'京'字的城市id和城市名称”,SQL如下:
SELECT city_id,city_name FROM city WHERE city_name NOT LIKE '%京%';select子句中的属性说明
星号“*”可以用在select子句中表示“所有的属性”,如下查询的select子句表示city关系中的所有属性都被选中:
SELECT * FROM city;排列元组的显示次序
order by子句可以让查询结果中元组按排列顺序显示。例如:“按first_letter的字母顺序排列city关系数据”,SQL如下:
SELECT * FROM city ORDER BY first_letter;order by子句默认使用升序,要说明顺序,可以用desc表示降序,或用asc表示升序。例如:“按first_letter的字母降序,city_name升序排列city关系数据”,SQL如下:
SELECT * FROM city ORDER BY first_letter DESC,city_name ASC;where子句谓词
为了简化where子句,SQL提供between比较运算符来说明一个值是小于或等于某个值,同时大于或等于另一个值。例如我们想找出city_id大于等于130100且小于130400的城市信息,以下两个SQL语句作用是相同的:
SELECT * FROM city WHERE city_id BETWEEN 130100 AND 130400;
SELECT * FROM city WHERE city_id >= 130100 AND city_id <= 130400;类似的,我们还可以使用not between运算符。例如我们想找出city_id小于130100且大于130400的城市信息,以下两个SQL语句作用是相同的:
SELECT * FROM city WHERE city_id NOT BETWEEN 130100 AND 130400;
SELECT * FROM city WHERE city_id < 130100 OR city_id > 130400;















 716
716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









